
分库分表
分库分表
什么是ShardingSphere
Apache ShardingSphere是一款分布式的数据库生态系统。可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
详细见官网详解
什么是ShardingSphere-JDBC
ShardingSphere-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。
产品功能
| 特性 | 定义 |
|---|---|
| 数据分片 | 数据分片,是应对海量数据存储于计算的有效手段,可水平扩展计算和存储 |
| 分布式事务 | 事务能力,是保证数据库完整。安全的关键技术 |
| 读写分离 | 应对高压力业务访问的手段 |
| 数据加密 | 保证数据安全的基本手段 |
| 数据迁移 | 打通数据生态的关键能力。 |
| .... | .... |
产品优势
- 极致性能
- 生态兼容
- 业务零侵入
- 运维低成本
- 安全稳定
- ...
ShardingSphere与SpringBoot 集成
- 引入Maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
创建distribute_db.t_order_0和distribute_db.t_order_1
CREATE TABLE `t_order_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`status` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表'
CREATE TABLE `t_order_1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`status` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表'
策略配置
分表策略
spring:
shardingsphere:
# 定义数据源名称ds0
datasource:
names: ds0
ds0:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/distribute_db
username: root
password: 123456
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 逻辑表名称
t_order:
# 由数据源名+表明组成(参考inline语法规则):{0..1}表示0~1
actualDataNodes: ds0.t_order_${0..1}
# 分表策略
tableStrategy:
standard:
# 分表字段
shardingColumn: id
# 分表算法表达式
shardingAlgorithmName: t_order_inline
# 分布式id生成策略
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sharding-algorithms:
t_order_inline:
type: inline
props:
# 举例,如id%2==0,存储到t_order_0;id%2==1,存储到t_order_1
algorithm-expression: t_order_${id % 2}
# 配置分布式主键生成算法,指定为雪花算法
key-generators:
snowflake:
type: SNOWFLAKE
# 打印sql
props:
sql-show: true
验证水平分表
OrderDao
@Mapper
public interface OrderDao {
@Insert("insert into t_order (user_id, status) values (#{userId}, #{status})")
void insertOrder(@Param("userId")Integer userId,@Param("status")Integer status);
@Select("select * from t_order where id = #{id}")
Map<String,Object> selectOrderById(@Param("id")Long id);
}
测试类
@Test
public void insertOrderOne(){
orderDao.insertOrder(1,1);
}
如遇报错内容为Cause by:Caused by:java.lang.NoSuchMethodErrarCreate breakpoint :org.apache.shardingsphere,infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.setCodePointLimit(I)V
添加依赖
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
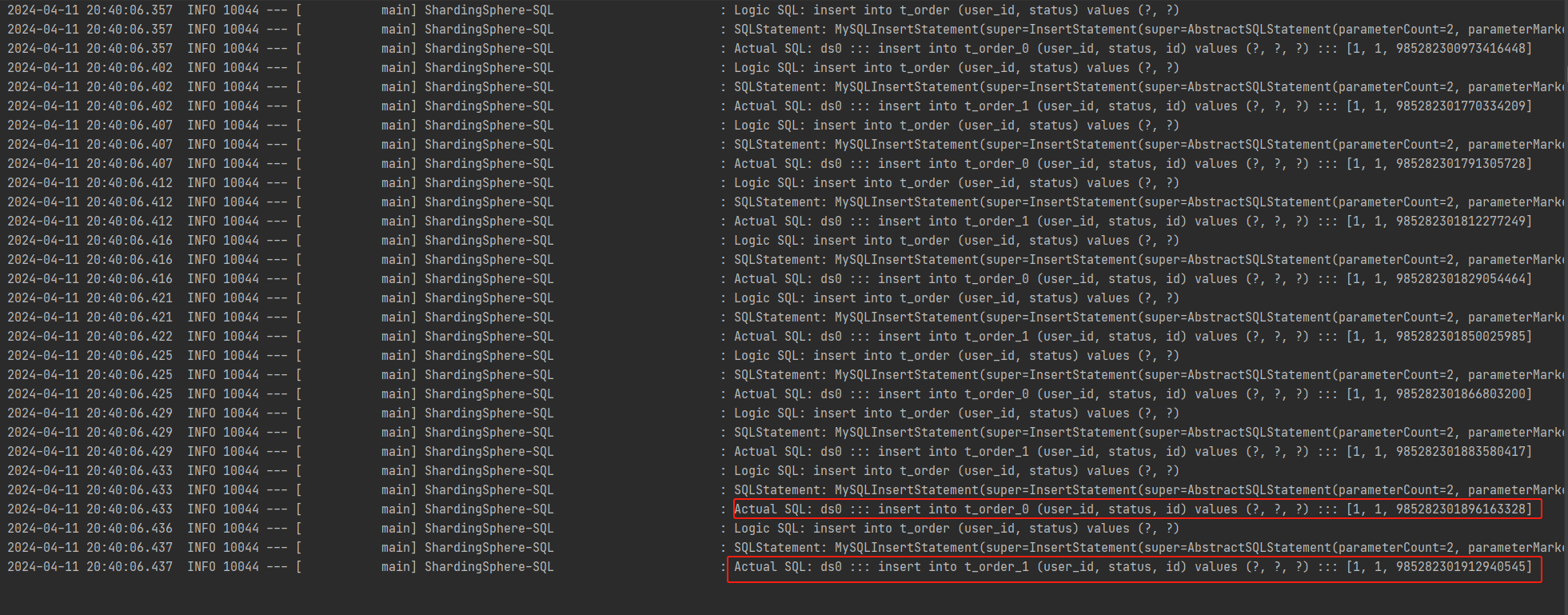
再次插入记录,查看输出日志

从日志中,可以看到主键记录为985280812100354048的记录被插入到t_order_0中。
借助for循环插入更多记录
@Test
public void insertOrder() {
for (int i = 0; i < 10; i++) {
orderDao.insertOrder(1,1);
}
}
@Select("select * from t_order where id = #{id}")
Map<String,Object> selectOrderById(@Param("id")Long id);
查看记录插入的记录985282301912940545
@Test
public void testSelectOrder(){
System.out.println(orderDao.selectOrderById(985282301912940545L));
}

分库策略
水平分表
新建数据库distribute_db2,使用user_id字段取余进行分库判断。user_id % 2==0,存放在distribute_db,否则distribute_db2
创建新的建表语句
create database `distribute_db2`;
use distribute_db2;
CREATE TABLE `t_order_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`status` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=985282301912940546 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表';
CREATE TABLE `t_order_1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`status` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=985282301912940546 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表'
配置规则
spring:
application:
name: distribute-db
shardingsphere:
datasource:
names: ds0,ds1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/distribute_db
username: root
password: 123456
# 添加分库数据源信息
ds1:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/distribute_db2
username: root
password: 123456
rules:
sharding:
tables:
t_order:
actualDataNodes: ds${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: t_order_inline
# 添加分库策略
database-strategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: t_order_user_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
sharding-algorithms:
t_order_inline:
type: inline
props:
algorithm-expression: t_order_${id % 2}
# 添加分库策略,按照user_id%2区分ds0,ds1
t_order_user_inline:
type: inline
props:
algorithm-expression: ds${user_id % 2}
key-generators:
snowflake:
type: SNOWFLAKE
props:
sql-show: true
批量插入数据
@Test
public void insertOrder() {
for (int i = 0; i < 10; i++) {
orderDao.insertOrder(i,1);
}
}
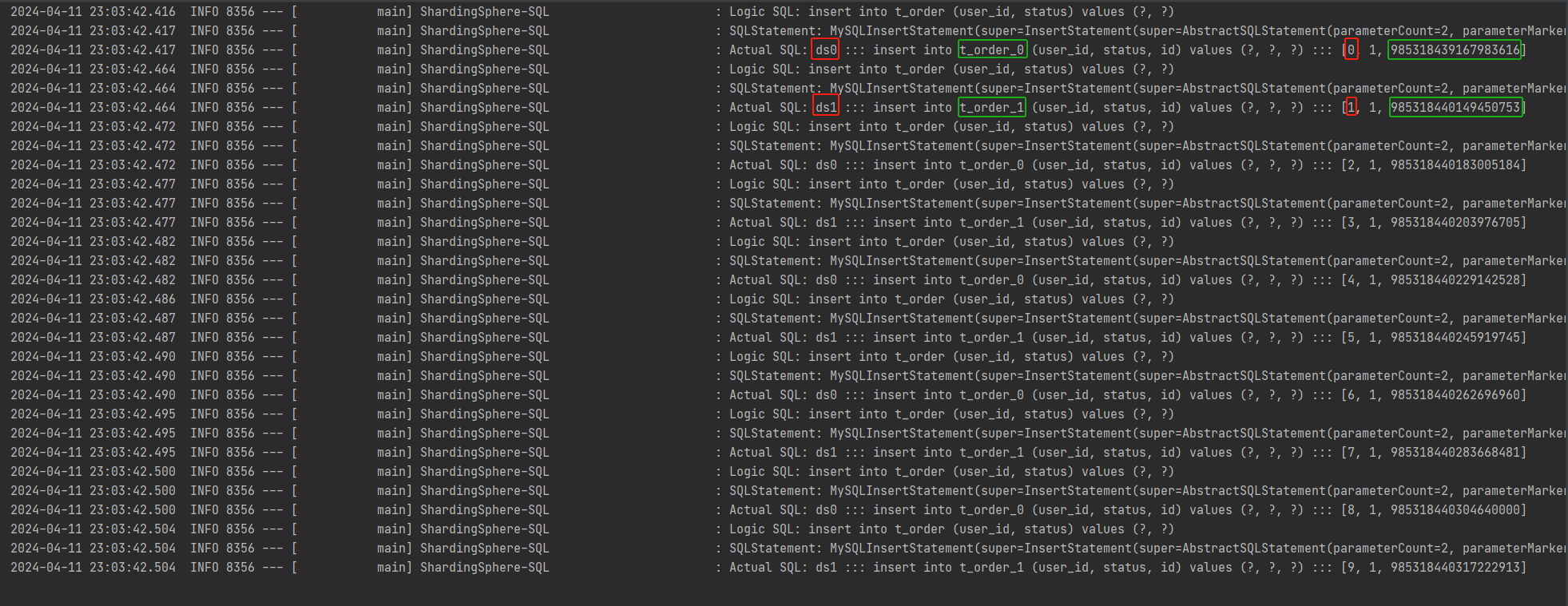
观察日志信息,可以看到按照user_id和order_id的差异,放入不同数据源中。
- 根据user_id查询记录
@Select("select * from t_order where user_id =#{userId}")
Map<String,Object> selectOrderByUserId(@Param("userId")Integer userId);
@Test
public void testSelectOrderByUserId(){
System.out.println(orderDao.selectOrderByUserId(0));
}
根据user_id为0只能定位到在ds_0数据源中,但无法定位实在t_order_0表还是t_order_1表中,因此执行union all连表查询。

- 如果根据user_id + order_id组合查询
@Select("select * from t_order where id = #{id} and user_id = #{userId}")
Map<String,Object> selectOrderByIdAndUserId(@Param("id")Long orderId,@Param("userId")Integer userId);
@Test
public void testSelectOrderByIdAndUserId(){
System.out.println(orderDao.selectOrderByIdAndUserId(985318439167983616L,0));
}
根据user_id和order_id可以唯一定位数据源及表信息,因此无连表查询


 浙公网安备 33010602011771号
浙公网安备 33010602011771号