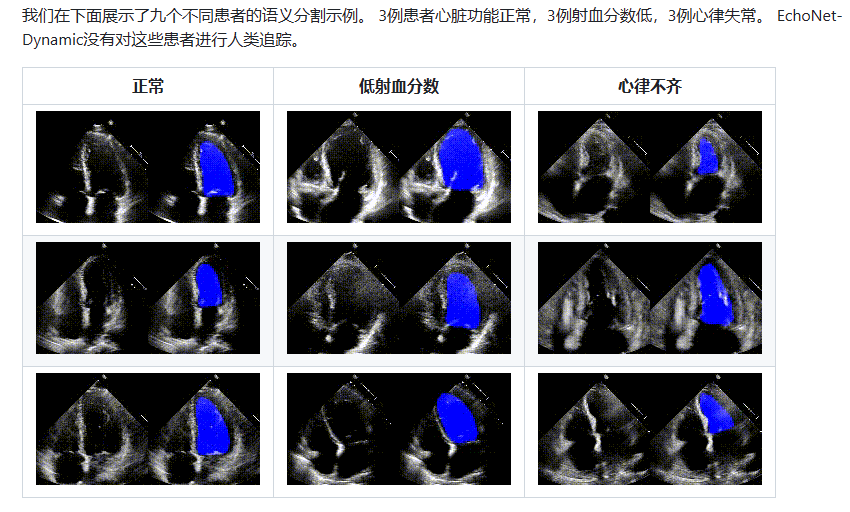
基于deeplab的心脏视频数据诊断分析
核心代码 segmentation.py:


"""Functions for training and running segmentation.""" import math import os import time import matplotlib.pyplot as plt import numpy as np import scipy.signal import skimage.draw import torch import torchvision import tqdm import os,sys parentdir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.insert(0,parentdir) #import echonet import utils from datasets import echo def run(num_epochs=50, modelname="deeplabv3_resnet50", pretrained=False, output=None, device=None, n_train_patients=None, num_workers=0, batch_size=20, seed=0, lr_step_period=None, save_segmentation=True, block_size=256, run_test=False): """Trains/tests segmentation model. Args: num_epochs (int, optional): Number of epochs during training Defaults to 50. modelname (str, optional): Name of segmentation model. One of ``deeplabv3_resnet50'', ``deeplabv3_resnet101'', ``fcn_resnet50'', or ``fcn_resnet101'' (options are torchvision.models.segmentation.<modelname>) Defaults to ``deeplabv3_resnet50''. pretrained (bool, optional): Whether to use pretrained weights for model Defaults to False. output (str or None, optional): Name of directory to place outputs Defaults to None (replaced by output/segmentation/<modelname>_<pretrained/random>/). device (str or None, optional): Name of device to run on. See https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.device for options. If ``None'', defaults to ``cuda'' if available, and ``cpu'' otherwise. Defaults to ``None''. n_train_patients (str or None, optional): Number of training patients. Used to ablations on number of training patients. If ``None'', all patients used. Defaults to ``None''. num_workers (int, optional): how many subprocesses to use for data loading. If 0, the data will be loaded in the main process. Defaults to 4. batch_size (int, optional): how many samples per batch to load Defaults to 20. seed (int, optional): Seed for random number generator. Defaults to 0. lr_step_period (int or None, optional): Period of learning rate decay (learning rate is decayed by a multiplicative factor of 0.1) If ``None'', learning rate is not decayed. Defaults to ``None''. save_segmentation (bool, optional): Whether to save videos with segmentations. Defaults to False. block_size (int, optional): Number of frames to segment simultaneously when saving videos with segmentation (this is used to adjust the memory usage on GPU; decrease this is GPU memory issues occur). Defaults to 1024. run_test (bool, optional): Whether or not to run on test. Defaults to False. """ # Seed RNGs np.random.seed(seed) torch.manual_seed(seed) # Set default output directory if output is None: output = os.path.join("output", "segmentation", "{}_{}".format(modelname, "pretrained" if pretrained else "random")) os.makedirs(output, exist_ok=True) # Set device for computations if device is None: device = "cuda" if torch.cuda.is_available() else "cpu" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Set up model model = torchvision.models.segmentation.__dict__[modelname](pretrained=pretrained, aux_loss=False) model.classifier[-1] = torch.nn.Conv2d(model.classifier[-1].in_channels, 1, kernel_size=model.classifier[-1].kernel_size) # change number of outputs to 1 if device.type == "cuda": model = torch.nn.DataParallel(model) model.to(device) # Set up optimizer optim = torch.optim.SGD(model.parameters(), lr=1e-5, momentum=0.9) if lr_step_period is None: lr_step_period = math.inf scheduler = torch.optim.lr_scheduler.StepLR(optim, lr_step_period) # Compute mean and std #mean, std = echonet.utils.get_mean_and_std(echonet.datasets.Echo(split="train")) mean, std = utils.get_mean_and_std(echo.Echo(split="train")) tasks = ["LargeFrame", "SmallFrame", "LargeTrace", "SmallTrace"] kwargs = {"target_type": tasks, "mean": mean, "std": std } # Set up datasets and dataloaders train_dataset = echo.Echo(split="train", **kwargs) if n_train_patients is not None and len(train_dataset) > n_train_patients: # Subsample patients (used for ablation experiment) indices = np.random.choice(len(train_dataset), n_train_patients, replace=False) train_dataset = torch.utils.data.Subset(train_dataset, indices) train_dataloader = torch.utils.data.DataLoader( train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda"), drop_last=True) val_dataloader = torch.utils.data.DataLoader( echo.Echo(split="val", **kwargs), batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda")) dataloaders = {'train': train_dataloader, 'val': val_dataloader} # Run training and testing loops with open(os.path.join(output, "log.csv"), "a") as f: epoch_resume = 0 bestLoss = float("inf") try: # Attempt to load checkpoint checkpoint = torch.load(os.path.join(output, "checkpoint.pt")) model.load_state_dict(checkpoint['state_dict']) optim.load_state_dict(checkpoint['opt_dict']) scheduler.load_state_dict(checkpoint['scheduler_dict']) epoch_resume = checkpoint["epoch"] + 1 bestLoss = checkpoint["best_loss"] f.write("Resuming from epoch {}\n".format(epoch_resume)) except FileNotFoundError: f.write("Starting run from scratch\n") for epoch in range(epoch_resume, num_epochs): print("Epoch #{}".format(epoch), flush=True) for phase in ['train', 'val']: start_time = time.time() for i in range(torch.cuda.device_count()): torch.cuda.reset_max_memory_allocated(i) torch.cuda.reset_max_memory_cached(i) loss, large_inter, large_union, small_inter, small_union = run_epoch(model, dataloaders[phase], phase == "train", optim, device) overall_dice = 2 * (large_inter.sum() + small_inter.sum()) / (large_union.sum() + large_inter.sum() + small_union.sum() + small_inter.sum()) large_dice = 2 * large_inter.sum() / (large_union.sum() + large_inter.sum()) small_dice = 2 * small_inter.sum() / (small_union.sum() + small_inter.sum()) f.write("{},{},{},{},{},{},{},{},{},{},{}\n".format(epoch, phase, loss, overall_dice, large_dice, small_dice, time.time() - start_time, large_inter.size, sum(torch.cuda.max_memory_allocated() for i in range(torch.cuda.device_count())), sum(torch.cuda.max_memory_cached() for i in range(torch.cuda.device_count())), batch_size)) f.flush() scheduler.step() # Save checkpoint save = { 'epoch': epoch, 'state_dict': model.state_dict(), 'best_loss': bestLoss, 'loss': loss, 'opt_dict': optim.state_dict(), 'scheduler_dict': scheduler.state_dict(), } torch.save(save, os.path.join(output, "checkpoint.pt")) if loss < bestLoss: torch.save(save, os.path.join(output, "best.pt")) bestLoss = loss # Load best weights checkpoint = torch.load(os.path.join(output, "best.pt")) model.load_state_dict(checkpoint['state_dict']) f.write("Best validation loss {} from epoch {}\n".format(checkpoint["loss"], checkpoint["epoch"])) if run_test: # Run on validation and test for split in ["val", "test"]: dataset = echo.Echo(split=split, **kwargs) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False, pin_memory=(device.type == "cuda")) loss, large_inter, large_union, small_inter, small_union = echonet.utils.segmentation.run_epoch(model, dataloader, False, None, device) overall_dice = 2 * (large_inter + small_inter) / (large_union + large_inter + small_union + small_inter) large_dice = 2 * large_inter / (large_union + large_inter) small_dice = 2 * small_inter / (small_union + small_inter) with open(os.path.join(output, "{}_dice.csv".format(split)), "w") as g: g.write("Filename, Overall, Large, Small\n") for (filename, overall, large, small) in zip(dataset.fnames, overall_dice, large_dice, small_dice): g.write("{},{},{},{}\n".format(filename, overall, large, small)) f.write("{} dice (overall): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(np.concatenate((large_inter, small_inter)), np.concatenate((large_union, small_union)), echonet.utils.dice_similarity_coefficient))) f.write("{} dice (large): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(large_inter, large_union, echonet.utils.dice_similarity_coefficient))) f.write("{} dice (small): {:.4f} ({:.4f} - {:.4f})\n".format(split, *echonet.utils.bootstrap(small_inter, small_union, echonet.utils.dice_similarity_coefficient))) f.flush() # Saving videos with segmentations dataset = echo.Echo(split="test", target_type=["Filename", "LargeIndex", "SmallIndex"], # Need filename for saving, and human-selected frames to annotate mean=mean, std=std, # Normalization length=None, max_length=None, period=1 # Take all frames ) dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, num_workers=num_workers, shuffle=False, pin_memory=False, collate_fn=_video_collate_fn) # Save videos with segmentation if save_segmentation and not all([os.path.isfile(os.path.join(output, "videos", f)) for f in dataloader.dataset.fnames]): # Only run if missing videos model.eval() os.makedirs(os.path.join(output, "videos"), exist_ok=True) os.makedirs(os.path.join(output, "size"), exist_ok=True) utils.latexify() with torch.no_grad(): with open(os.path.join(output, "size.csv"), "w") as g: g.write("Filename,Frame,Size,HumanLarge,HumanSmall,ComputerSmall\n") test_number = 1 for (x, (filenames, large_index, small_index), length) in tqdm.tqdm(dataloader): # Run segmentation model on blocks of frames one-by-one # The whole concatenated video may be too long to run together #print(x.shape) #for i in range(0, x.shape[0], block_size): # temp = model(x[i:(i + block_size), :, :, :].to(device))["out"].detach().cpu().numpy() if test_number > 10: break # 视频如果较长的话,得分段预测,然后将预测结果拼接起来 y = np.concatenate([model(x[i:(i + block_size), :, :, :].to(device))["out"].detach().cpu().numpy() for i in range(0, x.shape[0], block_size)]) print('输入:',x.shape) print('输出:',y.shape) test_number += 1 start = 0 x = x.numpy() for (i, (filename, offset)) in enumerate(zip(filenames, length)):#取到当前的数据(视频)和其对应的标签 # Extract one video and segmentation predictions video = x[start:(start + offset), ...] logit = y[start:(start + offset), 0, :, :] # Un-normalize video video *= std.reshape(1, 3, 1, 1) video += mean.reshape(1, 3, 1, 1) # Get frames, channels, height, and width f, c, h, w = video.shape # pylint: disable=W0612 assert c == 3 # Put two copies of the video side by side video = np.concatenate((video, video), 3) # If a pixel is in the segmentation, saturate blue channel # Leave alone otherwise video[:, 0, :, w:] = np.maximum(255. * (logit > 0), video[:, 0, :, w:]) # pylint: disable=E1111 逐位比较选最大值 # Add blank canvas under pair of videos video = np.concatenate((video, np.zeros_like(video)), 2) #下面还要画一些东西 # Compute size of segmentation per frame size = (logit > 0).sum((1, 2)) # Identify systole frames with peak detection trim_min = sorted(size)[round(len(size) ** 0.05)] #小峰值 trim_max = sorted(size)[round(len(size) ** 0.95)] #大峰值 trim_range = trim_max - trim_min systole = set(scipy.signal.find_peaks(-size, distance=20, prominence=(0.50 * trim_range))[0])#返回峰值的X坐标 # Write sizes and frames to file for (frame, s) in enumerate(size): g.write("{},{},{},{},{},{}\n".format(f, frame, s, 1 if frame == large_index[i] else 0, 1 if frame == small_index[i] else 0, 1 if frame in systole else 0)) # Plot sizes fig = plt.figure(figsize=(size.shape[0] / 50 * 1.5, 3)) plt.scatter(np.arange(size.shape[0]) / 50, size, s=1) ylim = plt.ylim() for s in systole: plt.plot(np.array([s, s]) / 50, ylim, linewidth=1) plt.ylim(ylim) plt.title(os.path.splitext(filename)[0]) plt.xlabel("Seconds") plt.ylabel("Size (pixels)") plt.tight_layout() plt.savefig(os.path.join(output, "size", os.path.splitext(filename)[0] + ".pdf")) plt.close(fig) # Normalize size to [0, 1] size -= size.min() size = size / size.max() size = 1 - size # Iterate the frames in this video for (f, s) in enumerate(size): # On all frames, mark a pixel for the size of the frame video[:, :, int(round(115 + 100 * s)), int(round(f / len(size) * 200 + 10))] = 255. if f in systole: # If frame is computer-selected systole, mark with a line video[:, :, 115:224, int(round(f / len(size) * 200 + 10))] = 255. def dash(start, stop, on=10, off=10): buf = [] x = start while x < stop: buf.extend(range(x, x + on)) x += on x += off buf = np.array(buf) buf = buf[buf < stop] return buf d = dash(115, 224) if f == large_index[i]: # If frame is human-selected diastole, mark with green dashed line on all frames video[:, :, d, int(round(f / len(size) * 200 + 10))] = np.array([0, 225, 0]).reshape((1, 3, 1)) if f == small_index[i]: # If frame is human-selected systole, mark with red dashed line on all frames video[:, :, d, int(round(f / len(size) * 200 + 10))] = np.array([0, 0, 225]).reshape((1, 3, 1)) # Get pixels for a circle centered on the pixel r, c = skimage.draw.circle(int(round(115 + 100 * s)), int(round(f / len(size) * 200 + 10)), 4.1) # On the frame that's being shown, put a circle over the pixel video[f, :, r, c] = 255. # Rearrange dimensions and save video = video.transpose(1, 0, 2, 3) video = video.astype(np.uint8) utils.savevideo(os.path.join(output, "videos", filename), video, 50) # Move to next video start += offset def run_epoch(model, dataloader, train, optim, device): """Run one epoch of training/evaluation for segmentation. Args: model (torch.nn.Module): Model to train/evaulate. dataloder (torch.utils.data.DataLoader): Dataloader for dataset. train (bool): Whether or not to train model. optim (torch.optim.Optimizer): Optimizer device (torch.device): Device to run on """ total = 0. n = 0 pos = 0 neg = 0 pos_pix = 0 neg_pix = 0 model.train(train) large_inter = 0 large_union = 0 small_inter = 0 small_union = 0 large_inter_list = [] large_union_list = [] small_inter_list = [] small_union_list = [] with torch.set_grad_enabled(train): with tqdm.tqdm(total=len(dataloader)) as pbar: for (_, (large_frame, small_frame, large_trace, small_trace)) in dataloader: # Count number of pixels in/out of human segmentation pos += (large_trace == 1).sum().item() pos += (small_trace == 1).sum().item() neg += (large_trace == 0).sum().item() neg += (small_trace == 0).sum().item() # Count number of pixels in/out of computer segmentation pos_pix += (large_trace == 1).sum(0).to("cpu").detach().numpy() pos_pix += (small_trace == 1).sum(0).to("cpu").detach().numpy() neg_pix += (large_trace == 0).sum(0).to("cpu").detach().numpy() neg_pix += (small_trace == 0).sum(0).to("cpu").detach().numpy() # Run prediction for diastolic frames and compute loss large_frame = large_frame.to(device) large_trace = large_trace.to(device) y_large = model(large_frame)["out"] loss_large = torch.nn.functional.binary_cross_entropy_with_logits(y_large[:, 0, :, :], large_trace, reduction="sum") # Compute pixel intersection and union between human and computer segmentations large_inter += np.logical_and(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum() large_union += np.logical_or(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum() large_inter_list.extend(np.logical_and(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2))) large_union_list.extend(np.logical_or(y_large[:, 0, :, :].detach().cpu().numpy() > 0., large_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2))) # Run prediction for systolic frames and compute loss small_frame = small_frame.to(device) small_trace = small_trace.to(device) y_small = model(small_frame)["out"] loss_small = torch.nn.functional.binary_cross_entropy_with_logits(y_small[:, 0, :, :], small_trace, reduction="sum") # Compute pixel intersection and union between human and computer segmentations small_inter += np.logical_and(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum() small_union += np.logical_or(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum() small_inter_list.extend(np.logical_and(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2))) small_union_list.extend(np.logical_or(y_small[:, 0, :, :].detach().cpu().numpy() > 0., small_trace[:, :, :].detach().cpu().numpy() > 0.).sum((1, 2))) # Take gradient step if training loss = (loss_large + loss_small) / 2 if train: optim.zero_grad() loss.backward() optim.step() # Accumulate losses and compute baselines total += loss.item() n += large_trace.size(0) p = pos / (pos + neg) p_pix = (pos_pix + 1) / (pos_pix + neg_pix + 2) # Show info on process bar pbar.set_postfix_str("{:.4f} ({:.4f}) / {:.4f} {:.4f}, {:.4f}, {:.4f}".format(total / n / 112 / 112, loss.item() / large_trace.size(0) / 112 / 112, -p * math.log(p) - (1 - p) * math.log(1 - p), (-p_pix * np.log(p_pix) - (1 - p_pix) * np.log(1 - p_pix)).mean(), 2 * large_inter / (large_union + large_inter), 2 * small_inter / (small_union + small_inter))) pbar.update() large_inter_list = np.array(large_inter_list) large_union_list = np.array(large_union_list) small_inter_list = np.array(small_inter_list) small_union_list = np.array(small_union_list) return (total / n / 112 / 112, large_inter_list, large_union_list, small_inter_list, small_union_list, ) def _video_collate_fn(x): """Collate function for Pytorch dataloader to merge multiple videos. This function should be used in a dataloader for a dataset that returns a video as the first element, along with some (non-zero) tuple of targets. Then, the input x is a list of tuples: - x[i][0] is the i-th video in the batch - x[i][1] are the targets for the i-th video This function returns a 3-tuple: - The first element is the videos concatenated along the frames dimension. This is done so that videos of different lengths can be processed together (tensors cannot be "jagged", so we cannot have a dimension for video, and another for frames). - The second element is contains the targets with no modification. - The third element is a list of the lengths of the videos in frames. """ video, target = zip(*x) # Extract the videos and targets # ``video'' is a tuple of length ``batch_size'' # Each element has shape (channels=3, frames, height, width) # height and width are expected to be the same across videos, but # frames can be different. # ``target'' is also a tuple of length ``batch_size'' # Each element is a tuple of the targets for the item. i = list(map(lambda t: t.shape[1], video)) # Extract lengths of videos in frames # This contatenates the videos along the the frames dimension (basically # playing the videos one after another). The frames dimension is then # moved to be first. # Resulting shape is (total frames, channels=3, height, width) video = torch.as_tensor(np.swapaxes(np.concatenate(video, 1), 0, 1)) # Swap dimensions (approximately a transpose) # Before: target[i][j] is the j-th target of element i # After: target[i][j] is the i-th target of element j target = zip(*target) return video, target, i if __name__ == '__main__': run(num_epochs=40, modelname="deeplabv3_resnet50", pretrained=False, output=None, device=None, n_train_patients=None, num_workers=0, batch_size=2, seed=0, lr_step_period=None, save_segmentation=True, block_size=64, run_test=False)
# Run training and testing loops
with open(os.path.join(output, "log.csv"), "a") as f:
epoch_resume = 0
bestLoss = float("inf")
try:
# Attempt to load checkpoint
checkpoint = torch.load(os.path.join(output, "checkpoint.pt"))
model.load_state_dict(checkpoint['state_dict'])
optim.load_state_dict(checkpoint['opt_dict'])
scheduler.load_state_dict(checkpoint['scheduler_dict'])
epoch_resume = checkpoint["epoch"] + 1
bestLoss = checkpoint["best_loss"]
f.write("Resuming from epoch {}\n".format(epoch_resume))
except FileNotFoundError:
f.write("Starting run from scratch\n")
输出:
best.pt最好的
图像标签处理:
1 """EchoNet-Dynamic Dataset.""" 2 3 import pathlib 4 import os 5 import collections 6 7 import numpy as np 8 import skimage.draw 9 import torch.utils.data 10 #import echonet 11 import os,sys 12 parentdir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 13 sys.path.insert(0,parentdir) 14 import config 15 import utils 16 17 18 class Echo(torch.utils.data.Dataset): 19 """EchoNet-Dynamic Dataset. 20 21 Args: 22 root (string): Root directory of dataset (defaults to `echonet.config.DATA_DIR`) 23 split (string): One of {"train", "val", "test", "external_test"} 24 target_type (string or list, optional): Type of target to use, 25 ``Filename'', ``EF'', ``EDV'', ``ESV'', ``LargeIndex'', 26 ``SmallIndex'', ``LargeFrame'', ``SmallFrame'', ``LargeTrace'', 27 or ``SmallTrace'' 28 Can also be a list to output a tuple with all specified target types. 29 The targets represent: 30 ``Filename'' (string): filename of video 31 ``EF'' (float): ejection fraction 32 ``EDV'' (float): end-diastolic volume 33 ``ESV'' (float): end-systolic volume 34 ``LargeIndex'' (int): index of large (diastolic) frame in video 35 ``SmallIndex'' (int): index of small (systolic) frame in video 36 ``LargeFrame'' (np.array shape=(3, height, width)): normalized large (diastolic) frame 37 ``SmallFrame'' (np.array shape=(3, height, width)): normalized small (systolic) frame 38 ``LargeTrace'' (np.array shape=(height, width)): left ventricle large (diastolic) segmentation 39 value of 0 indicates pixel is outside left ventricle 40 1 indicates pixel is inside left ventricle 41 ``SmallTrace'' (np.array shape=(height, width)): left ventricle small (systolic) segmentation 42 value of 0 indicates pixel is outside left ventricle 43 1 indicates pixel is inside left ventricle 44 Defaults to ``EF''. 45 mean (int, float, or np.array shape=(3,), optional): means for all (if scalar) or each (if np.array) channel. 46 Used for normalizing the video. Defaults to 0 (video is not shifted). 47 std (int, float, or np.array shape=(3,), optional): standard deviation for all (if scalar) or each (if np.array) channel. 48 Used for normalizing the video. Defaults to 0 (video is not scaled). 49 length (int or None, optional): Number of frames to clip from video. If ``None'', longest possible clip is returned. 50 Defaults to 16. 51 period (int, optional): Sampling period for taking a clip from the video (i.e. every ``period''-th frame is taken) 52 Defaults to 2. 53 max_length (int or None, optional): Maximum number of frames to clip from video (main use is for shortening excessively 54 long videos when ``length'' is set to None). If ``None'', shortening is not applied to any video. 55 Defaults to 250. 56 clips (int, optional): Number of clips to sample. Main use is for test-time augmentation with random clips. 57 Defaults to 1. 58 pad (int or None, optional): Number of pixels to pad all frames on each side (used as augmentation). 59 and a window of the original size is taken. If ``None'', no padding occurs. 60 Defaults to ``None''. 61 noise (float or None, optional): Fraction of pixels to black out as simulated noise. If ``None'', no simulated noise is added. 62 Defaults to ``None''. 63 target_transform (callable, optional): A function/transform that takes in the target and transforms it. 64 external_test_location (string): Path to videos to use for external testing. 65 """ 66 67 def __init__(self, root='../../a4c-video-dir', 68 split="train", target_type="EF", 69 mean=0., std=1., 70 length=16, period=2, 71 max_length=250, 72 clips=1, 73 pad=None, 74 noise=None, 75 target_transform=None, 76 external_test_location=None): 77 78 if root is None: 79 root = config.DATA_DIR 80 81 #self.folder = pathlib.Path(root) 82 self.folder = root 83 self.split = split 84 if not isinstance(target_type, list): 85 target_type = [target_type] 86 self.target_type = target_type 87 self.mean = mean 88 self.std = std 89 self.length = length 90 self.max_length = max_length 91 self.period = period 92 self.clips = clips 93 self.pad = pad 94 self.noise = noise 95 self.target_transform = target_transform 96 self.external_test_location = external_test_location 97 98 self.fnames, self.outcome = [], [] 99 100 if split == "external_test": 101 self.fnames = sorted(os.listdir(self.external_test_location)) 102 else: 103 #with open(self.folder / "FileList.csv") as f: 104 with open(self.folder+'./FileList.csv') as f: 105 self.header = f.readline().strip().split(",") 106 filenameIndex = self.header.index("FileName") 107 splitIndex = self.header.index("Split") 108 109 for line in f: 110 lineSplit = line.strip().split(',') 111 112 fileName = lineSplit[filenameIndex] 113 fileMode = lineSplit[splitIndex].lower() 114 115 #if split in ["all", fileMode] and os.path.exists(self.folder / "Videos" / fileName): 116 #print(self.folder+"/Videos/" + str(fileName)) 117 if split in ["all", fileMode] and os.path.exists(self.folder+"/Videos/" + str(fileName)+'.avi'): 118 self.fnames.append(fileName) 119 self.outcome.append(lineSplit) 120 121 self.frames = collections.defaultdict(list) 122 self.trace = collections.defaultdict(_defaultdict_of_lists) 123 124 #with open(self.folder / "VolumeTracings.csv") as f: 125 with open(self.folder+"/VolumeTracings.csv") as f: 126 header = f.readline().strip().split(",") 127 assert header == ["FileName", "X1", "Y1", "X2", "Y2", "Frame"] 128 129 for line in f: 130 filename, x1, y1, x2, y2, frame = line.strip().split(',') 131 x1 = float(x1) 132 y1 = float(y1) 133 x2 = float(x2) 134 y2 = float(y2) 135 frame = int(frame) 136 if frame not in self.trace[filename]: 137 self.frames[filename].append(frame) 138 self.trace[filename][frame].append((x1, y1, x2, y2)) 139 for filename in self.frames: 140 for frame in self.frames[filename]: 141 self.trace[filename][frame] = np.array(self.trace[filename][frame]) 142 143 #print(self.fnames) 144 #print(self.frames[os.path.splitext('0X1002E8FBACD08477')[0]]) 145 keep = [len(self.frames[os.path.splitext(f)[0]+'.avi']) >= 2 for f in self.fnames] 146 #print(keep) 147 self.fnames = [f for (f, k) in zip(self.fnames, keep) if k] 148 149 self.outcome = [f for (f, k) in zip(self.outcome, keep) if k] 150 151 def __getitem__(self, index): 152 # Find filename of video 153 if self.split == "external_test": 154 video = os.path.join(self.external_test_location, self.fnames[index]) 155 elif self.split == "clinical_test": 156 video = os.path.join(self.folder, "ProcessedStrainStudyA4c", self.fnames[index]) 157 else: 158 video = os.path.join(self.folder, "Videos", self.fnames[index]) 159 #video += '.avi' 160 # Load video into np.array 161 video = utils.loadvideo(video).astype(np.float32) 162 163 # Add simulated noise (black out random pixels) 164 # 0 represents black at this point (video has not been normalized yet) 165 if self.noise is not None: 166 n = video.shape[1] * video.shape[2] * video.shape[3] 167 ind = np.random.choice(n, round(self.noise * n), replace=False) 168 f = ind % video.shape[1] 169 ind //= video.shape[1] 170 i = ind % video.shape[2] 171 ind //= video.shape[2] 172 j = ind 173 video[:, f, i, j] = 0 174 175 # Apply normalization 176 if isinstance(self.mean, (float, int)): 177 video -= self.mean 178 else: 179 video -= self.mean.reshape(3, 1, 1, 1) 180 181 if isinstance(self.std, (float, int)): 182 video /= self.std 183 else: 184 video /= self.std.reshape(3, 1, 1, 1) 185 186 # Set number of frames 187 c, f, h, w = video.shape 188 if self.length is None: 189 # Take as many frames as possible 190 length = f // self.period 191 else: 192 # Take specified number of frames 193 length = self.length 194 195 if self.max_length is not None: 196 # Shorten videos to max_length 197 length = min(length, self.max_length) 198 199 if f < length * self.period: 200 # Pad video with frames filled with zeros if too short 201 # 0 represents the mean color (dark grey), since this is after normalization 202 video = np.concatenate((video, np.zeros((c, length * self.period - f, h, w), video.dtype)), axis=1) 203 c, f, h, w = video.shape # pylint: disable=E0633 204 205 if self.clips == "all": 206 # Take all possible clips of desired length 207 start = np.arange(f - (length - 1) * self.period) 208 else: 209 # Take random clips from video 210 start = np.random.choice(f - (length - 1) * self.period, self.clips) 211 212 # Gather targets 213 target = [] 214 for t in self.target_type: 215 key = os.path.splitext(self.fnames[index])[0] 216 key += '.avi' 217 if t == "Filename": 218 target.append(self.fnames[index]) 219 elif t == "LargeIndex": 220 # Traces are sorted by cross-sectional area 221 # Largest (diastolic) frame is last 222 target.append(np.int(self.frames[key][-1])) 223 elif t == "SmallIndex": 224 # Largest (diastolic) frame is first 225 target.append(np.int(self.frames[key][0])) 226 elif t == "LargeFrame": 227 target.append(video[:, self.frames[key][-1], :, :]) 228 elif t == "SmallFrame": 229 target.append(video[:, self.frames[key][0], :, :]) 230 elif t in ["LargeTrace", "SmallTrace"]: 231 if t == "LargeTrace": 232 t = self.trace[key][self.frames[key][-1]] 233 else: 234 t = self.trace[key][self.frames[key][0]] 235 x1, y1, x2, y2 = t[:, 0], t[:, 1], t[:, 2], t[:, 3] 236 x = np.concatenate((x1[1:], np.flip(x2[1:]))) 237 y = np.concatenate((y1[1:], np.flip(y2[1:]))) 238 239 r, c = skimage.draw.polygon(np.rint(y).astype(np.int), np.rint(x).astype(np.int), (video.shape[2], video.shape[3])) 240 mask = np.zeros((video.shape[2], video.shape[3]), np.float32) 241 mask[r, c] = 1 242 target.append(mask) 243 else: 244 if self.split == "clinical_test" or self.split == "external_test": 245 target.append(np.float32(0)) 246 else: 247 target.append(np.float32(self.outcome[index][self.header.index(t)])) 248 249 if target != []: 250 target = tuple(target) if len(target) > 1 else target[0] 251 if self.target_transform is not None: 252 target = self.target_transform(target) 253 254 # Select random clips 255 video = tuple(video[:, s + self.period * np.arange(length), :, :] for s in start) 256 if self.clips == 1: 257 video = video[0] 258 else: 259 video = np.stack(video) 260 261 if self.pad is not None: 262 # Add padding of zeros (mean color of videos) 263 # Crop of original size is taken out 264 # (Used as augmentation) 265 c, l, h, w = video.shape 266 temp = np.zeros((c, l, h + 2 * self.pad, w + 2 * self.pad), dtype=video.dtype) 267 temp[:, :, self.pad:-self.pad, self.pad:-self.pad] = video # pylint: disable=E1130 268 i, j = np.random.randint(0, 2 * self.pad, 2) 269 video = temp[:, :, i:(i + h), j:(j + w)] 270 271 return video, target 272 273 def __len__(self): 274 return len(self.fnames) 275 276 277 def _defaultdict_of_lists(): 278 """Returns a defaultdict of lists. 279 280 This is used to avoid issues with Windows (if this function is anonymous, 281 the Echo dataset cannot be used in a dataloader). 282 """ 283 284 return collections.defaultdict(list)
读取图像,扩充、收缩标签,稍微繁琐。日志文件:
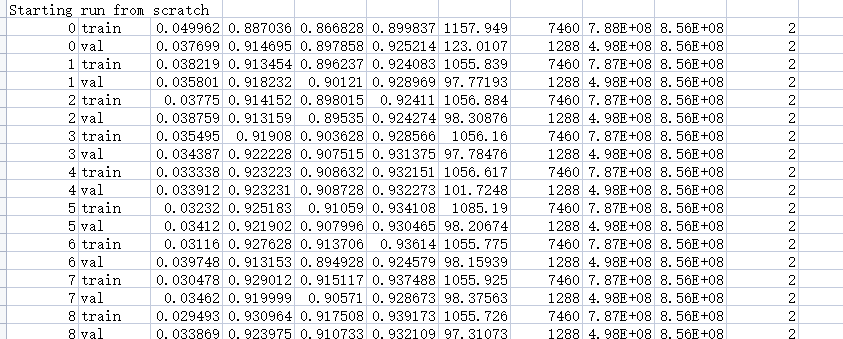
预测:
1 """Functions for training and running EF prediction.""" 2 3 import math 4 import time 5 6 import matplotlib.pyplot as plt 7 import numpy as np 8 import sklearn.metrics 9 import torch 10 import torchvision 11 import tqdm 12 import os,sys 13 parentdir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 14 sys.path.insert(0,parentdir) 15 import utils 16 from datasets import echo 17 18 19 20 def run(num_epochs=45, 21 modelname="r2plus1d_18", 22 tasks="EF", 23 frames=32, 24 period=2, 25 pretrained=True, 26 output=None, 27 device=None, 28 n_train_patients=None, 29 num_workers=5, 30 batch_size=20, 31 seed=0, 32 lr_step_period=15, 33 run_test=False): 34 """Trains/tests EF prediction model. 35 36 Args: 37 num_epochs (int, optional): Number of epochs during training 38 Defaults to 45. 39 modelname (str, optional): Name of model. One of ``mc3_18'', 40 ``r2plus1d_18'', or ``r3d_18'' 41 (options are torchvision.models.video.<modelname>) 42 Defaults to ``r2plus1d_18''. 43 tasks (str, optional): Name of task to predict. Options are the headers 44 of FileList.csv. 45 Defaults to ``EF''. 46 pretrained (bool, optional): Whether to use pretrained weights for model 47 Defaults to True. 48 output (str or None, optional): Name of directory to place outputs 49 Defaults to None (replaced by output/video/<modelname>_<pretrained/random>/). 50 device (str or None, optional): Name of device to run on. See 51 https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.device 52 for options. If ``None'', defaults to ``cuda'' if available, and ``cpu'' otherwise. 53 Defaults to ``None''. 54 n_train_patients (str or None, optional): Number of training patients. Used to ablations 55 on number of training patients. If ``None'', all patients used. 56 Defaults to ``None''. 57 num_workers (int, optional): how many subprocesses to use for data 58 loading. If 0, the data will be loaded in the main process. 59 Defaults to 5. 60 batch_size (int, optional): how many samples per batch to load 61 Defaults to 20. 62 seed (int, optional): Seed for random number generator. 63 Defaults to 0. 64 lr_step_period (int or None, optional): Period of learning rate decay 65 (learning rate is decayed by a multiplicative factor of 0.1) 66 If ``None'', learning rate is not decayed. 67 Defaults to 15. 68 run_test (bool, optional): Whether or not to run on test. 69 Defaults to False. 70 """ 71 72 # Seed RNGs 73 np.random.seed(seed) 74 torch.manual_seed(seed) 75 76 # Set default output directory 77 if output is None: 78 output = os.path.join("output", "video", "{}_{}_{}_{}".format(modelname, frames, period, "pretrained" if pretrained else "random")) 79 os.makedirs(output, exist_ok=True) 80 81 # Set device for computations 82 if device is None: 83 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 84 85 # Set up model 86 model = torchvision.models.video.__dict__[modelname](pretrained=pretrained) 87 88 model.fc = torch.nn.Linear(model.fc.in_features, 1) 89 model.fc.bias.data[0] = 55.6#初始经验值 90 if device.type == "cuda": 91 model = torch.nn.DataParallel(model) 92 model.to(device) 93 94 # Set up optimizer 95 optim = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9, weight_decay=1e-4) 96 if lr_step_period is None: 97 lr_step_period = math.inf 98 scheduler = torch.optim.lr_scheduler.StepLR(optim, lr_step_period) 99 100 # Compute mean and std 101 mean, std = utils.get_mean_and_std(echo.Echo(split="train")) 102 kwargs = {"target_type": tasks, 103 "mean": mean, 104 "std": std, 105 "length": frames, 106 "period": period, 107 } 108 109 # Set up datasets and dataloaders 110 train_dataset = echo.Echo(split="train", **kwargs, pad=12) 111 if n_train_patients is not None and len(train_dataset) > n_train_patients: 112 # Subsample patients (used for ablation experiment) 113 indices = np.random.choice(len(train_dataset), n_train_patients, replace=False) 114 train_dataset = torch.utils.data.Subset(train_dataset, indices) 115 116 train_dataloader = torch.utils.data.DataLoader( 117 train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda"), drop_last=True) 118 val_dataloader = torch.utils.data.DataLoader( 119 echo.Echo(split="val", **kwargs), batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda")) 120 dataloaders = {'train': train_dataloader, 'val': val_dataloader} 121 122 # Run training and testing loops 123 with open(os.path.join(output, "log.csv"), "a") as f: 124 epoch_resume = 0 125 bestLoss = float("inf") 126 try: 127 # Attempt to load checkpoint 128 checkpoint = torch.load(os.path.join(output, "checkpoint.pt")) 129 model.load_state_dict(checkpoint['state_dict']) 130 optim.load_state_dict(checkpoint['opt_dict']) 131 scheduler.load_state_dict(checkpoint['scheduler_dict']) 132 epoch_resume = checkpoint["epoch"] + 1 133 bestLoss = checkpoint["best_loss"] 134 f.write("Resuming from epoch {}\n".format(epoch_resume)) 135 except FileNotFoundError: 136 f.write("Starting run from scratch\n") 137 138 for epoch in range(epoch_resume, num_epochs): 139 print("Epoch #{}".format(epoch), flush=True) 140 for phase in ['train', 'val']: 141 start_time = time.time() 142 for i in range(torch.cuda.device_count()): 143 torch.cuda.reset_max_memory_allocated(i) 144 torch.cuda.reset_max_memory_cached(i) 145 loss, yhat, y = utils.video.run_epoch(model, dataloaders[phase], phase == "train", optim, device) 146 f.write("{},{},{},{},{},{},{},{},{}\n".format(epoch, 147 phase, 148 loss, 149 sklearn.metrics.r2_score(yhat, y), 150 time.time() - start_time, 151 y.size, 152 sum(torch.cuda.max_memory_allocated() for i in range(torch.cuda.device_count())), 153 sum(torch.cuda.max_memory_cached() for i in range(torch.cuda.device_count())), 154 batch_size)) 155 f.flush() 156 scheduler.step() 157 158 # Save checkpoint 159 save = { 160 'epoch': epoch, 161 'state_dict': model.state_dict(), 162 'period': period, 163 'frames': frames, 164 'best_loss': bestLoss, 165 'loss': loss, 166 'r2': sklearn.metrics.r2_score(yhat, y), 167 'opt_dict': optim.state_dict(), 168 'scheduler_dict': scheduler.state_dict(), 169 } 170 torch.save(save, os.path.join(output, "checkpoint.pt")) 171 if loss < bestLoss: 172 torch.save(save, os.path.join(output, "best.pt")) 173 bestLoss = loss 174 175 # Load best weights 176 checkpoint = torch.load(os.path.join(output, "best.pt")) 177 model.load_state_dict(checkpoint['state_dict']) 178 f.write("Best validation loss {} from epoch {}\n".format(checkpoint["loss"], checkpoint["epoch"])) 179 f.flush() 180 181 if run_test: 182 for split in ["val", "test"]: 183 # Performance without test-time augmentation 184 dataloader = torch.utils.data.DataLoader( 185 echo.Echo(split=split, **kwargs), 186 batch_size=batch_size, num_workers=num_workers, shuffle=True, pin_memory=(device.type == "cuda")) 187 loss, yhat, y = utils.video.run_epoch(model, dataloader, False, None, device) 188 f.write("{} (one clip) R2: {:.3f} ({:.3f} - {:.3f})\n".format(split, *utils.bootstrap(y, yhat, sklearn.metrics.r2_score))) 189 f.write("{} (one clip) MAE: {:.2f} ({:.2f} - {:.2f})\n".format(split, *utils.bootstrap(y, yhat, sklearn.metrics.mean_absolute_error))) 190 f.write("{} (one clip) RMSE: {:.2f} ({:.2f} - {:.2f})\n".format(split, *tuple(map(math.sqrt, utils.bootstrap(y, yhat, sklearn.metrics.mean_squared_error))))) 191 f.flush() 192 193 # Performance with test-time augmentation 194 ds = echo.Echo(split=split, **kwargs, clips="all") 195 dataloader = torch.utils.data.DataLoader( 196 ds, batch_size=1, num_workers=num_workers, shuffle=False, pin_memory=(device.type == "cuda")) 197 loss, yhat, y = utils.video.run_epoch(model, dataloader, False, None, device, save_all=True, block_size=100) 198 f.write("{} (all clips) R2: {:.3f} ({:.3f} - {:.3f})\n".format(split, *utils.bootstrap(y, np.array(list(map(lambda x: x.mean(), yhat))), sklearn.metrics.r2_score))) 199 f.write("{} (all clips) MAE: {:.2f} ({:.2f} - {:.2f})\n".format(split, *utils.bootstrap(y, np.array(list(map(lambda x: x.mean(), yhat))), sklearn.metrics.mean_absolute_error))) 200 f.write("{} (all clips) RMSE: {:.2f} ({:.2f} - {:.2f})\n".format(split, *tuple(map(math.sqrt, utils.bootstrap(y, np.array(list(map(lambda x: x.mean(), yhat))), sklearn.metrics.mean_squared_error))))) 201 f.flush() 202 203 # Write full performance to file 204 with open(os.path.join(output, "{}_predictions.csv".format(split)), "w") as g: 205 for (filename, pred) in zip(ds.fnames, yhat): 206 for (i, p) in enumerate(pred): 207 g.write("{},{},{:.4f}\n".format(filename, i, p)) 208 utils.latexify() 209 yhat = np.array(list(map(lambda x: x.mean(), yhat))) 210 211 # Plot actual and predicted EF 212 fig = plt.figure(figsize=(3, 3)) 213 lower = min(y.min(), yhat.min()) 214 upper = max(y.max(), yhat.max()) 215 plt.scatter(y, yhat, color="k", s=1, edgecolor=None, zorder=2) 216 plt.plot([0, 100], [0, 100], linewidth=1, zorder=3) 217 plt.axis([lower - 3, upper + 3, lower - 3, upper + 3]) 218 plt.gca().set_aspect("equal", "box") 219 plt.xlabel("Actual EF (%)") 220 plt.ylabel("Predicted EF (%)") 221 plt.xticks([10, 20, 30, 40, 50, 60, 70, 80]) 222 plt.yticks([10, 20, 30, 40, 50, 60, 70, 80]) 223 plt.grid(color="gainsboro", linestyle="--", linewidth=1, zorder=1) 224 plt.tight_layout() 225 plt.savefig(os.path.join(output, "{}_scatter.pdf".format(split))) 226 plt.close(fig) 227 228 # Plot AUROC 229 fig = plt.figure(figsize=(3, 3)) 230 plt.plot([0, 1], [0, 1], linewidth=1, color="k", linestyle="--") 231 for thresh in [35, 40, 45, 50]: 232 fpr, tpr, _ = sklearn.metrics.roc_curve(y > thresh, yhat) 233 print(thresh, sklearn.metrics.roc_auc_score(y > thresh, yhat)) 234 plt.plot(fpr, tpr) 235 236 plt.axis([-0.01, 1.01, -0.01, 1.01]) 237 plt.xlabel("False Positive Rate") 238 plt.ylabel("True Positive Rate") 239 plt.tight_layout() 240 plt.savefig(os.path.join(output, "{}_roc.pdf".format(split))) 241 plt.close(fig) 242 243 244 def run_epoch(model, dataloader, train, optim, device, save_all=False, block_size=1): 245 """Run one epoch of training/evaluation for segmentation. 246 247 Args: 248 model (torch.nn.Module): Model to train/evaulate. 249 dataloder (torch.utils.data.DataLoader): Dataloader for dataset. 250 train (bool): Whether or not to train model. 251 optim (torch.optim.Optimizer): Optimizer 252 device (torch.device): Device to run on 253 save_all (bool, optional): If True, return predictions for all 254 test-time augmentations separately. If False, return only 255 the mean prediction. 256 Defaults to False. 257 block_size (int or None, optional): Maximum number of augmentations 258 to run on at the same time. Use to limit the amount of memory 259 used. If None, always run on all augmentations simultaneously. 260 Default is None. 261 """ 262 263 model.train(train) 264 265 total = 0 # total training loss 266 n = 0 # number of videos processed 267 s1 = 0 # sum of ground truth EF 268 s2 = 0 # Sum of ground truth EF squared 269 270 yhat = [] 271 y = [] 272 273 with torch.set_grad_enabled(train): 274 with tqdm.tqdm(total=len(dataloader)) as pbar: 275 for (X, outcome) in dataloader: 276 277 y.append(outcome.numpy()) 278 X = X.to(device) 279 outcome = outcome.to(device) 280 281 average = (len(X.shape) == 6) 282 if average: 283 batch, n_clips, c, f, h, w = X.shape 284 X = X.view(-1, c, f, h, w) 285 286 s1 += outcome.sum() 287 s2 += (outcome ** 2).sum() 288 289 if block_size is None: 290 outputs = model(X) 291 else: 292 outputs = torch.cat([model(X[j:(j + block_size), ...]) for j in range(0, X.shape[0], block_size)]) 293 294 if save_all: 295 yhat.append(outputs.view(-1).to("cpu").detach().numpy()) 296 297 if average: 298 outputs = outputs.view(batch, n_clips, -1).mean(1) 299 300 if not save_all: 301 yhat.append(outputs.view(-1).to("cpu").detach().numpy()) 302 303 loss = torch.nn.functional.mse_loss(outputs.view(-1), outcome) 304 305 if train: 306 optim.zero_grad() 307 loss.backward() 308 optim.step() 309 310 total += loss.item() * X.size(0) 311 n += X.size(0) 312 313 pbar.set_postfix_str("{:.2f} ({:.2f}) / {:.2f}".format(total / n, loss.item(), s2 / n - (s1 / n) ** 2)) 314 pbar.update() 315 316 if not save_all: 317 yhat = np.concatenate(yhat) 318 y = np.concatenate(y) 319 320 return total / n, yhat, y 321 if __name__ == '__main__': 322 run(num_epochs=20, 323 modelname="r2plus1d_18", 324 tasks="EF", 325 frames=32, 326 period=2, 327 pretrained=True, 328 output=None, 329 device=None, 330 n_train_patients=None, 331 num_workers=0, 332 batch_size=2, 333 seed=0, 334 lr_step_period=15, 335 run_test=True)
论文:
Video-based AI for beat-to-beat assessment of cardiac function | Nature
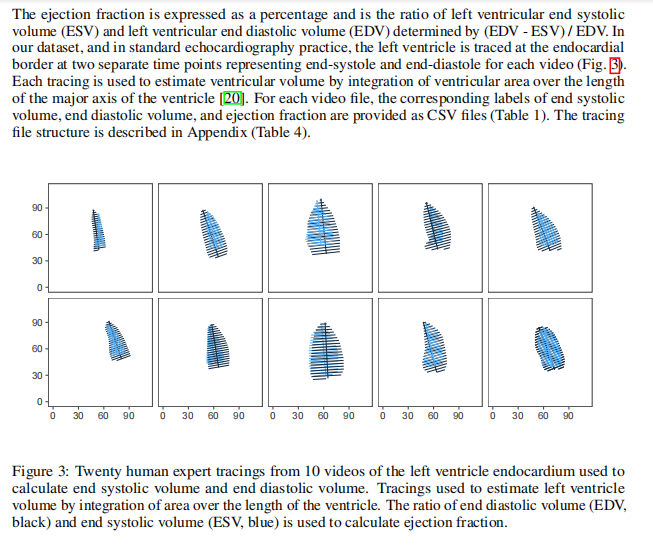
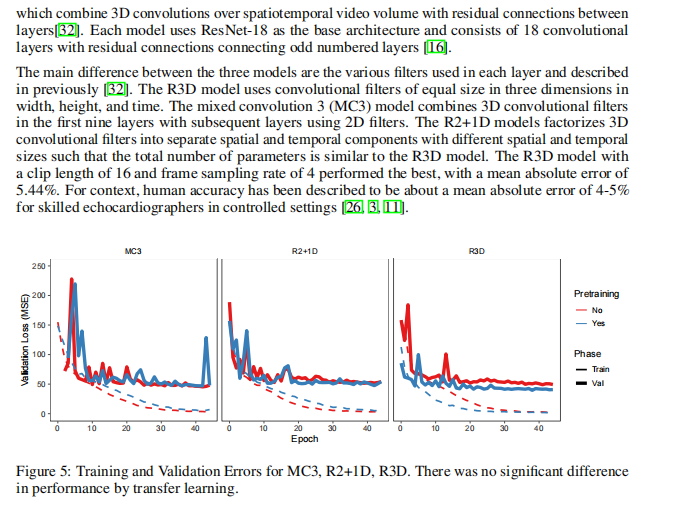
GitHub: