爬取网页table数据
python爬取table表格里的数据:


import requests from bs4 import BeautifulSoup import pandas as pd # 爬取进出口贸易数据的函数 def crawl_trade_data(): url = "https://www.india.org.pk/pages.php?id=16" # 贸易和工业部网站的进出口贸易数据页面 response = requests.get(url) # 解析网页 soup = BeautifulSoup(response.content, 'html.parser') # 查找表格并提取数据 table = soup.find('table') trade_data = [] for row in table.find_all('tr'): data_row = [] for col in row.find_all(['td', 'th']): data_row.append(col.text.strip()) if data_row: trade_data.append(data_row) return trade_data # 将数据保存到Excel def save_to_excel(data): df = pd.DataFrame(data[1:], columns=data[0]) # 将爬取的数据转换为DataFrame格式 df.to_excel('trade_data.xlsx', index=False) # 保存DataFrame到Excel文件 # 主函数 def main(): trade_data = crawl_trade_data() # 打印最近几年的进出口贸易数据 print("近年印度进出口贸易情况:") for data_row in trade_data: year = data_row[0] export_value = data_row[1] import_value = data_row[2] print(f"{year} 年,出口额:{export_value},进口额:{import_value}") save_to_excel(trade_data) # 将数据保存到Excel if __name__ == "__main__": main()
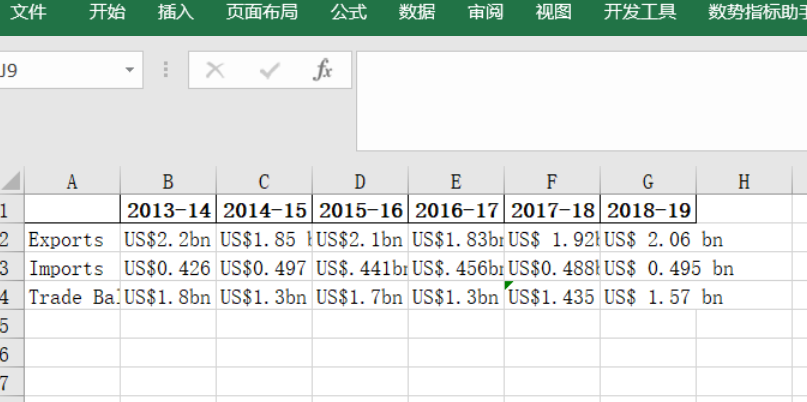
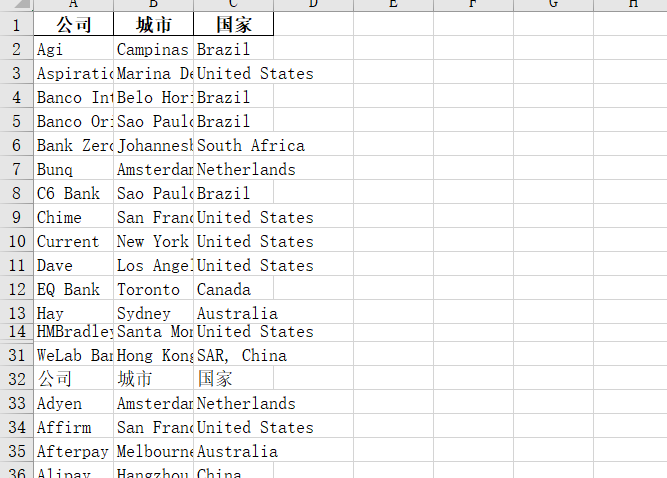
import requests from bs4 import BeautifulSoup import pandas as pd # 爬取金融数据的函数 def crawl_trade_data(): url = "https://mp.weixin.qq.com/s/aosM40gXSZjdzlNNvaaWEg" response = requests.get(url) # 解析网页 soup = BeautifulSoup(response.content, 'html.parser') # 查找所有表格并提取数据 tables = soup.find_all('table') trade_data = [] for table in tables: for row in table.find_all('tr'): data_row = [] for col in row.find_all(['td', 'th']): data_row.append(col.text.strip()) if data_row: trade_data.append(data_row) return trade_data # 将数据保存到Excel def save_to_excel(data): df = pd.DataFrame(data[1:], columns=data[0]) # 将爬取的数据转换为DataFrame格式 df.to_excel('trade_data13.xlsx', index=False) # 保存DataFrame到Excel文件 # 主函数 def main(): trade_data = crawl_trade_data() # 打印最近几年的进出口贸易数据 print("近年印度进出口贸易情况:") for data_row in trade_data: year = data_row[0] export_value = data_row[1] import_value = data_row[2] print(f"{year} 年,出口额:{export_value},进口额:{import_value}") save_to_excel(trade_data) # 将数据保存到Excel if __name__ == "__main__": main()
,Best Wish 不负年华
