Langchain
Repository search results (github.com)
Question Answering | 🦜️🔗 Langchain
假设您有一些文本文档(PDF、blog、Notion页面等),并且希望询问与这些文档内容相关的问题。法学硕士,鉴于他们在理解文本方面的熟练程度,是一个很好的工具。在本演练中,我们将介绍如何使用llm构建基于文档的问答应用程序。我们在其他地方介绍的两个非常相关的用例是:

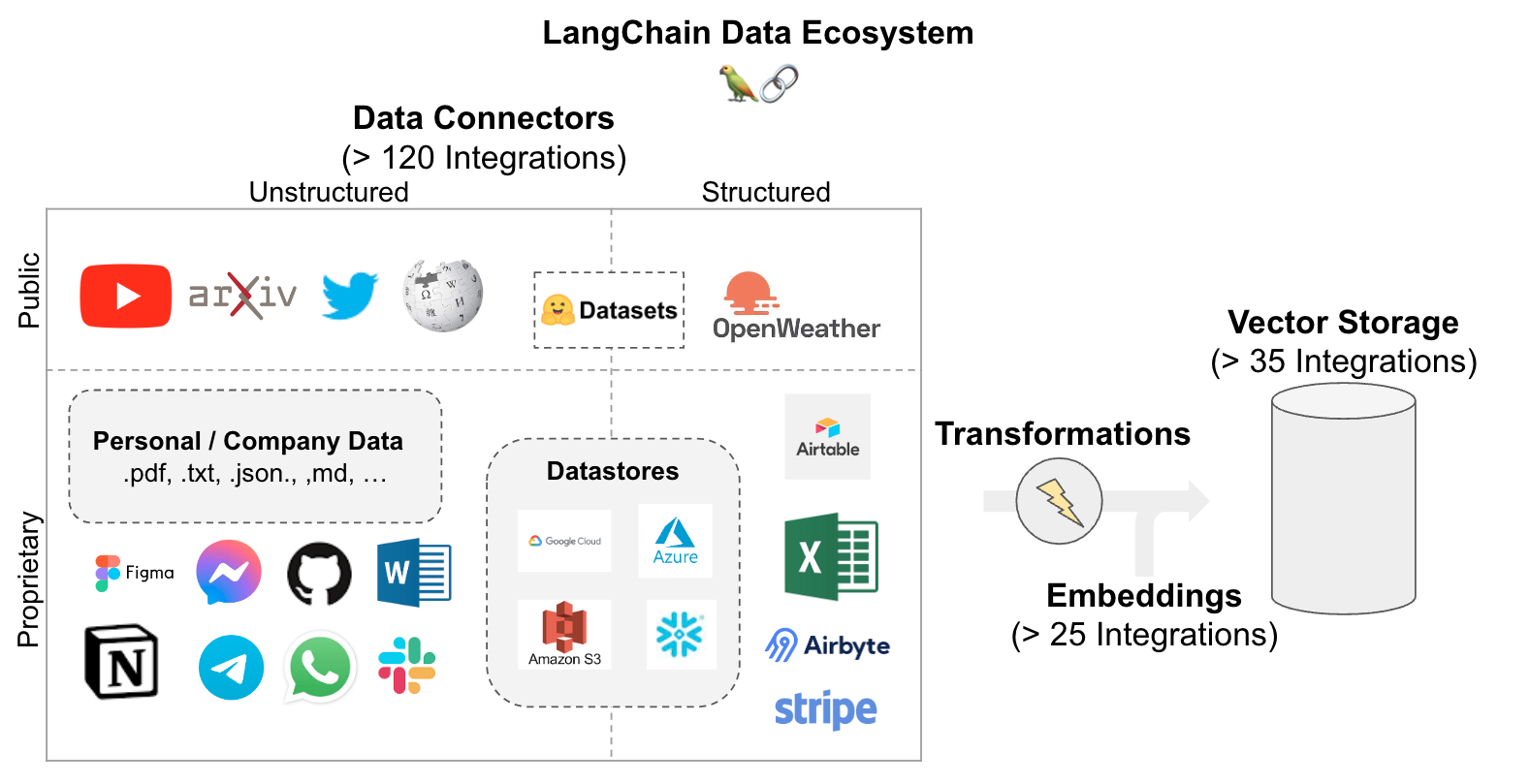
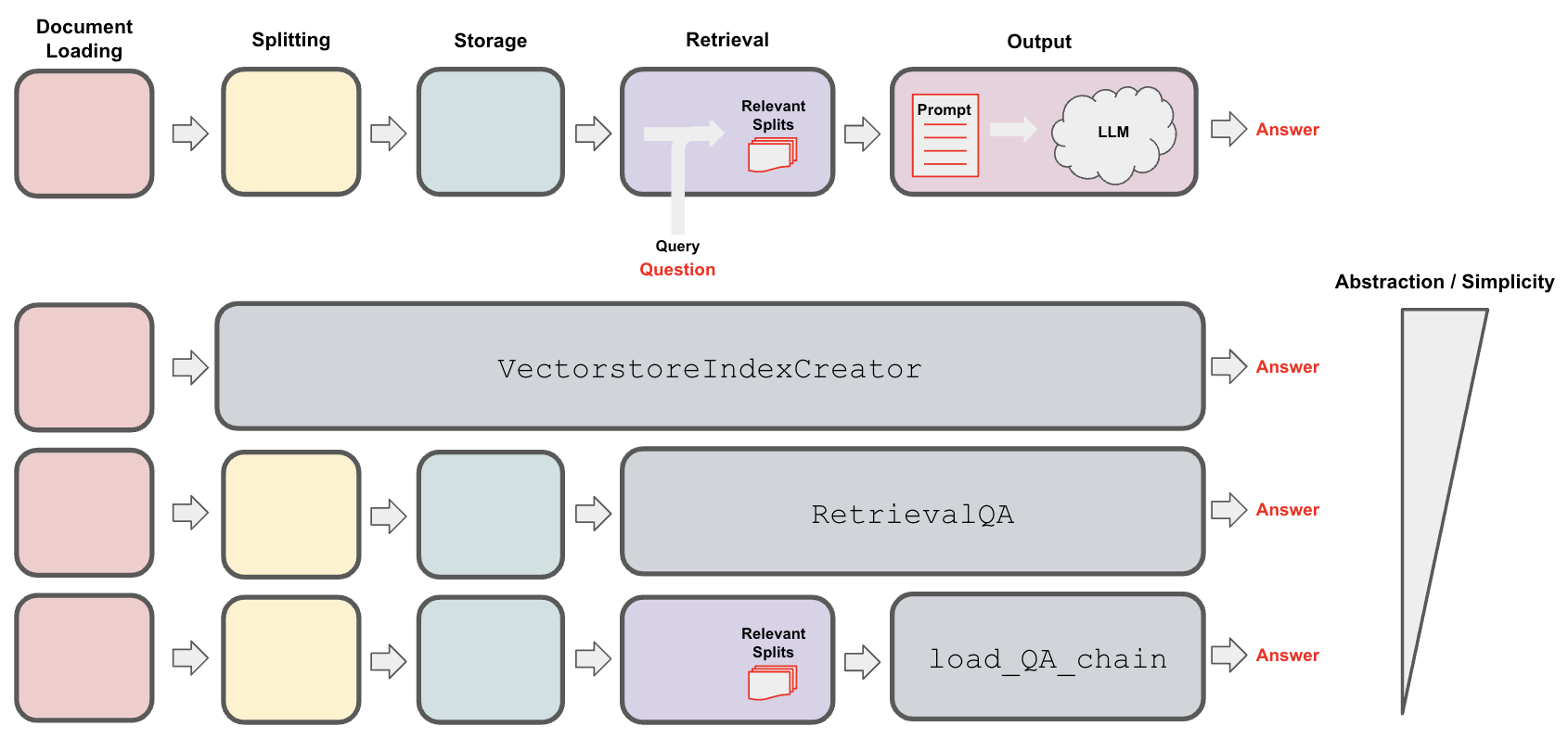
Loading:首先我们需要加载我们的数据。可以从多个源加载非结构化数据。使用 LangChain 集成中心浏览全套加载器。 每个加载器将数据作为 LangChain文档返回。Splitting:文本拆分器分解为指定大小的拆分DocumentsStorage:存储(例如,通常是矢量存储)将容纳并经常嵌入拆分Retrieval:应用从存储中检索拆分(例如,通常具有与输入问题类似的嵌入)Generation:LLM使用包含问题和检索到的数据的提示生成答案Conversation(扩展):通过将内存添加到您的 QA 链来保持多轮对话。

from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever()) qa_chain({"query": question})
{'query': 'What are the approaches to Task Decomposition?',
'result': 'There are three approaches to task decomposition:\n\n1. Using Language Model with simple prompting: This approach involves using a Language Model (LLM) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to guide the task decomposition process.\n\n2. Using task-specific instructions: In this approach, task-specific instructions are provided to guide the task decomposition. For example, for the task of writing a novel, an instruction like "Write a story outline" can be given to help decompose the task into smaller subtasks.\n\n3. Human inputs: Task decomposition can also be done with the help of human inputs. This involves getting input and guidance from humans to break down a complex task into smaller, more manageable subtasks.'}
聊天机器人是LLM的核心用例之一。聊天机器人的核心功能是它们可以进行长时间运行的对话,并可以访问用户想要了解的信息。
除了基本的提示和LLM之外,记忆和检索是聊天机器人的核心组件。内存允许聊天机器人记住过去的交互,检索为聊天机器人提供最新的、特定于域的信息。



import os # Import Azure OpenAI from langchain.llms import AzureOpenAI import openai #response = openai.Completion.create( # engine="text-davinci-002-prod", #prompt="This is a test", # max_tokens=5 #) os.environ["OPENAI_API_TYPE"] = "azure" os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview" os.environ["OPENAI_API_BASE"] = "https://**.openai.azure.com/" os.environ["OPENAI_API_KEY"] = "b09432" # Create an instance of Azure OpenAI # Replace the deployment name with your own llm = AzureOpenAI( deployment_name="chatgpt35", model_name="text-davinci-002", temperature=0 ) # Run the LLM #llm_result=llm("Tell me a joke") #llm_result=llm("where is the capital of china?") llm_result=llm("介绍") #print(llm) #llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*3) print(llm_result)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号