一个无锁消息队列引发的血案(六)——RingQueue(中) 休眠的艺术 [续]
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
开篇
这是第五篇的后续,这部分的内容同时会更新和添加在 第五篇:RingQueue(中) 休眠的艺术 一文的末尾。
归纳
紧接上一篇的末尾,我们把 Windows 和 Linux 下的休眠策略归纳总结一下,如下图:
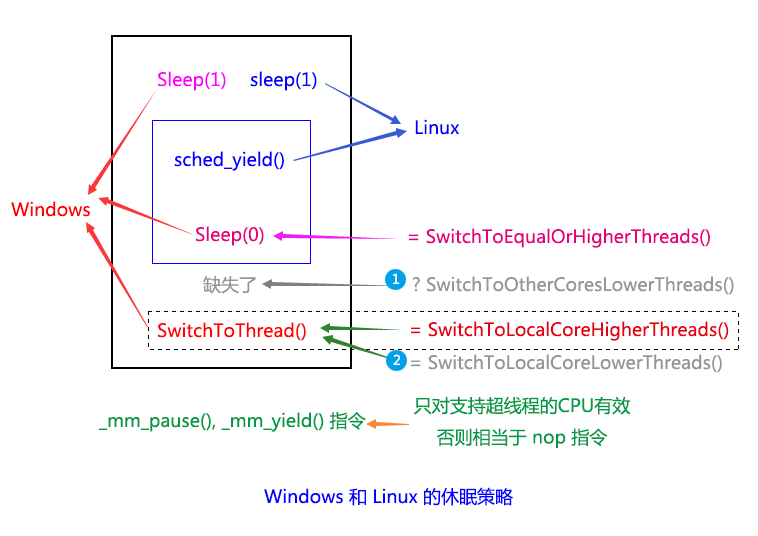
我们可以看到,Linux 下的 sched_yield() 虽然包括了 Windows 下的 Sleep(0) 和 SwitchToThread() 的部分功能(图中蓝色框和虚线框所标注的部分),但缺少了上图中两个灰色文字的功能,即 ① SwitchToOtherCoresLowerThreads() 和 ② SwitchToLocalCoreLowerThreads()(其实这个函数应该包括相同优先级的情况,但由于名字太长,故省略了Equal)。而 Windows 下,则缺失了 ① SwitchToOtherCoresLowerThreads() 这个功能。也就是说,Linux 下面没有切换到低优先级线程的功能,而 Windows 虽然提供了 SwitchToThread(),可以切换到本核心上的低优先级线程,却也依然缺少了切换到别的核心上低优先级线程的能力,即 ① SwitchToOtherCoresLowerThreads() 这个功能。
也就是说,Windows 和 Linux 的策略即使合起来用,依然是不完整的。可是我仔细的想了一下,上面的说法其实是不太正确的。sched_yield() 其实并不是不能切换到低优先级的线程,根据上篇提到 Linux 上的三种不同调度策略,sched_yiled() 是有可能切换到比自己优先级低的线程上的,比如 SCHED_FIFO(先进先出策略)或者 SCHED_RR(轮叫策略刚好轮到低优先级的线程)。只不过,不能特别指定切换到当前线程所在的核心上的其他线程,也就是类似 Windows 上 SwitchToThread() 的功能。
而 Windows 上,虽然看起来好像更完整,却也真正的缺少了切换到别的核心上的低优先级线程的功能,即 ① SwitchToOtherCoresLowerThreads()。
首先来看 Linux 上,缺少了只切换到当前核心的等待线程上的功能,如果切换的线程原来是在别的核心上的,那么有可能会导致切换到的线程所使用的缓存失效,被迫重新加载,导致影响性能。(这个不知道 Linux 的策略是如何选择的,可能要看下源码才能明白,但是有一点是可以肯定的,就算 Linux 在某些调度策略里(比如 SCHED_OTHER,这是普通线程所采用的策略),会优先选择本来就在当前核心上等待的线程,但是当当前核心上没有适合的等待线程的时候,Windows 的 SwitchToThread() 会立刻返回,而 Linux 应该还是会选择别的核心上的其他等待线程来执行;而如果是另外两种调度策略的话,则基本上可能不会优先选择当前核心上的等待线程,尤其是 SCHED_FIFO 策略)。
但从总体上来看,Linux 使用了三种不同的调度策略,是要比 Windows 单一的轮叫循环策略要好一点,至少你有可能通过不同的策略的组合来实现更有效的调度方案。
而 Windows 上虽然在一定程度上有避免这种线程迁移到别的 CPU 核心上运行的可能,却由于缺少切换到别的核心上低优先级线程的功能,而导致策略上的不完整,虽然 Windows 可能可以根据线程饥饿程度来决定要不要切换到这些本不能切换过去的低优先级线程,不过这个过程肯定是比较缓慢的,不太可控的,从而在某些特殊情况下可能会造成某种程度上的“死锁”。
所以 Linux 和 Windows 的调度策略各有千秋,总体上来看,Linux 好像稍微好那么一点,因为毕竟选择要多一些,只要设计得当,情况可能会好一点。但总体上,两者都有不足和缺陷,不够完整。
更完整的调度
那么怎样才能更完整呢?答案可能你也能猜到,通过前面的分析,我们想提供更完整的细节和可控的参数,让调度更完整和随心所欲。也就是根据我们的想法,指哪打哪,想切去哪就切去哪,无孔不入。我们需要一个更强大的接口,这个接口应该要考虑几乎所有可能的情况,功能强大而不失灵活性,甚至有些时候还会有一定的侵略性。我们只是提供一个接口,具体怎么玩,玩成什么样,我们不管,玩崩了那是程序员自己的事情(崩倒是应该不会,但是可能会混乱)。
我们把这个接口暂时定义为 scheduler_switch()(本来想叫 scheduler_switch_thread(),还是短一点好),函数模型大致为:
int scheduler_switch(pthread_array_t *threads, pthread_priority_t priority_threshold, int priority_type, cpuset_t cpu_mask, int force_now, int slice_count);
threads: 表示一组线程,我们从这一组线程里,通过后面的几个参数一起来决定最终选择切换到哪一个线程,该线程必需是处于准备就绪状态的,即会把已经在运行的线程排除掉。该值为 NULL 时表示从系统所有的等候线程里挑选,即跟 sched_yield() 默认的行为一致。
priority_threshold:表示线程优先级的阀值,由后面的 priority_type 来决定是高于这个阀值、低于这个阀值、等于这个阀值或者大于等于这个阀值,等等。该值为 -1 时表示使用当前线程的优先级。
priority_type: 决定 priority_threshold 的比较类型,可分为:>,<,==,>=,<= 等类型。
cpu_mask: 允许切换到的 CPU 核心的 mask 值,该值为 0 时表示只切换到线程当前所在的核心,不为 0 时,每一个 bit 位表示一个 CPU 核心,该值类似 CPU 亲缘性的 cpuset_t 。
force_now: 为 1 时,表示指定的切换线程立刻获得时间片,而不受系统优先级和调度策略的限制,强制运行的时间片个数由 slice_count 参数决定;为 0 时,表示指定切换的线程会等待系统来决定是否立刻得到时间片运行,可能会被安排到一个很短的等候队列里。
slice_count: 表示切换过去后运行的时间片个数,如果为 0 时,则由系统决定具体运行多少个时间片。
返回值: 如果成功切换返回 0,如果切换失败返回 -1(即没有可切换的线程)。
我所说的侵略性是,你可以决定切换以后会持续运行多少个时间片而不会被中断,而且如果你通过 threads 指定的线程组如果没有立刻得到时间片的权力的时候,可以通过 force_now 参数来强制获得时间片,即让系统本来下一个会得到该时间片的线程排在我们指定的线程运行完相应的时间片后再把时间片让给它。如果你指定的 slice_count 值过大,可能会使得其他线程得不到时间片运行,也许这个值应该设置一个上限,比如 100 个或 256 个时间片之类的。
你可以看到,这个接口函数几乎囊括了 Windows 和 Linux 已存在的所有调度函数的功能,并且进行了一定程度的增强和扩展,并且有一定的灵活性,如果你觉得还有不够完整的地方,也可以告诉我。至于如何实现它,我们并不关心,我们只要知道理论上是否可以实现即可,而具体的实现方法可以通过研究 Linux 内核源码来办到。也许并不一定很容易实现,但从理论上,我们还是有可能做得到的。Windows 上由于不开源,我们没什么办法,也许研究 ReactOS 是一种选择,但是 ReactOS 是基于 WindowsNT 内核的,技术可能有些陈旧(注:ReactOS 是一个模仿 Windows NT 和 Windows 2000 的开源操作系统项目,请参考 [wikipedia:ReactOS] )。
Linux 内核
下载 Linux Kernel 源码:
(建议下载 2.6.32.65 和 最新的稳定版 3.18.4,Android 是在 2.6 的基础上修改的,有兴趣也可以直接拿 Android 的内核来改。)
Ubuntu 14.04 LTS 的内核版本是 3.13 (参考:Ubuntu发行版列表)
可参考的文章:
注:通过阅读 Linux 内核的源码,sched_yield() 真正的执行过程并不是我前面描述的那样的,正确的过程应该是:先在当前线程所在的核心上遍历合适的任务线程,如果有的话,就切换到该线程;如果没有的话,目前我还不确定会不会从别的核心上的 RunQueue 迁移任务线程到当前核心来运行,按道理讲应该是这样的。如果是这样,那么 sched_yield() 跟 Windows 的 Sleep(0) 的唯一区别就是:Sleep(0) 不会切换到比自己的优先级别低的线程,而 sched_yield() 可以,Sleep(0) 的策略也应该跟 sched_yield() 类似,先在被核心上找,没有再去别的核心上找。但是,这里我就不修正前面的描述了,请自行注意一下。
因为 3.18.4 的 Linux 改动比较大,也变得复杂了很多,比较难读懂,找 schedule() 函数的位置都花了很大的力气……,因此这里以 2.6 版本的为例。
通过阅读 2.6.32.65 版本的 Linux 内核源码,我们知道实现系统调度的函数是:schedule(void),这跟我们这个接口比较类似,实现的功能也是大致一样。schedule(void) 的功能是从当前核心上的 RunQueue 里找到下一个可运行的任务线程,并切换MMU、寄存器状态以及堆栈值,即通常说的上下文切换(Context Switch)。
通过 /include/linux/smp.h 和 /arch/x86/include/asm/smp.h 或 /arch/arm/include/asm/smp.h,我们可以得知,smp_processor_id() 返回的是 CPU 核心的一个编号,x86 上是通过 percpu_read(cpu_number),arm 上是通过 current_thread_info()->cpu 获得。这样 rq = cpu_rq(cpu); 取得的 RunQueue 就是每个 CPU 核心上独立的运行(任务线程)队列。
/* * schedule() is the main scheduler function. */ asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); cpu = smp_processor_id(); /* 获取当前 CPU 核心编号 */ rq = cpu_rq(cpu); rcu_sched_qs(cpu); prev = rq->curr; switch_count = &prev->nivcsw; release_kernel_lock(prev); need_resched_nonpreemptible: schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); spin_lock_irq(&rq->lock); update_rq_clock(rq); clear_tsk_need_resched(prev); if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) prev->state = TASK_RUNNING; else deactivate_task(rq, prev, 1); switch_count = &prev->nvcsw; } pre_schedule(rq, prev); /* 准备调度? */ if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); put_prev_task(rq, prev); /* 记录之前任务线程的运行时间, 更新平均运行时间和平均overlap时间. */ next = pick_next_task(rq); /* 从最高优先级的线程类别开始遍历, 直到找到下一个可运行的任务线程. */ if (likely(prev != next)) { sched_info_switch(prev, next); perf_event_task_sched_out(prev, next, cpu); rq->nr_switches++; rq->curr = next; ++*switch_count; /* 上下文切换, 同时释放 runqueue 的自旋锁. */ context_switch(rq, prev, next); /* unlocks the rq */ /* * the context switch might have flipped the stack from under * us, hence refresh the local variables. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else spin_unlock_irq(&rq->lock); post_schedule(rq); if (unlikely(reacquire_kernel_lock(current) < 0)) goto need_resched_nonpreemptible; preempt_enable_no_resched(); /* 是否需要重新调度 */ if (need_resched()) goto need_resched; } EXPORT_SYMBOL(schedule);
其中有一个很关键的函数是 pick_next_task(rq),作用是寻找下一个最高优先级的可运行任务。有一点可以确定的是,是优先在本核心上的 RunQueue 上遍历的,但看不太出来是否会在本核心上没有适合的任务线程时,会从别的核心上的 RunQueue 迁移任务过来,这个部分可能要看 struct sched_class 的 pick_next_task() 的实现,这个应该是一个函数指针。pick_next_task(rq) 的源码如下:↓↓↓
/* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ /* fair_sched_class 是分时调度策略, 包括 SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE 三种策略, */ /* 从 __setscheduler() 函数得知. */ if (likely(rq->nr_running == rq->cfs.nr_running)) { p = fair_sched_class.pick_next_task(rq); if (likely(p)) return p; } /* sched_class_highest = &rt_sched_class; 即实时调度策略, */ /* 包括 SCHED_FIFO 和 SCHED_RR, 从 __setscheduler() 函数得知. */ class = sched_class_highest; for ( ; ; ) { p = class->pick_next_task(rq); if (p) return p; /* * Will never be NULL as the idle class always * returns a non-NULL p: */ class = class->next; } }
这个问题我们先打住,以后再研究,或者交给有兴趣的同学去研究,有什么成果的话麻烦告诉我一下。
scheduler_switch()
我们回顾一下 scheduler_switch() 的原型,如下:
int scheduler_switch(pthread_array_t *threads, pthread_priority_t priority_threshold, int priority_type, cpuset_t cpu_mask, int force_now, int slice_count);
这里的 pthread_array_t *threads,表示的一组线程,之所以想设置这个参数,是因为 q3.h 在 push() 和 pop() 的时候,确认提交成功与否的过程是需要序列化的,如果这个过程中的线程调度能够按我们想要的顺序调度,并且加上适当的休眠机制的话,可能可以减少竞争和提高效率。
请注意下面代码里第 22 和 23 行:
1 static inline int 2 push(struct queue *q, void *m) 3 { 4 uint32_t head, tail, mask, next; 5 int ok; 6 7 mask = q->head.mask; 8 9 do { 10 head = q->head.first; 11 tail = q->tail.second; 12 if ((head - tail) > mask) 13 return -1; 14 next = head + 1; 15 ok = __sync_bool_compare_and_swap(&q->head.first, head, next); 16 } while (!ok); 17 18 q->msgs[head & mask] = m; 19 asm volatile ("":::"memory"); 20 21 /* 这个地方是一个阻塞的锁, 对提交的过程进行序列化, 即从序号小的到大的一个个依次放行. */ 22 while (unlikely((q->head.second != head))) 23 _mm_pause(); 24 25 q->head.second = next; 26 27 return 0; 28 }
因为这里第 22, 23 行并没有休眠策略,直接是在原地自旋,在竞争比较激烈,且间隔时间很短的情况下(评价一个竞争的状况有两个参数,一个是多少人在竞争,另一个参数是产生竞争的频率,即间隔多久会产生一次竞争。竞争者越多,而且竞争间隔也很短的话,那么代表竞争是非常激烈的,我们这里的情况就是这样),没有休眠策略很可能导致互相激烈的争抢资源,而且也会让 q3.h 在 push() 和 pop() 总线程数大于 CPU 核心总数的时候,产生介于 ”活锁” 和 “死锁” 之间的这么一种异常状态的问题。此时,队列推进非常慢,而且有多慢似乎有点看脸,有时候可能要一分钟或几分钟不等。
如果这个时候,能够把还没轮到的线程先休眠,然后按次序依次唤醒(是按照我们自己的 sequence 序号 head 来唤醒,而不是线程自己进入休眠状态的顺序,因为从第 16 行结束到第 22 行,这里的执行顺序是不确定的,有可能序号大的线程先执行到第 22 行,而序号小的因为线程被挂起了,因而晚一点才执行到第 22 行,所以唤醒的时候是依据我们自己的序号 head 从小到大依次唤醒)。但是这样也会出现一个问题,就是当某个核心正在运行的线程(我们设这个CPU 核心为 X,线程为A)执行到第 22 行时,由于序号 head 大于 q->head.second 很多,那么需要切换到别的线程或者进入休眠状态。如果此时选择切换,此时 head = q->head.second 的线程(我们设这个线程为B)会被选取且被唤醒,可是问题来了,这个有时间片的 CPU 核心 X 很可能不是 head = q->head.second 这个的线程 B 原来所在的核心(我们设这个核心为 Y),如果要唤醒的话则需要从原来的核心 Y 迁移到当前的核心 X 来,这当然不是我们想看到的,如果可以在核心 Y 上执行线程 B,这是最理想的选择了。如果可以的话,我们会中断核心 Y 上正在运行的线程 C,然后把时间片交给线程 B 来运行。依此类推,那么有可能下一个被唤醒的线程也不在当前拥有时间片的 CPU 核心上,那么又将导致类似的中断。如果这种中断太多,那么效率自然也会受到一定影响。所以,如果有一个更好的统筹规划方法就再好不过了,可是,似乎这样的规划策略不太好实现。
要么我们允许线程频繁的迁移,或者我们可以按某个比例允许两种情况都出现,例如:0.4的概率允许被唤醒的线程迁移到当前的核心,0.6的概率不迁移,采用打断要唤醒的线程所在的核心的方式(总的概率为1.0)。或者我们允许一次唤醒两个相邻的线程(指序号 head 邻近),我们设这两个线程分别为线程 A 和 B,那么当 A 通过之后,紧接着就是该唤醒 B 了,我们让线程 B 早一点唤醒,然后让其自旋并等待通过(这其实跟现在的 q3.h 很像,不同的是我们加了休眠策略,是可以应付任意线程数的 push() 和 pop() 的)。而且如果两个线程原来所在的核心刚好交叉的话,即线程 A 原来是在核心 X 上的,线程 B 原来是在核心 Y 上的,现在核心 Y 的线程在请求 sched_yield(),现在要唤醒的线程是 A 和 B,那么我们让 B 在核心 Y 上运行,并且打断核心 X 上的线程,让其运行线程 A。当然,我们会先执行打断的过程,让线程 A 在核心 X 上运行,然后再在核心 Y 上切换到线程 B 运行,如果可以这么安排先后的话,如果不能这样做,两者同时进行也是可以的。如果不是交叉的话,也增加了两个线程中的其中一个可能在它原来的核心上的机率。
我们为什么没有在 pthread_array_t *threads 这一组线程上使用先进先出的队列呢,一是前面说过的,像 q3.h 这个问题,线程进入休眠的顺序不一定是我们想要的顺序,第二个原因是,像我们这个问题,本身就是一个 FIFO 队列问题,里面再套一个 FIFO 队列似乎也不合理。但是,的确有些时候还是需要这种 FIFO 的 threads 的,也不矛盾,我们让先进入的序号值比后进入的序号值小即可。为了简化逻辑,我们可以用固定数组存储元素(事先必需先指定队列大小),用两个单向链表来实现插入和遍历的方法,一个是active_list,另一个是free_list,遍历的时候使用序号做为选择的依据,从而变成一个按序号大小顺序出列的队列。
警告:其实这个部分感觉有点画蛇添足,不过我写了就不准备删了,有一部分也是我曾经思考过的东西,只是写出来好像没有想象中的理想,但可以做为一个思考的方向。
其实在 写完上一篇 到 准备写这篇文章之前 的某一天,我看到了这么一篇文章,《条件变量的陷阱与思考》,也可以说是及时雨,感觉好像跟我的文章能沾上一点边,我因此而特意查看了 glibc 源码里关于 pthread_cond_xxxx() 部分的相关代码,对条件变量有了进一步的认识。由于没深入研究,只是觉得条件变量的实现并不是想象中的那么简单,至少它整个机制跟我前面提到的唤醒进制是不太一样,我们总想实现一个完美的唤醒机制,事实上可能很难实现我们心中那最完美的方式,因为有些东西在多线程编程中是不可调和的。同时因为 POSIX 规范为了简化实现,使用的时候跟 Windows 是有很些区别的。看了这篇文章后,才发现我原来对 pthread 的条件变量理解并不到位,原本以为跟 Windows 的 Event (事件) 很类似,虽然我知道一些两者的区别,主要集中在 CreateEvent() 的手动和自动模式, PulseEvent() 和 pthread_cond_broadcast() 之间的区别。由于我从没真正的使用过它,所以真正的区别是看了这篇文章才知道的,最大的区别主要来自于实现的逻辑,POSIX 规范为了简化实现,条件变量必须跟一个 pthread_mutex_t 配合使用才能正确发生作用,这跟 Windows 的 WaitForSingleObject() 和 ResetEvent() 是有些不同的,Windows 上的 Event 相关函数内部已经包含了这个互斥操作了,相当来说比较直观和易用一些,但 pthread_cond_t 更灵活一些。
也许你会说,既然我们可能在内核里用 scheduler_switch(),为什么参数的定义却用了 pthread 的类型,其实如果原理实现了,改成内核的 kthread,或者内核和 pthread 分别实现两套函数,也是可以的,这不是大问题。
设计 scheduler_switch() 这个东西是“启发式”的,我们的目的是想让休眠策略能够更完整的为我们服务,如果能改进则更好,实现不了或不好实现也不打紧,也算是抛砖引玉,希望对你有所启发。
待续
感谢你的阅读,如果你觉得写得不错的话,麻烦点一下推荐,或者评论一下,这样下次你找这个文章就可以从首页的 “我赞” 和 “我评” 里面找到了。
RingQueue
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下载UTF-8编码版:https://github.com/shines77/RingQueue-utf8。 我敢说是一个不错的混合自旋锁,你可以自己去下载回来看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,还支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等。
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
上一篇:一个无锁消息队列引发的血案(五)——RingQueue(中) 休眠的艺术
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号