
线程池
线程池——治理线程的法宝
1. 线程池的自我介绍
-
线程池的重要性
-
什么是池
-
软件中的“池”,可以理解为计划经济
-
如果不使用线程池,每个任务都新开一个线程处理
- 一个线程
- for循环创建线程
- 当任务数量上升到1000
-
这样的开销太大,我们希望有固定数量的线程,来执行这1000个线程,这样就避免了反复创建并销毁线程所带来的开销问题
-
为什么要使用线程池
问题一:反复创建线程开销大
问题二:过多的线程会占用太多内存
- 解决以上两个问题的思路
- 用少量的线程——避免内存占用过多
- 让这部分线程都保持工作,且可以反复执行任务——避免生命周期的损耗
线程池的好处
- 加速响应速度
- 合理利用CPU和内存(灵活配置达到性能最佳状态)
- 统一管理
线程池适合应用的场景
- 服务器接受到大量请求时,使用线程池技术是非常合适的。它可以大大减少线程的创建和销毁次数,提搞服务器的工作效率。
2. 创建和停止线程
线程池构造函数的参数
| 参数名 | 类型 | 含义 |
|---|---|---|
| corePoolSize | int | 核心线程数 |
| maxPoolSize | int | 最大线程数 |
| KeepAliveTime | long | 保持存活时间 |
| workQueue | BlockQueue | 任务存储队列 |
| ThreadFactory | ThreadFactory | 当线程池需要新的线程的时候,会使用threadFactory来生成新的线程 |
| Handler | RejectExecutionHandler | 由于线程池无法接收新提交的任务的拒绝策略 |
- corePoolSize:指的是核心线程数,线程池在初始化后,默认情况下,线程池中并没有任何线程,线程池会等待有任务到来时,在创建新线程去执行任务。
- maxPoolSize:线程池有可能会在核心线程数的基础上,额外增加一些线程,但是这些新增加的线程数有一个上限,这就是最大量maxPoolSize。
- KeepAliveTime:如果线程池当前的线程数多于corePoolSize,那么多于的线程空闲时间超过KeepAliveTime,它们就会终止。

如上图所示,core Pool Size为初始化线程池容量大小,随着线程数量的增加,当前线程数会增加,直到等于最大线程数。
添加线程规则

如果用流程图来描述如下图
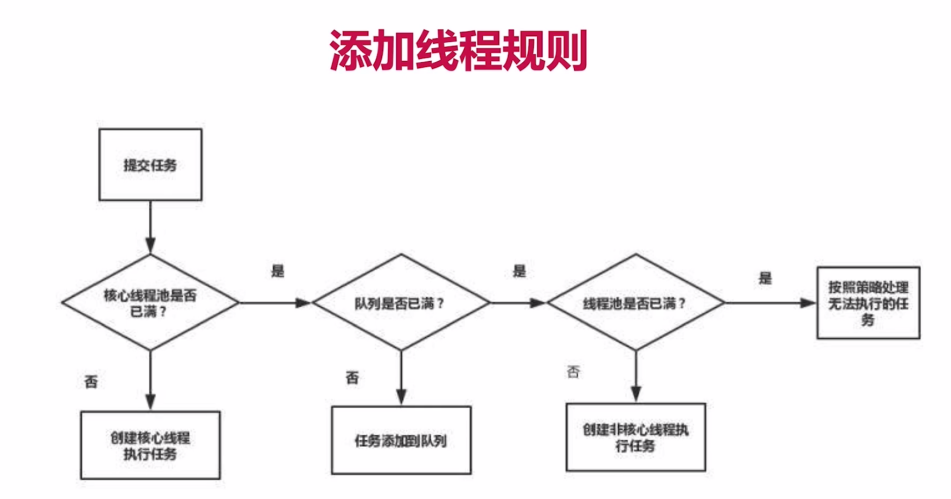
根据上图可知,是否需要增加线程的判断顺序是:
- corePoolSize
- workQueue
- maxPoolSize

增减线程的特点
- 通过设置corePoolSize和maximumPoolSize相同,就可以创建固定大小的线程池。如newFixThreadPool
- 线程池希望保持较少的线程数,并且只有在负载变得很大时才增加它。
- 通过设置maximumPoolSize为很高的值,例如 Integer.MAX_VALUE。才可以允许线程池容纳任意数量的并发任务。
- 只有在队列填满时才创建多于corePoolSize的线程,所以如果使用的是无界队列(例如LinkedBlockQueue),那么线程数就不会超过corePoolSize。

- ThreadFactory:新的线程是由ThreadFactory创建的,默认使用Executors.defaultThreadFactor(),创建出来的线程都在同一个线程组,拥有同样的NORM PRIORITY优先级并且都不是守护线程。如果自己指定ThreadFactory,那么就可以改变线程名、线程组、优先级、是否是守护线程等。

-
WorkQueue工作队列
- 直接交换:SynchronousQueue,maxPool需要设置大一些,无队列作为缓冲。
- 无界队列:LinkedBlockingQueue,若处理速度 < 存放队列速度,一直存放,会OOM。
- 有界队列:ArrayBlockingQueue,

线程池应该手动创建还是自动创建
-
正确的创建线程池的方法
- 根据不同的业务场景,自己设置线程池参数,比如我们的内存有多大,我们想给线程池取什么名字等等。
线程池里的线程数量设定为多少比较合适
-
CPU密集型(加密、计算Hash等):最佳线程数为CPU核心数的1-2倍左右。
-
耗时IO型(读写数据库、文件、网络读写等):最佳线程数一般会大于cpu核心数很多倍,以IVM线程监控显示繁忙情况为依据,保证线程空闲可以衔接上,参考Brain Goetz推荐的计算方法:
线程数=CPU核心数*(1+平均等待时间/平均工作时间)
停止线程池的正确方式
3. 常见线程池的特点和用法
FixedThreadPool
- 由于传进去的LinkedBlockingQueue是没有容量上限的,所以当请求越来越多,并且无法及时处理完毕的时候,也就是请求堆积的时候,会容易造成大量的内存,可能会导致OOM。`
正常执行的状态
/**
* 演示 newFixedThreadPool
*/
public class FixedThreadPoolTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}
class Task implements Runnable{
@Override
public void run() {
//休眠500毫秒
try{
Thread.sleep(500);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
执行结果:打印出来的线程编号一直是pool-1-thread-1~4
pool-1-thread-1
pool-1-thread-3
pool-1-thread-2
pool-1-thread-4
pool-1-thread-2
pool-1-thread-4
pool-1-thread-1
pool-1-thread-3
pool-1-thread-4
pool-1-thread-1
pool-1-thread-2
pool-1-thread-3
....
OOM的状态
/**
* 演示 newFixedThreadPool出错的情况
*/
public class FixedThreadPoolOOM {
private static ExecutorService executorService = Executors.newFixedThreadPool(1);
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(new SubThread());
}
}
}
class SubThread implements Runnable{
@Override
public void run() {
try{
Thread.sleep(1000000000);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
一个线程执行Integer.MAX_VALUE次,并且线程睡眠时间长,处理<存储队列中的速度
newSingleThreadExector
- 可以看出,这里和刚才的newFixedThreadPool的原理基本一样,只不过把线程数直接设置成了1,所以这也会导致同样的问题,也就是当请求堆积的时候,可能会占用大量的内存。
正常状态
public class SingleThreadExecutor {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}
class Task implements Runnable{
@Override
public void run() {
//休眠500毫秒
try{
Thread.sleep(500);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
执行结果;只有一个线程一直执行
pool-1-thread-1
pool-1-thread-1
pool-1-thread-1
pool-1-thread-1
pool-1-thread-1
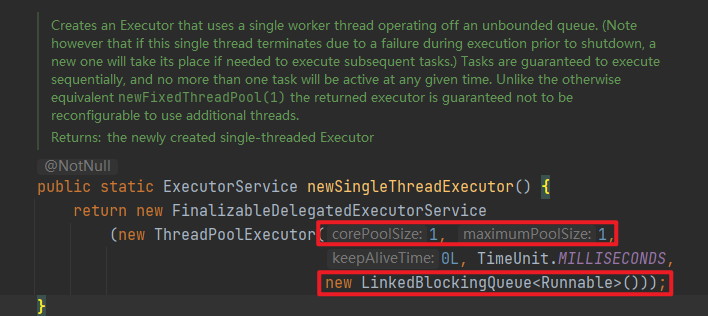
核心数和最大线程数均为1,且使用有界队列作为阻塞队列
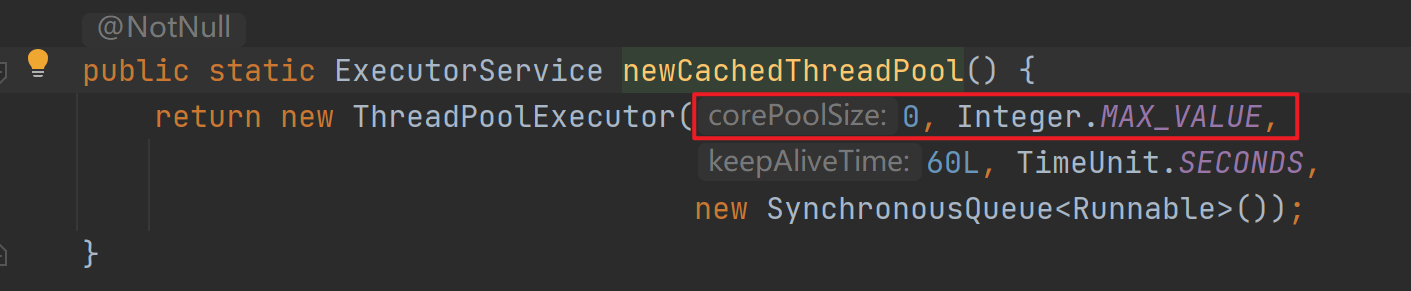
newCachedThreadPool
- 可缓存的线程池
- 特点:无界线程池,具备自动回收多余线程的功能
- 这里的弊端在于第二个参数maximumPoolSizre被设置为了Integer.MAX_VALUE,这可能会创建非常多的线程,甚至导致OOM。
public class CachedThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}
观察线程编号数量比较随意,会创建非常多的线程
pool-1-thread-15
pool-1-thread-7
pool-1-thread-8
pool-1-thread-11
pool-1-thread-3
pool-1-thread-2
pool-1-thread-1
newScheduledThreadPool
- 支持定时及周期性任务执行的线程池
/**
* 跟时间相关,推迟相关的特点
*/
public class ScheduledThreadPoolTest {
public static void main(String[] args) {
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(10);
// 每隔5秒执行一次
// threadPool.schedule(new Task(),5, TimeUnit.SECONDS);
// 期初执行1次,每隔3秒钟执行
threadPool.scheduleAtFixedRate(new Task(),1,3,TimeUnit.SECONDS);
}
}
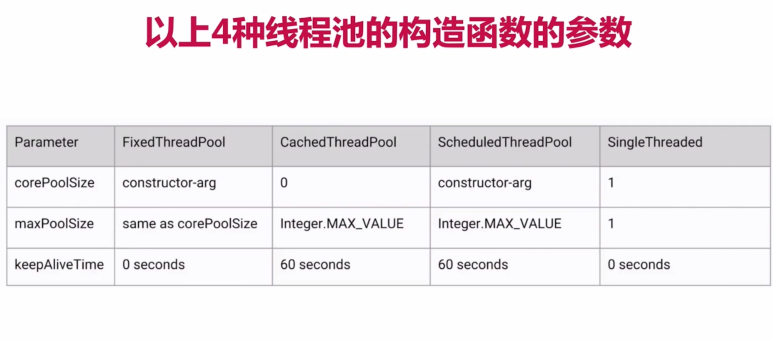
4种线程池的构造函数的参数
阻塞队列分析
Fix和SIngle的Queue是LinkedBlockingQueue?
新来的数量无法估计,所以将阻塞队列作为无限
CacheThreadPool使用的是SynchronusQueue?
不需要存储,任务过来直接在新线程中执行
ScheduledThreadPool来说,它使用的是延迟队列DelayedWorkQueue
WorkStrelingPool
- 这个线程池和之前的都有很大不同
- 子任务
- 拥有一定的窃取能力,线程之间可以合作 map-reduce
4.任务太多,怎么拒绝
- 拒绝时机
- 当Executor关闭时,提交新任务会被拒绝
- 当Executor对最大线程和工作队列使用有限边界并且已经饱和时
四种拒绝策略
- AbortPolicy:直接抛出异常
- Discardpolicy:默默丢弃,不抛出异常
- DiscardOldestPolicy:直接丢弃任务,不予处理也不抛出异常
- CallerRunsPolicy:调用者线程处理
5.钩子方法,给线程池加点料
6.实现原理、源码分析
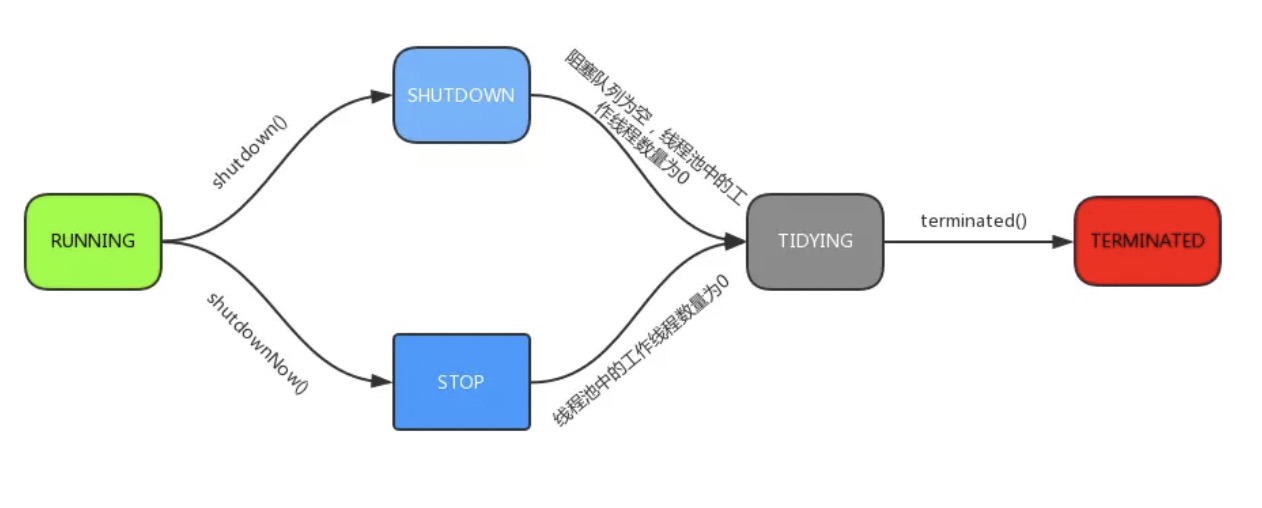
线程池的状态
-
Running:接受新任务并处理排队任务
-
shutdown:不接受新任务,但处理排队任务
-
stop:不接受新任务,也不处理排队任务,并中断正在进行的任务
-
tidying:整洁。
-
terminated:terminate()运行完成。
线程流转如下:
7. 使用线程池的注意点
- 避免任务的堆积
- 避免线程数过度增加
- 排查线程泄露

 浙公网安备 33010602011771号
浙公网安备 33010602011771号