


Apache Paimon
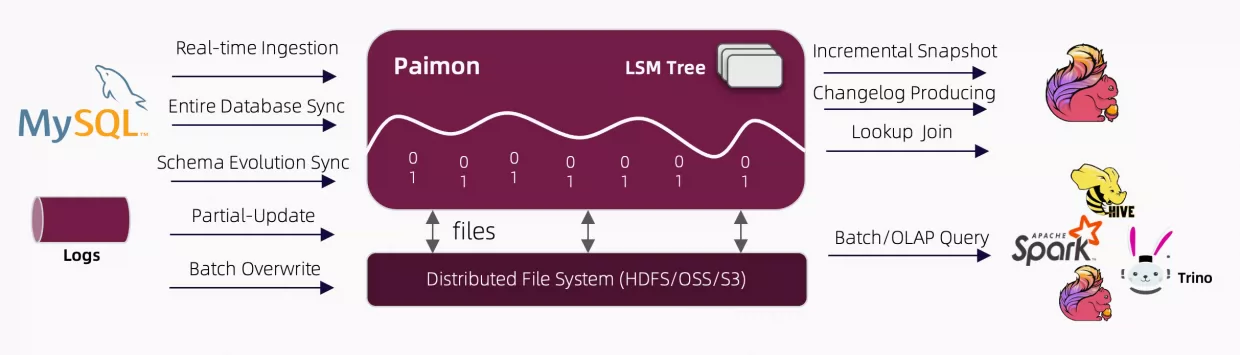
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
Apache Paimon 在同程旅行的探索实践-阿里云开发者社区 (aliyun.com)
在千万数据规模下使用全量 + 增量一体化同步 MySQL 订单表到 Paimon明细表、下游计算聚合及持续消费更新的能力。整体流程如下图所示,其中 MySQL 需要提前准备 ,需要下载 Flink 包及 Paimon相关依赖,TPC-H 数据生成器。
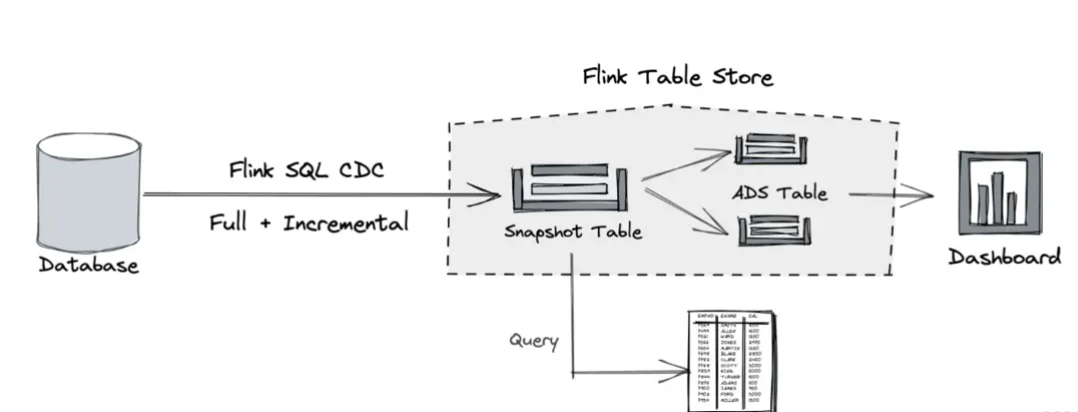
得益于 LSM 数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
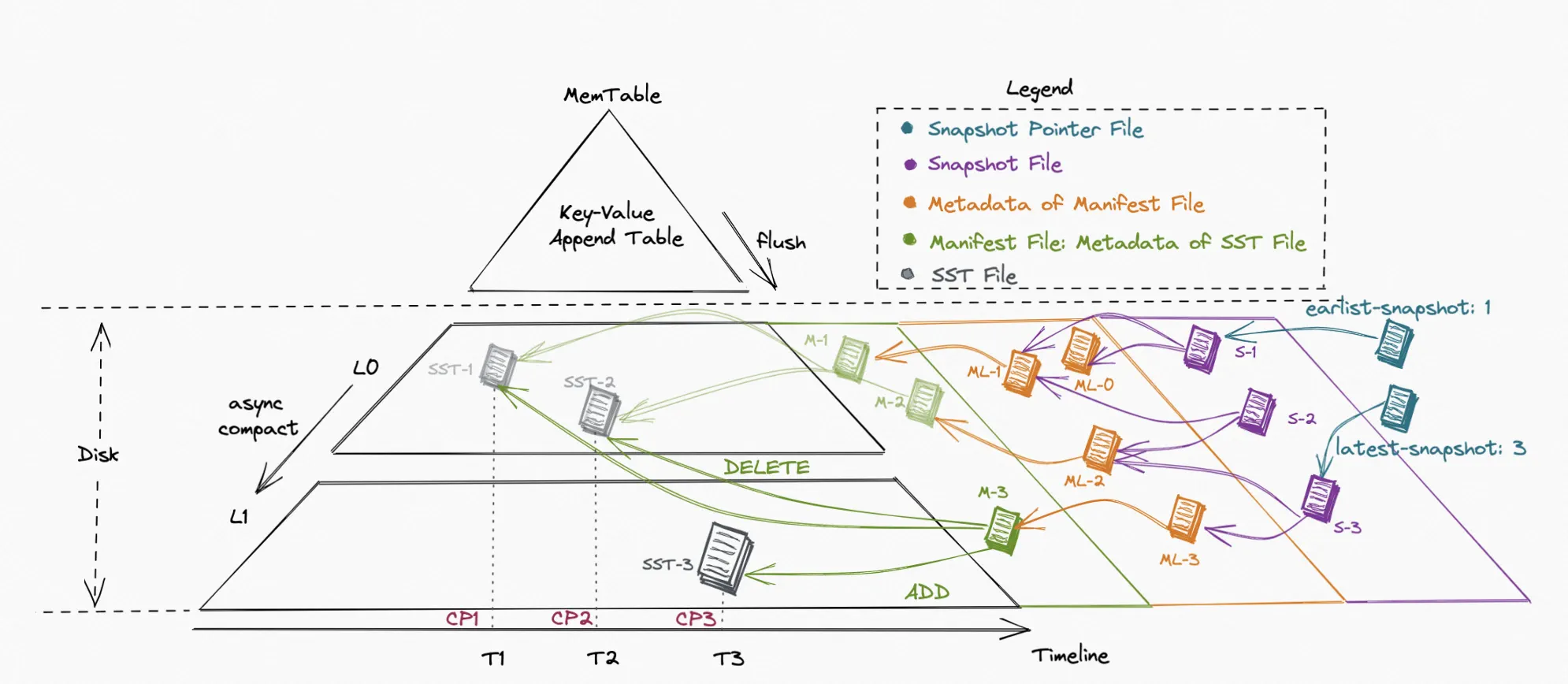
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:
在数据仓库的业务场景下,经常会用到宽表数据模型,宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
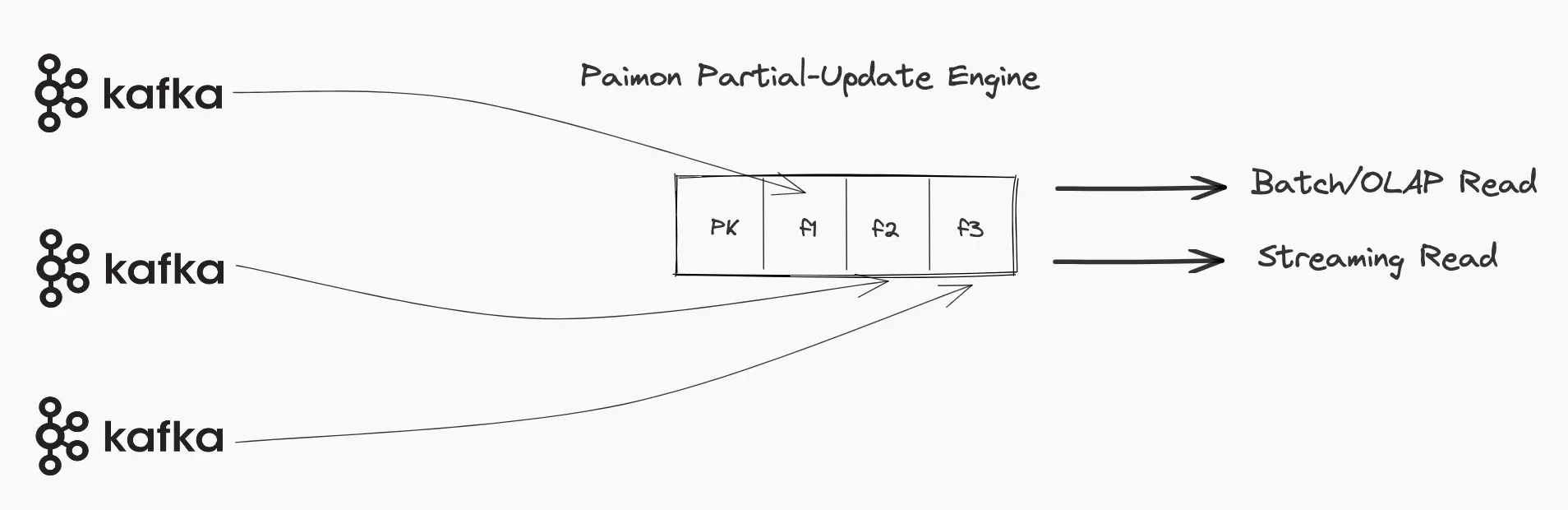
Paimon 的 Partial-Update 合并引擎可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表,依靠 LSM 的延迟 Compaction 机制,以较低的成本完成合并。合并后的表可以提供批读和流读:
- 批读:在批读时,读时合并仍然可以完成 Projection Pushdown,提供高性能的查询。
- 流读:下游可以看到完整的、合并后的数据,而不是部分列。
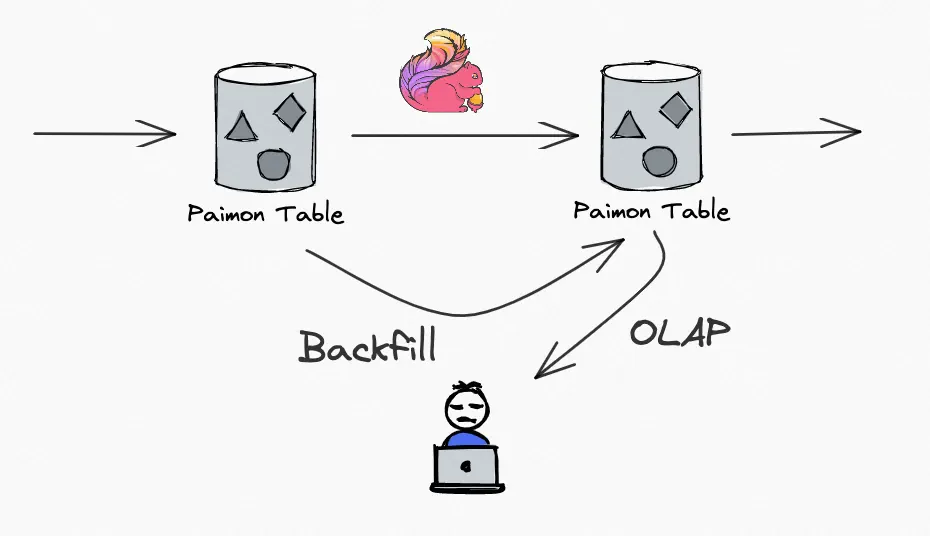
Paimon 作为一个流批一体的数据湖存储,提供流写流读、批写批读,你使用 Paimon 来构建 Streaming Pipeline,并且数据沉淀到存储中。
在 Flink Streaming 作业实时更新的同时,可以 OLAP 查询各个 Paimon 表的历史和实时数据,并且也可以通过 Batch SQL,对之前的分区 Backfill,批读批写。
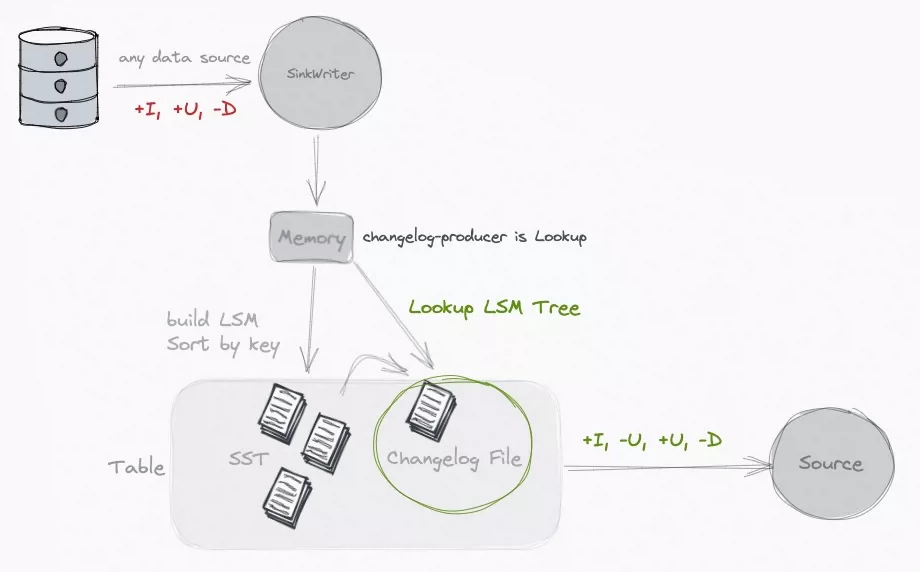
当面对主键表时,为什么你需要完整的 Changelog:
- 你的输入并不是完整的 changelog,比如丢失了 UPDATE_BEFORE (-U),比如同个主键有多条 INSERT 数据,这就会导致下游的流读聚合有问题,同个主键的多条数据应该被认为是更新,而不是重复计算。
- 当你的表是 Partial Update,下游需要看到完整的、合并后的数据,才可以正确的流处理。
你可以使用 Lookup 来实时生成 Changelog:
https://github.com/apache/incubator-paimon
ChatGPT:
Apache Paimon 和 Apache Flink 都属于 Apache 软件基金会开发的开源框架,但是主要用途和功能却有区别。
Apache Flink 是一种流处理框架,它能够快速和高效地处理实时数据流,能够对流数据进行有状态的计算、窗口处理、数据流转换等等,主要用于数据流计算和处理应用。
Apache Paimon 则是一种数据处理与存储组件,它提供了一种分层存储结构,能够支持从数据采集、清洗、存储、索引到搜索等一系列数据处理操作。它依托于 Apache Kafka 平台,帮助用户更好地处理和存储大量实时数据,并且能够将数据快速有效地提供给下游应用程序。
因此,Apache Paimon 和 Apache Flink 虽然都可以用来处理实时数据,但是 Apache Paimon 更偏重于数据处理与存储的能力,而 Apache Flink 则更偏重于流处理的能力。
Mondrian和Apache Paimon以及Apache Kylin三者区别:
Mondrian、Apache Pinot和Apache Kylin是OLAP(联机分析处理)引擎,而Apache Paimon是一个查询优化引擎。
Mondrian是一个OLAP引擎,它要求使用它的应用程序必须使用Mondrian API和查询语言(MDX)来查询多维数据集。Mondrian由Java编写,是一个开源项目。
Apache Pinot是一个分布式OLAP引擎,支持实时和离线多维数据分析。它是为处理大型数据集和快速数据查询而设计的。
Apache Kylin是一个OLAP引擎,它可以提供自己的REST API和SQL接口,支持使用SQL查询和维度模型,支持多维数据集分析。Apache Kylin还提供自己的Cubing Job,它可以运行在Hadoop和Spark上,能够在离线和在线数据上执行数据预处理。
Apache Paimon是一个查询优化引擎,用于优化查询调用和并发查询处理。它提供了异步查询处理,可以明显提高查询性能。
总的来说,这些引擎都可以用于多维数据集分析,但它们的实现机理和特点不同,以满足不同的数据需求。Mondrian是一个单机的OLAP引擎,Apache Kylin和Apache Pinot支持分布式OLAP分析,而Apache Paimon则着重于查询优化和并发查询处理。

