

第八节,tf.estimator
参见https://www.cnblogs.com/marsggbo/p/11232897.html、https://yuanmingqi.blog.csdn.net/article/details/84111065
前言:Estimator 是 一种可极大地简化机器学习编程的高阶 TensorFlow API
Estimator 的优势:
1)Estimator 会自行构建计算图,开发先进模型更简单
2)在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改 重新编码模型。
3)Estimator 提供安全的分布式训练循环,可以控制如何以及何时:
构建图、初始化变量、开始排队、处理异常、创建检查点文件并从故障中恢复、保存 TensorBoard的摘要。
4)使用Estimator开发,必须将数据输入管道从模型中分离出来,以简化不同数据集的实验流程。


import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D att = np.float32(np.random.rand(100, 2)) label = 2 * att[:, 0] + 3 * att[:, 1] + 1 # 将数据存为NPZ文件,方便之后读取 np.savez('blog.npz', att=att, label=label) data = np.load('blog.npz') ax = Axes3D(plt.figure()) X, Y = np.meshgrid(data['att'][:, 0], data['att'][:, 1]) Z = 2 * X + 4 * Y + 3 ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=plt.cm.hot) ax.contourf(X, Y, Z, zdir='z', offset=-1, camp=plt.cm.hot) ax.set_title('The distribution of the data') ax.set_ylabel('z') ax.set_xlabel('y') ax.set_zlabel('z') plt.show()
import tensorflow as tf import numpy as np # 创建一个二维的特征列 feature_columns = tf.feature_column.numeric_column('feature1', shape=[2]) def network(x, feature_column): """ :purpose: 定义模型结构,这里我们通过tf.layers来实现 :param x: 输入层张量 :return: 返回前向传播的结果 """ net = tf.feature_column.input_layer(x, feature_column) net = tf.layers.Dense(units=100)(net) net = tf.layers.Dense(units=100)(net) net = tf.layers.Dense(units=1)(net) return net def my_model_fn(features, labels, mode, params): """ :purpose: 模型函数 :param features: 输入函数中返回的数据特征 :param labels: 数据标签 :param mode: 表示调用程序是请求训练、预测还是评估 :param params: 可传递的额外的参数 :return: 返回模型训练过程需要使用的损失函数、训练过程和评测方法 """ # 定义神经网络的结构并通过输入得到前向传播的结果 predict = network(features, params['feature_columns']) # 如果在预测模式,那么只需要将结果返回即可 if mode == tf.estimator.ModeKeys.PREDICT: return tf.estimator.EstimatorSpec(mode=mode, predictions={'result': predict}) loss = tf.reduce_mean(predict - labels) # 定义损失函数 optimizer = tf.train.GradientDescentOptimizer(learning_rate=params['learning_rate']) # 定义优化函数 train_op = optimizer.minimize(loss=loss, global_step=tf.train.get_global_step()) # 定义训练过程 # 定义评测标准,在运行评估操作的时候会计算这里定义的所有评测标准 eval_metric_ops = tf.metrics.accuracy(predict, labels, name='acc') if mode == tf.estimator.ModeKeys.TRAIN: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op, eval_metric_ops={'accuracy': eval_metric_ops}) # 定义评估操作 特别注意这里的eval_metric_ops赋予的值必须是一个字典 if mode == tf.estimator.ModeKeys.EVAL: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops={'accuracy': eval_metric_ops}) # 通过自定义的方式生成Estimator类,这里需要提供模型定义的函数并通过params参数指定模型定义时使用的超参数 # 设置学习率和特征列 model_params = {'learning_rate': 0.01, 'feature_columns': feature_columns} estimator = tf.estimator.Estimator(model_fn=my_model_fn, params=[model_params], model_dir='./logs') def input_fn(): """ :purpose: 输入训练数据 :return: 特征值和标签值 """ data = np.load('blog.npz') dataset = tf.data.Dataset.from_tensor_slices((data['att'], data['label'])).batch(5) iterator = dataset.make_one_shot_iterator() x_data, y_label = iterator.get_next() return {'feature1': x_data}, y_label # after sess.run(), the shape is (5,2) and (5,), the type is ndarray estimator.train(input_fn=input_fn, steps=30000) estimator.evaluate(input_fn=input_fn, steps=200) predictions = estimator.predict(input_fn=input_fn) for item in predictions: print('result is :>', item['result'])
一、 Estimator 的开发步骤
1、创建一个或多个数据集导入函数input_fn():
def input_fn(): data = np.float32(np.random.rand(100, 21, 21, 3)) # shape is (100, 21, 21, 3) label = np.array([x.sum() for x in data]) # shape is (100,) dataset = tf.data.Dataset.from_tensor_slices((data, label)).batch(5) iterator = dataset.make_one_shot_iterator() x_data, y_label = iterator.get_next() return {'feature1': x_data}, y_label
estimator.train(input_fn=input_fn, steps=30000)
每个数据集导入函数input_fn都必须返回两个对象,字典和标签张量 形式为:feature
data = [{"feature1": 2, "features2": 6},
{"feature1": 1, "features2": 5},
{"feature1": 4, "features2": 8}]
label= [2, 3, 4]
创建方式 input_fn = tf.estimator.inputs.numpy_input_fn( x={"feature1":data}, y=y_label, shuffle = True)
参见https://www.cnblogs.com/pied/p/8109498.html
2、定义特征列feature_column
特征列的作用与使用方式https://yuanmingqi.blog.csdn.net/article/details/84111065
feature_columns = tf.feature_column.numeric_column('feature1', shape=[2],normalizer_fn=lambda x: x / 255.0) def network(x, feature_column): net = tf.feature_column.input_layer(x, feature_column) net = tf.layers.Dense(units=100)(net) def input_fn(): …… return {'feature1': x_data}, y_label
本例中label没有作特征列的处理,想想如何应用多个特征列。
3、模型训练、测试与评估
model_params = {'learning_rate': 0.01, 'feature_columns1': [feature_columns1],'feature_cloumns2':[feature_columns2]}
estimator = tf.estimator.Estimator(model_fn=my_model_fn, params=model_params, model_dir='./logs')
def my_model_fn(features, labels, mode, params):
predict = network(features, params['feature_columns'])
……
estimator.train(input_fn=input_fn, steps=30000)
input_fn传递参数到my_model_fn中的features和labels, features是一个dict list,经过多个feature_columns的特征转换。
在model_fn中选择判断行为:
if mode == tf.estimator.ModeKeys.PREDICT: # 'infer'
if mode == tf.estimator.ModeKeys.TRAIN: # 'train'
if mode == tf.estimator.ModeKeys.EVAL: # 'eval'
二、深入理解Estimator
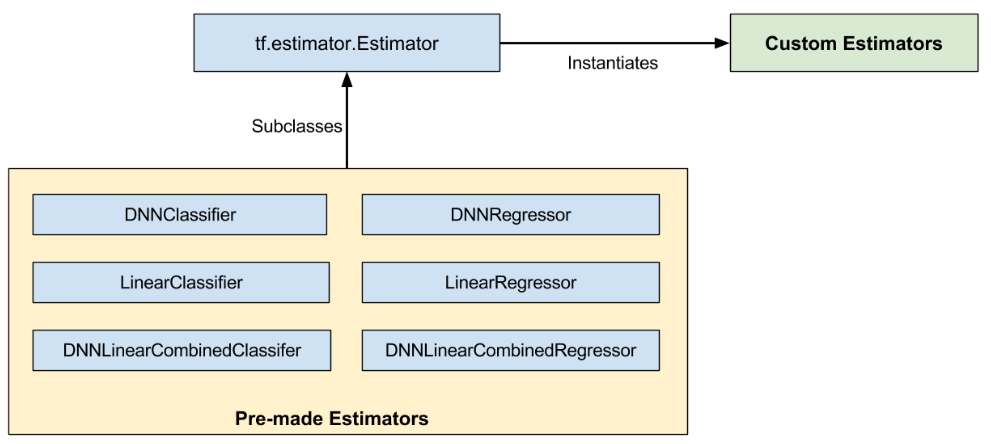
图中的子类面向不同的需求,有不同的初始化函数,记着太乱 详见https://yuanmingqi.blog.csdn.net/article/details/84111601
经常这些子类的model_fn不适配我们需要的功能,需要重构。
class Estimator(object):
def __init__(self, model_fn, model_dir=None, config=None, params=None, warm_start_from=None):

def model_fn(features, labels, mode, params, configs=None)
features和labels是input_fn的返回值。
mode:用于if语句中的tf.estimator.ModeKeys.TRAIN/EVAL/PREDICT判断,该参数不用手动传入,当调用estimator.train(...)时,mode被赋值为'train'。
params:是一个字典,它可以传入许多参数用来构建网络或者定义训练方式等。
config:通常用来控制checkpoint或者分布式什么,这里不深入研究。
return:不管model_fn处在训练/验证/测试的那种模式,都将返回一个tf.estimator.EstimatorSpec实例。
2、config
class RunConfig(object): """This class specifies the configurations for an `Estimator` run.""" def __init__(self, model_dir=None, tf_random_seed=None, save_summary_steps=100, save_checkpoints_steps=_USE_DEFAULT, save_checkpoints_secs=_USE_DEFAULT, session_config=None, keep_checkpoint_max=5, keep_checkpoint_every_n_hours=10000, log_step_count_steps=100, train_distribute=None, device_fn=None, protocol=None, eval_distribute=None, experimental_distribute=None, experimental_max_worker_delay_secs=None, session_creation_timeout_secs=7200):
model_dir 指定存储模型参数,graph等的路径
save_summary_steps 每隔多少step就存一次Summaries,生成event文件 用于tensorboard.
save_checkpoints_steps 每隔多少个step就存一次checkpoint
save_checkpoints_secs 每隔多少秒就存一次checkpoint,不可以和上面同时指定;两者都默认值则每600秒保存一次,两者都None则不保存。
keep_checkpoint_max 指定最多保留多少个checkpoints,当超过数量后删除旧的checkpoints;当置为None或0则保存所有。
log_step_count_steps 指定每隔多少step记录一次loss、global step。
后面的参数与分布式有关!
参考资料(转载):
https://www.cnblogs.com/marsggbo/p/11232897.html
2021-09-06 22:43:20

 浙公网安备 33010602011771号
浙公网安备 33010602011771号