

第七节,tf.feature_column特征预处理
简介:
特征列(feature columns)是原始数据和 Estimator 之间的媒介,特征列形式丰富多样 但需要转换为神经网络唯一可以处理的类型。
常见的特征预处理方法包括:连续变量分箱化、离散变量one-hot、离散指标embedding等。在feature_column接口实现的9种不同的接口函数中,
分别有5种Categorical function(分类函数-返回一个dense Column对象)、3种Numerical function(数值函数-返回一个 Categorical Column 对象) 和1种bucketized_column。
1、Categorical function
①numeric_column(key, shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None )
# shape=(1,)表示一维数据
import tensorflow as tf price = {'price': [[1.], [2.], [3.], [4.]]} # 4行样本 column = tf.feature_column.numeric_column('price', normalizer_fn=lambda x:x*2 + 1) tensor = tf.feature_column.input_layer(price,[column]) with tf.Session() as session: print(session.run([tensor])) # 输出[array([[3.], [5.], [7.], [9.]], dtype=float32)]
②bucketized_column
分箱列 把一个连续的数字范围分成几段。
import tensorflow as tf years = {'years': [1999,2013,1987,2005]} years_fc = tf.feature_column.numeric_column('years') column = tf.feature_column.bucketized_column(years_fc, [1990, 2000, 2010]) # 将年份分成4段 tensor = tf.feature_column.input_layer(years, [column]) with tf.Session() as session: print(session.run([tensor])) # 输出如下

2、Numerical function
①categorical_column_with_vocabulary_list 很多数据都不是数字格式的,于是需要将它(比如一系列商品标签名)数字化

import tensorflow as tf pets = {'pets': ['pig', 'dog', 'cat', 'mouse', 'hadoop']} # 样本 column = tf.feature_column.categorical_column_with_vocabulary_list( key='pets', vocabulary_list=['cat', 'dog', 'rabbit', 'pig'], dtype=tf.string, default_value=-1, num_oov_buckets=0) indicator = tf.feature_column.indicator_column(column) tensor = tf.feature_column.input_layer(pets, [indicator]) with tf.Session() as session: session.run(tf.global_variables_initializer()) session.run(tf.tables_initializer()) print(session.run([tensor]))


len(vocabulary_list)=4,所以箱子总数在 4 到 4+num_oov_buckets之间。当num_oov_buckets=3时,箱子总数可为4,也可为5 6 7。
②categorical_column_with_hash_bucket
hash分箱策略:设分箱总数=50 而总类别数大于50,则按id%50分箱
import tensorflow as tf colors = {'colors': ['green', 'red', 'blue', 'yellow', 'pink', 'blue', 'red', 'indigo']} column = tf.feature_column.categorical_column_with_hash_bucket( key='colors', hash_bucket_size=5, ) indicator = tf.feature_column.indicator_column(column) tensor = tf.feature_column.input_layer(colors, [indicator]) with tf.Session() as session: session.run(tf.global_variables_initializer()) session.run(tf.tables_initializer()) print(session.run([tensor]))
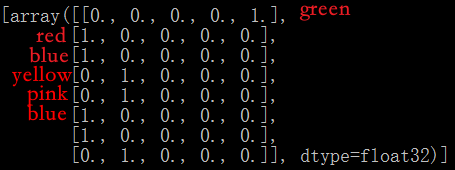
图中red和blue分类到一起了!
③crossed_column
把两个特征分为一个特征。比如经度longitude和纬度latitude合并为一个位置location信息,经度化为100份,纬度化为50份,总共位置就有5000份。
所以先调用以上的其中一种做一维划分,然后合并
import tensorflow as tf featrues = { 'longtitude': [20, 20, 20, 40, 40, 40, 72, 72, 27], 'latitude': [20, 40, 72, 20, 40, 72, 20, 40, 72] } longtitude = tf.feature_column.numeric_column('longtitude') latitude = tf.feature_column.numeric_column('latitude') longtitude_b_c = tf.feature_column.bucketized_column(longtitude, [30, 60]) latitude_b_c = tf.feature_column.bucketized_column(latitude, [30, 60]) column = tf.feature_column.crossed_column([longtitude_b_c, latitude_b_c], 9) indicator = tf.feature_column.indicator_column(column) tensor = tf.feature_column.input_layer(featrues, [indicator]) with tf.Session() as session: session.run(tf.global_variables_initializer()) session.run(tf.compat.v1.tables_initializer()) print(session.run([tensor]))
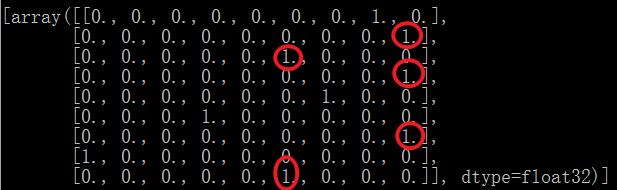 懵逼,什么鬼情况!
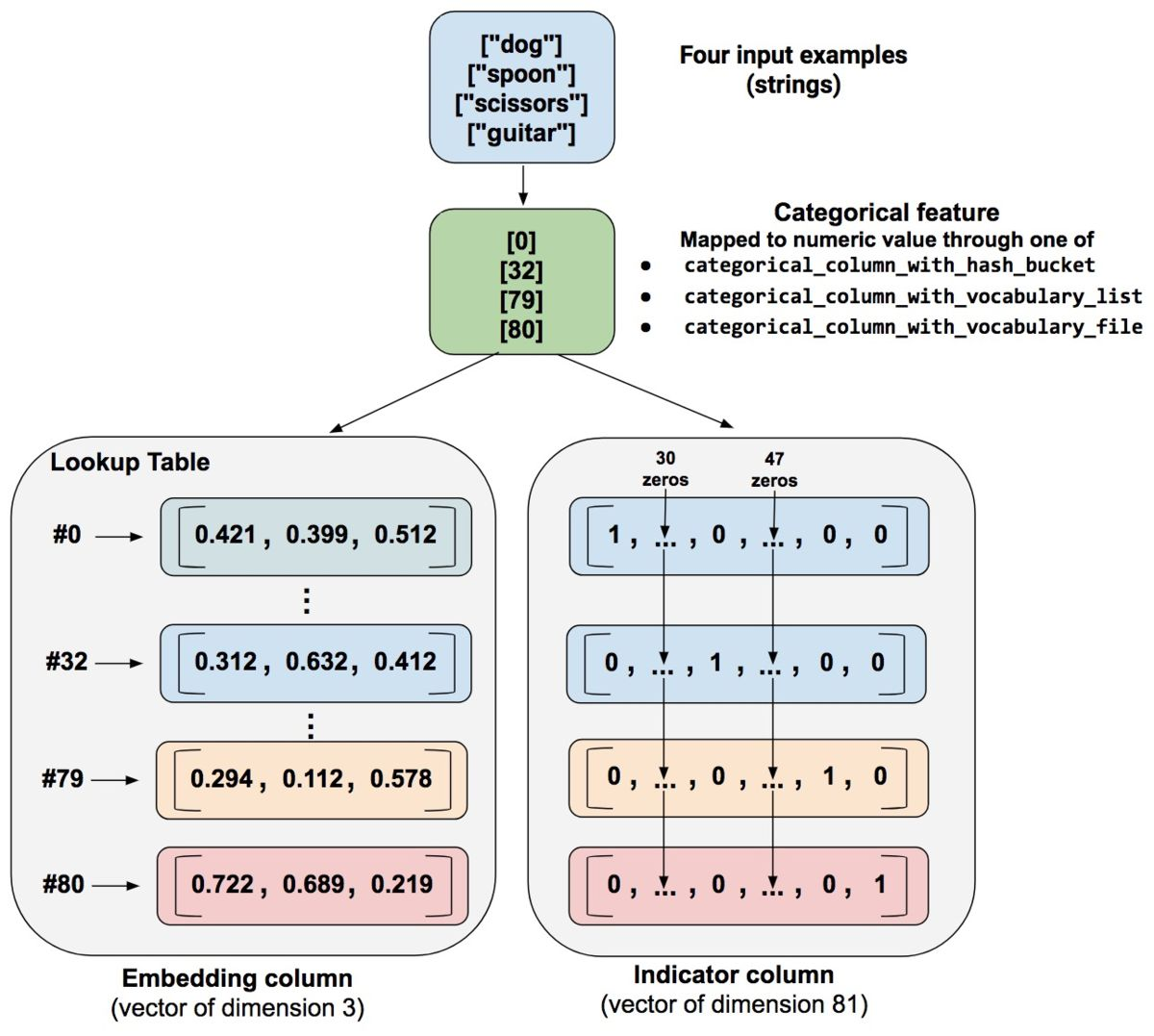
懵逼,什么鬼情况!④embedding_column
对于以上n个类别,一般输出n元01向量,其中一个1和n-1个0。 但当n较大时 输出就不好看了,可以采用embedding_column 把输出向量的元素数减少至![]()
转载:
https://blog.csdn.net/Andy_shenzl/article/details/105145865
https://zhuanlan.zhihu.com/p/118381625
2021-09-06 14:18:04
