
MySQL中常见的坑
MySQL中常见的坑
表属性设置为NULL,你可能要面临很多麻烦
为什么会有很多人用NULL呢
- NULL是默认行为
- 一个很严重的误区
- NULL属性非常方便


NULL列存在的问题/容易引起的BUG的特性

-- 不要使用 NULL 字段
CREATE TABLE `imooc_mysql_escape`.`do_not_use_null` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`one` varchar(10) NOT NULL,
`two` varchar(20) DEFAULT NULL,
`three` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_one` (`one`),
KEY `idx_two` (`two`),
UNIQUE KEY `idx_three` (`three`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 初始化一些数据
INSERT INTO `imooc_mysql_escape`.`do_not_use_null`(`id`, `one`, `two`, `three`) VALUES (1, '', 'a2', 'a3');
INSERT INTO `imooc_mysql_escape`.`do_not_use_null`(`id`, `one`, `two`, `three`) VALUES (2, 'b1', NULL, 'b3');
INSERT INTO `imooc_mysql_escape`.`do_not_use_null`(`id`, `one`, `two`, `three`) VALUES (3, 'c1', 'c2', NULL);
INSERT INTO `imooc_mysql_escape`.`do_not_use_null`(`id`, `one`, `two`, `three`) VALUES (4, 'd1', 'd2', NULL);
NULL的长度并不是0
NULL参与的查询
我应该用什么去代替NULL呢?

不在随意设置数据类型,不给未来留隐患
选择列的数据类型,先从主键开始
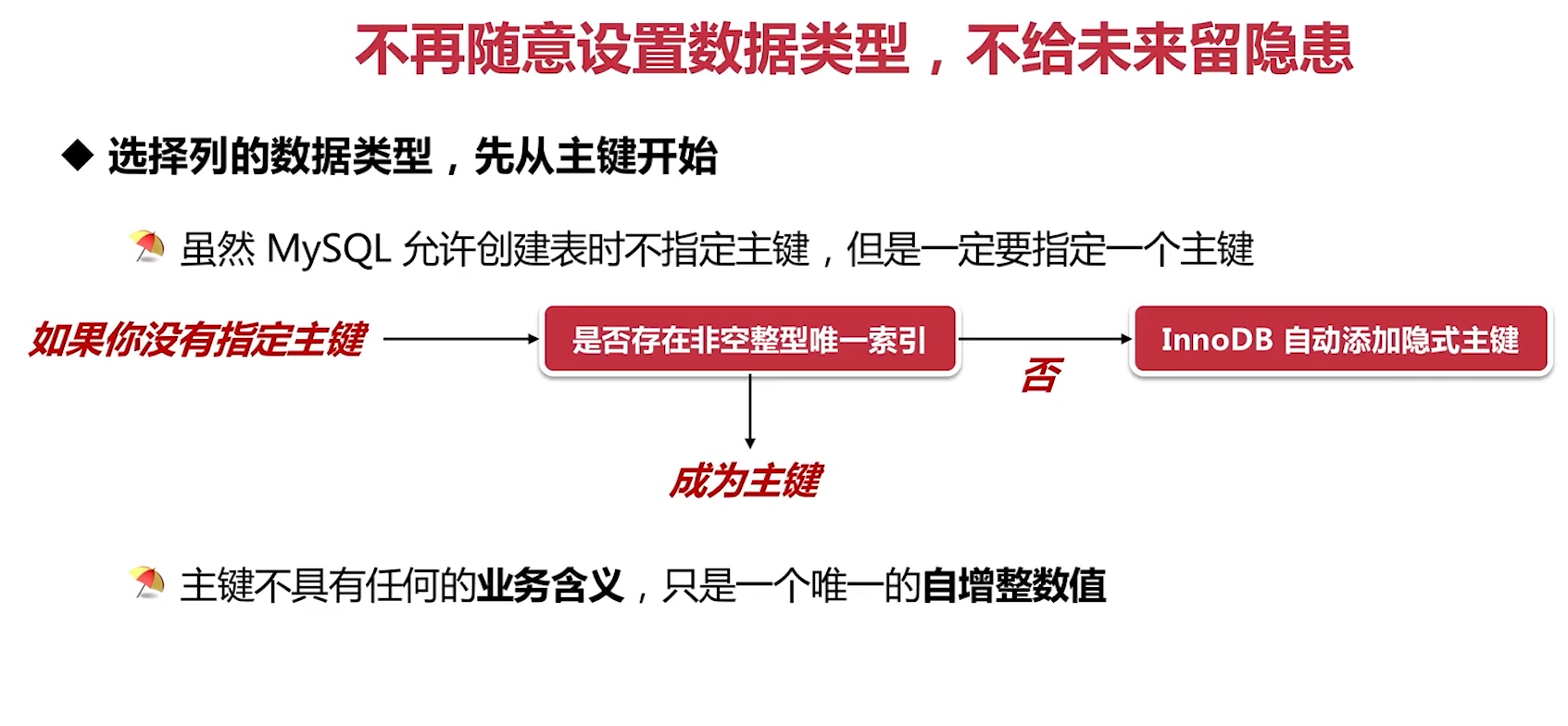
选择合适的数据类型以及恰当的范围

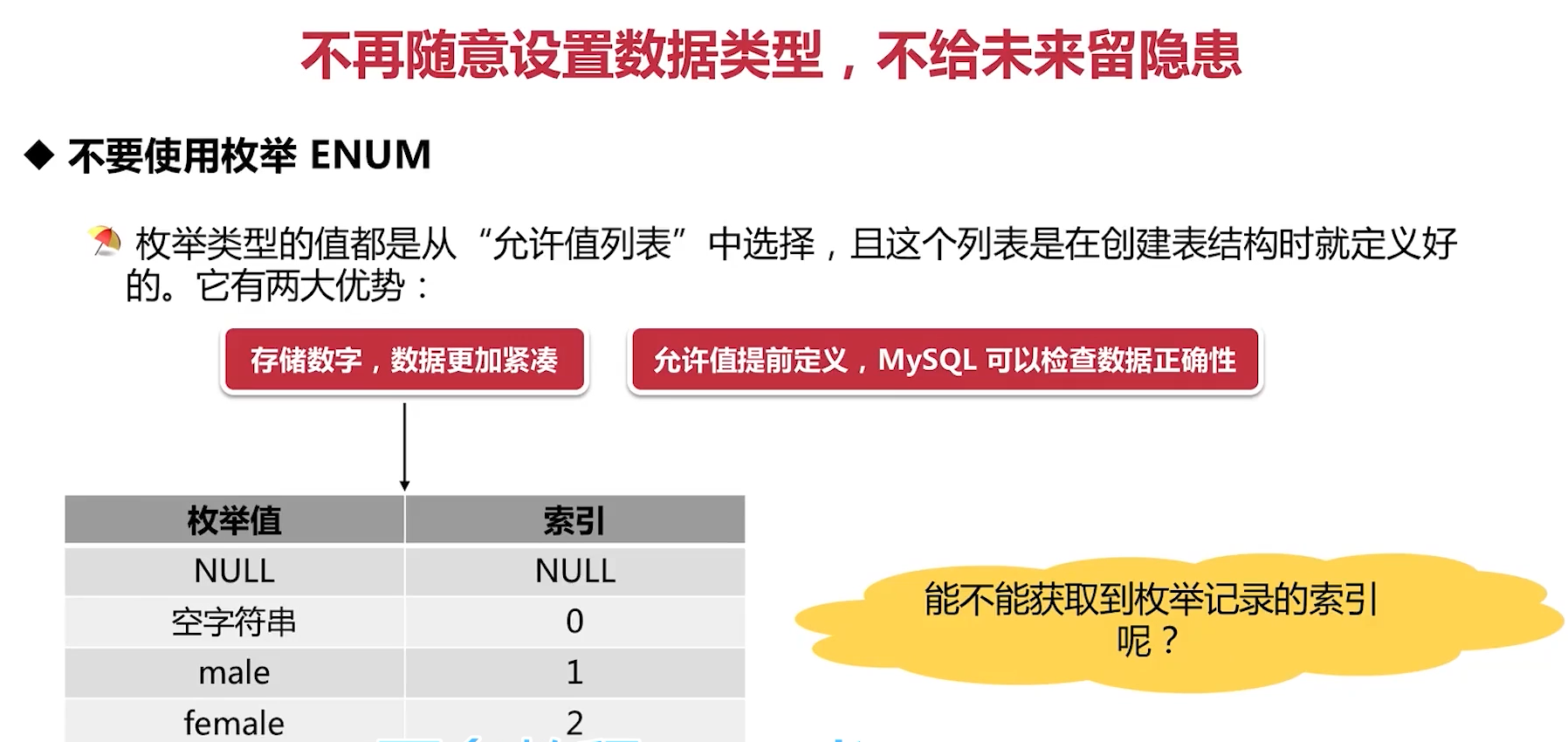
不要使用枚举Enum

索引加的不好,效果可能适得其反
- 字符串类型在查询时没有使用引号,不会使用索引
- where条件左边的(属性列)字段参与了函数或者数学运算,不会使用表索引
- 联合索引最左前缀顺序不匹配,不会使用索引

测试样例表结构信息
CREATE TABLE `imooc_escape`.`correct_use_index` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
`phone` varchar(64) NOT NULL,
`email` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_phone` (`phone`),
KEY `idx_name_phone_email` (`name`, `phone`, `email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
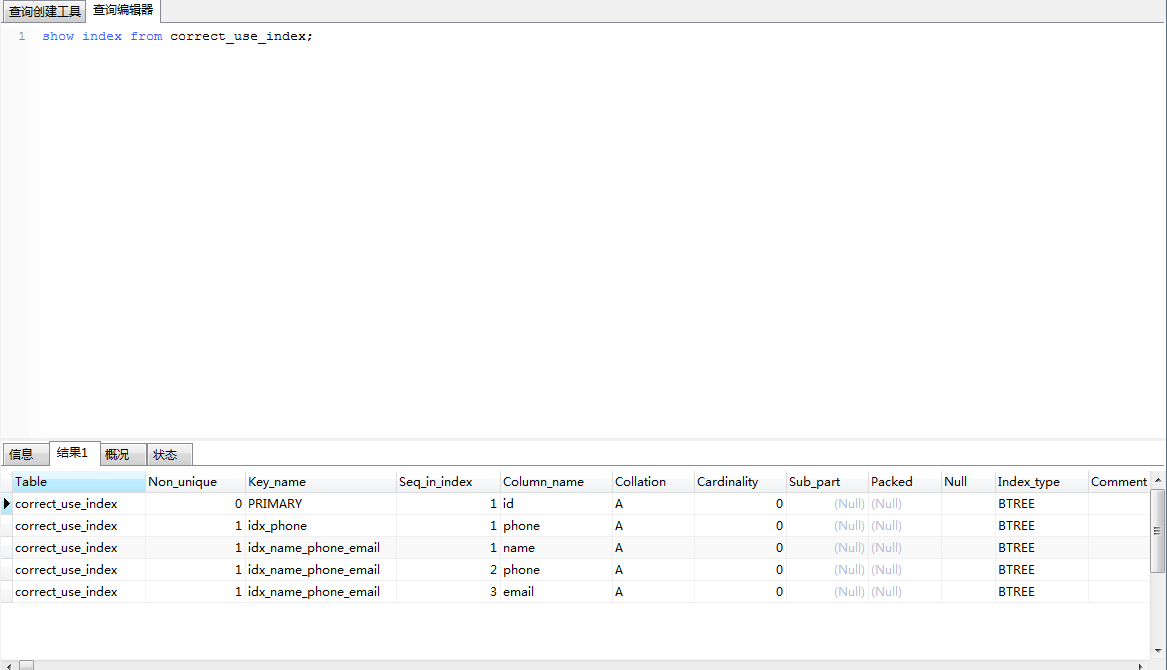
表中有三个索引,主键索引id, phone字段级索引,联合主键索引 name_phone_email。
-- 字符串类型查询没有使用引号(手机号码)
explain select * from correct_use_index where phone = 17012345678;
explain select * from correct_use_index where phone = '17012345678';
执行第一条,执行结果如下
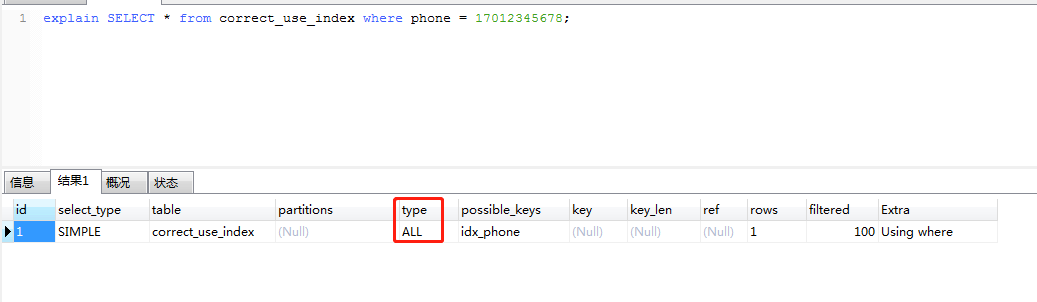
由于phone并没有使用字符, MYSQL需要先将传入的值从数字转为字符,放弃了走索引。
执行第二条,执行结果如下
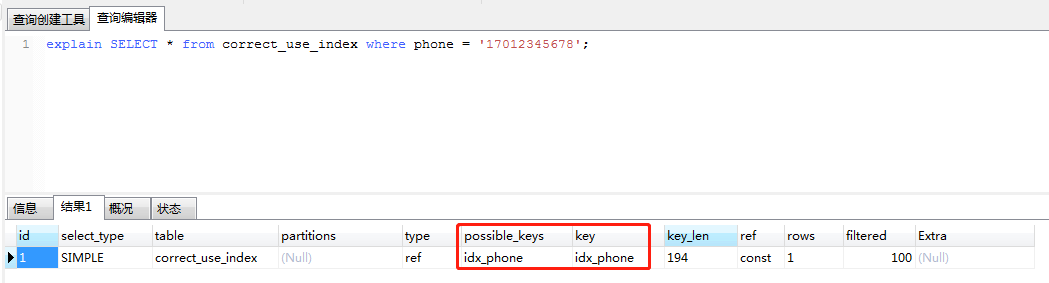
可能使用的索引是idx_phone,实际执行走的索引也是idx_phone
where条件左边的(属性列)字段参与了函数或者数学运算,不会使用表索引
-- where 条件左边的字段参与了函数或者数学运算
explain select * from correct_use_index where concat(name, '-qinyi') = 'imooc-qinyi';
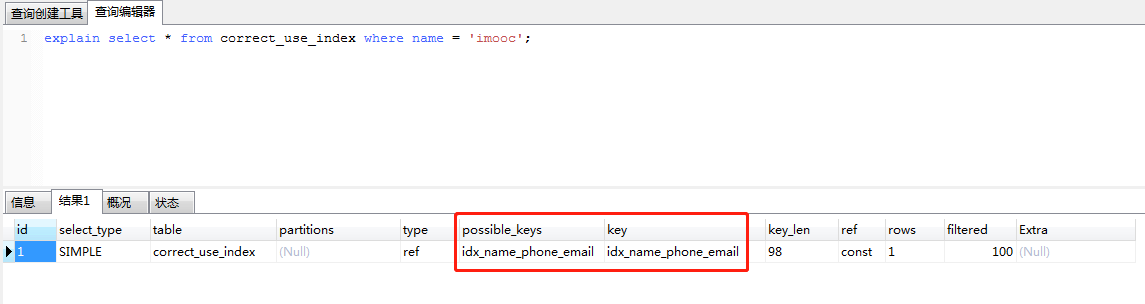
explain select * from correct_use_index where name = 'imooc';
对于第一条,对带索引字段name进行拼接字符后 与'imooc-qinyi'进行函数上比较相等,name在联合索引上。由于查询语句上使用了函数计算,因此放弃了索引
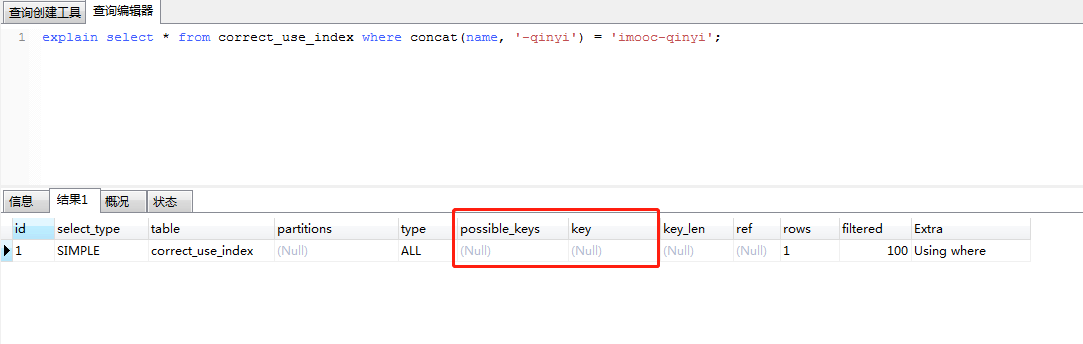
对于第二条,对第一条语句进行优化,将对比值放在后面进行计算。发现走联合索引
对于索引字段,使用数学运算,同样不会走索引,如下sql
explain select * from correct_use_index where age - 10 > 0;
执行计划如下
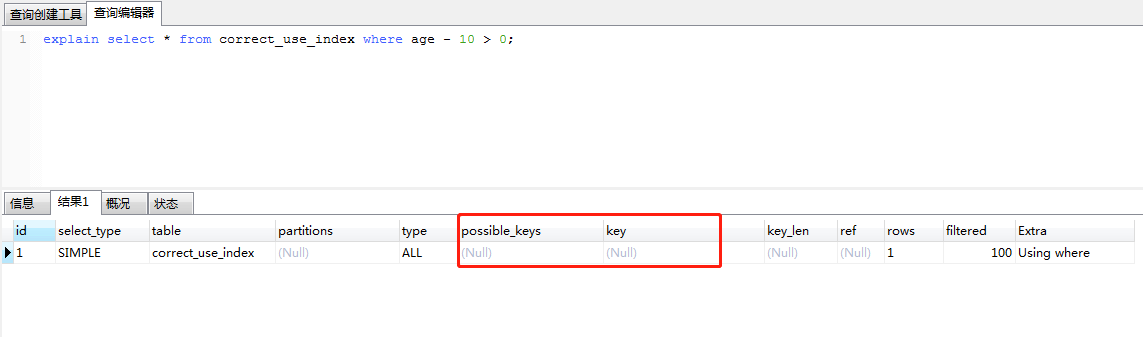
联合索引最左前缀顺序不匹配,不会使用索引
-- 联合索引的前缀使用问题(虽然优化器会重排 where 顺序, 但是, 查询条件最好还是按照定义的联合索引的顺序, 而不是每次顺序都不一样, 这样也会让查询缓存失效, 因为查询语句不一样了)
# 先去掉单主键索引,防止和联合索引有干扰
drop index idx_phone ON correct_use_index;
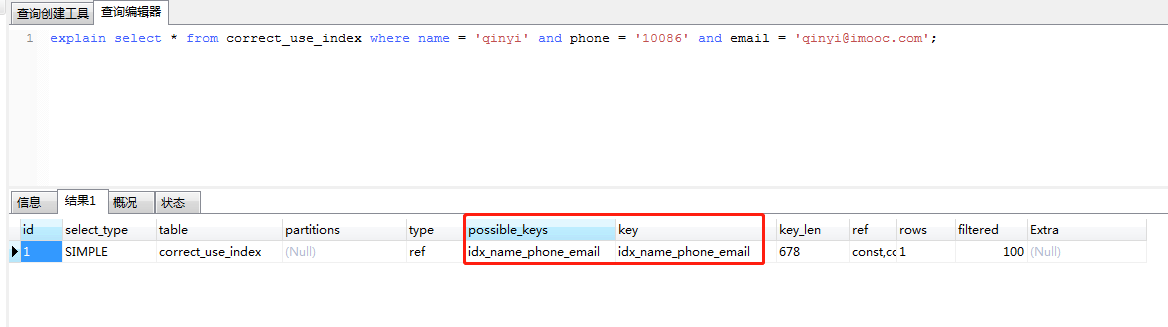
执行如下sql,会按照预期走联合索引,因为按照索引的顺序 a、b、c执行。
explain select * from correct_use_index where name = 'qinyi' and phone = '10086' and email = 'qinyi@imooc.com';
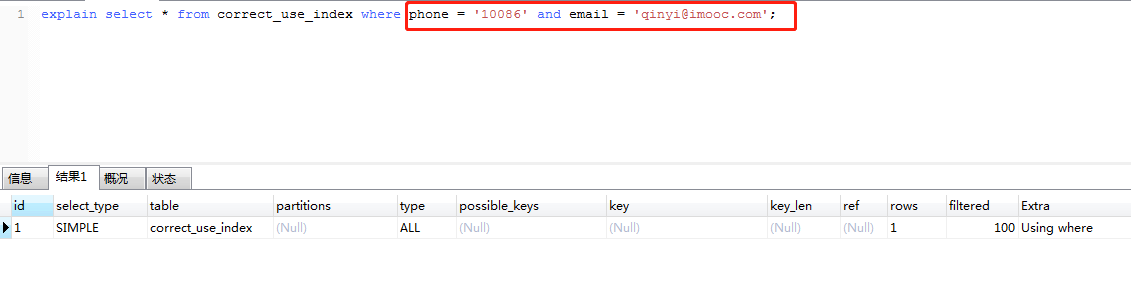
但如果执行如下sql,执行b和c,并不会走索引。
explain select * from correct_use_index where phone = '10086' and email = 'qinyi@imooc.com';
索引加的不正确/冗余
不再使用的索引没有及时删除:空间浪费,插入删除更新性能受影响、MySQL维护索引也需要消耗资源
索引的选择性太低,索引的意义不大。
列值过长,可以选择部分前缀作为索引(区分度高的情况下),而不是整列加上索引

测试样例表结构
CREATE TABLE `imooc_escape`.`correct_use_index_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`career` varchar(32) NOT NULL,
`first_name` varchar(16) NOT NULL,
`last_name` varchar(16) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
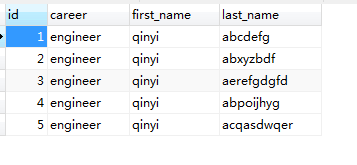
INSERT INTO `imooc_escape`.`correct_use_index_2`(`id`, `career`, `first_name`, `last_name`) VALUES (1, 'engineer', 'qinyi', 'abcdefg');
INSERT INTO `imooc_escape`.`correct_use_index_2`(`id`, `career`, `first_name`, `last_name`) VALUES (2, 'engineer', 'qinyi', 'abxyzbdf');
INSERT INTO `imooc_escape`.`correct_use_index_2`(`id`, `career`, `first_name`, `last_name`) VALUES (3, 'engineer', 'qinyi', 'aerefgdgfd');
INSERT INTO `imooc_escape`.`correct_use_index_2`(`id`, `career`, `first_name`, `last_name`) VALUES (4, 'engineer', 'qinyi', 'abpoijhyg');
INSERT INTO `imooc_escape`.`correct_use_index_2`(`id`, `career`, `first_name`, `last_name`) VALUES (5, 'engineer', 'qinyi', 'acqasdwqer');
样例数据如下
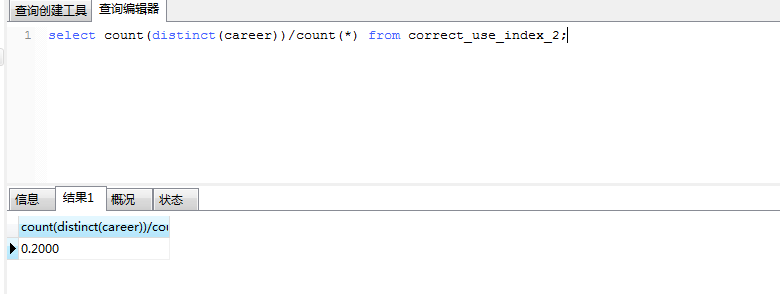
-- 索引选择性(没有必要为索引选择性较低的列创建索引)
select count(distinct(career))/count(*) from correct_use_index_2;
如上sql, 索引选择性为0.2,表示该值重复率非常高,意义不大。
-- 想要通过 name 去查询记录, 可以考虑创建 first_name 索引, 或 first_name、last_name 联合索引 --> 看一看索引选择性
select count(DISTINCT(career))/COUNT(*) from correct_use_index_2
由于执行了carreer的索引选择性是0.2000,索引选择性很低,意义不大。因此考虑使用联合索引(联合first_name,last_name)
# 输出 1.0000,但索引太长
select count(distinct(concat(first_name, last_name)))/count(*) from correct_use_index_2;
# 输出 0.2000
select count(distinct(concat(first_name, left(last_name, 1))))/count(*) from correct_use_index_2;
# 输出 0.6000
select count(distinct(concat(first_name, left(last_name, 2))))/count(*) from correct_use_index_2;
# 输出1.0000
select count(distinct(concat(first_name, left(last_name, 3))))/count(*) from correct_use_index_2;
因此可以尝试添加索引
ALTER TABLE correct_use_index_2 ADD INDEX `idx_first_last_name_3` (first_name, last_name(3));
查看当前索引信息
# 如下图,sub_part,只取了前三个字符
show index from correct_use_index_2;

索引加的不正确/冗余
- 表记录比较少,全表扫描效率更高
- 存在联合索引的情况下,在对前缀部分加索引(已经覆盖了单列或者多列),是没有意义的。
- 一张表中建立的索引过多(超过5个),应该是根据业务需求去分析创建,并不是越多越好,太多会浪费空间,影响额外的查询效率

MySQL为什么莫名奇妙的断开连接

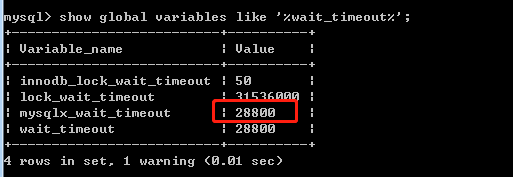
对于jdbc如果超过28800秒,断开连接。如上jdbc连接,如果加上autoReconnnetc=true, 可断开后主动连接。但可能会产生部分副作用。
autoReconnect存在的一些副作用

修改MySQL配置,避免断开连接
interactive_timeout: 交互式连接,如mysql客户端
wait_timeout: jdbc式连接

# 80个小时 但该方式治标不治本,只对本次绘会话有效。重启后失效
set global wait_timeout=288000;
show global variables like '%wait_timeout%'
修改my.cnf文件
[mysqld]
wait_timeout=288000
interactive_timeout=288000
数据库连接池HikariCP的配置

例如:一个4核,1块硬盘的服务器,连接数 = (4 * 2) + 1 = 9,凑个整数,10就可以了。
- core_count cpu 核心数
- effective_spindle_count 磁盘列阵中的硬盘数
配置可参考文章MySQL为什么莫名其妙的断开连接以及解决方案!
事务处理出错?可能是锁用得不对
数据库锁的分类
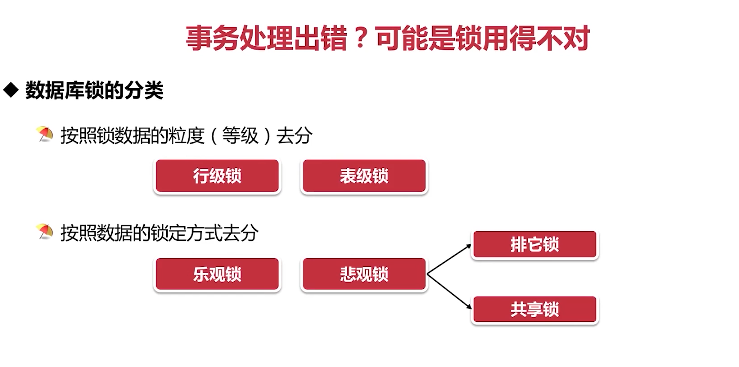
行级锁:锁定粒度最小,发生死锁的概率最小
表级锁:锁定粒度最大,发生死锁的概率最大
- 按照数据的锁定方式去分
乐观锁:带版本号,逻辑实现。
悲观锁:加锁,由数据库自身实现。
案例测试数据
CREATE TABLE `imooc_escape`.`lock_error_use_in_transaction` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
测试记录
INSERT INTO `imooc_escape`.`lock_error_use_in_transaction`(`id`, `name`, `age`) VALUES (1, 'imooc', 10);
INSERT INTO `imooc_escape`.`lock_error_use_in_transaction`(`id`, `name`, `age`) VALUES (2, 'qinyi', 19);
行锁的并发性能远高于白哦所,但是小心粒度升级
InnoDB只有在通过索引条件检索数据时使用行级锁,否则使用表锁
对于update/delete和insert语句,InnoDB会自动给涉及数据集加排它锁;对于普通的select语句,InnoDB不会加任何锁。

你写的SQL可能很慢,怎样做优化呢?
测试数据
-- auth_user
CREATE TABLE IF NOT EXISTS `auth_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键 id',
`create_user_id` varchar(64) NOT NULL DEFAULT '' COMMENT '创建当前 user 的 user',
`user_id` varchar(64) NOT NULL DEFAULT '' COMMENT '用户 id',
`login_username` varchar(64) NOT NULL DEFAULT '' COMMENT '登录用户名',
`username` varchar(64) NOT NULL DEFAULT '' COMMENT '用户姓名',
`email` varchar(128) NOT NULL DEFAULT '' COMMENT '邮箱',
`telephone` varchar(20) NOT NULL DEFAULT '' COMMENT '手机号码',
`password` varchar(128) NOT NULL DEFAULT '' COMMENT '密码',
`role_id` int(11) NOT NULL DEFAULT '0' COMMENT '角色 id',
`extra` varchar(512) NOT NULL DEFAULT '{}' COMMENT '额外信息',
`create_time` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
怎样配置MySQL定位执行“慢”的查询
- slow_query_log: 标记慢查询日志是否开启的参数,默认是OFF,即不开启。
- slow_query_log_file:标记存放慢查询日志文件的完整路径(注意权限问题)
- long_query_time:控制慢查询的时间阈值参数
- log_queries_not_using_indexs:标记是否记录未使用索引的查询,默认是关闭的。

show variables like '%slow_query_log%'
如果显示为OFF,在/etc/my.conf文件中配置
[mysqld]
long_query_time = 0.2
slow_query_log= 1
slow_query_log_file = /tmp/slow_query.log
log_queries_not_using_indexs = 1
随后重启mysql服务
systemctl restart mysqld

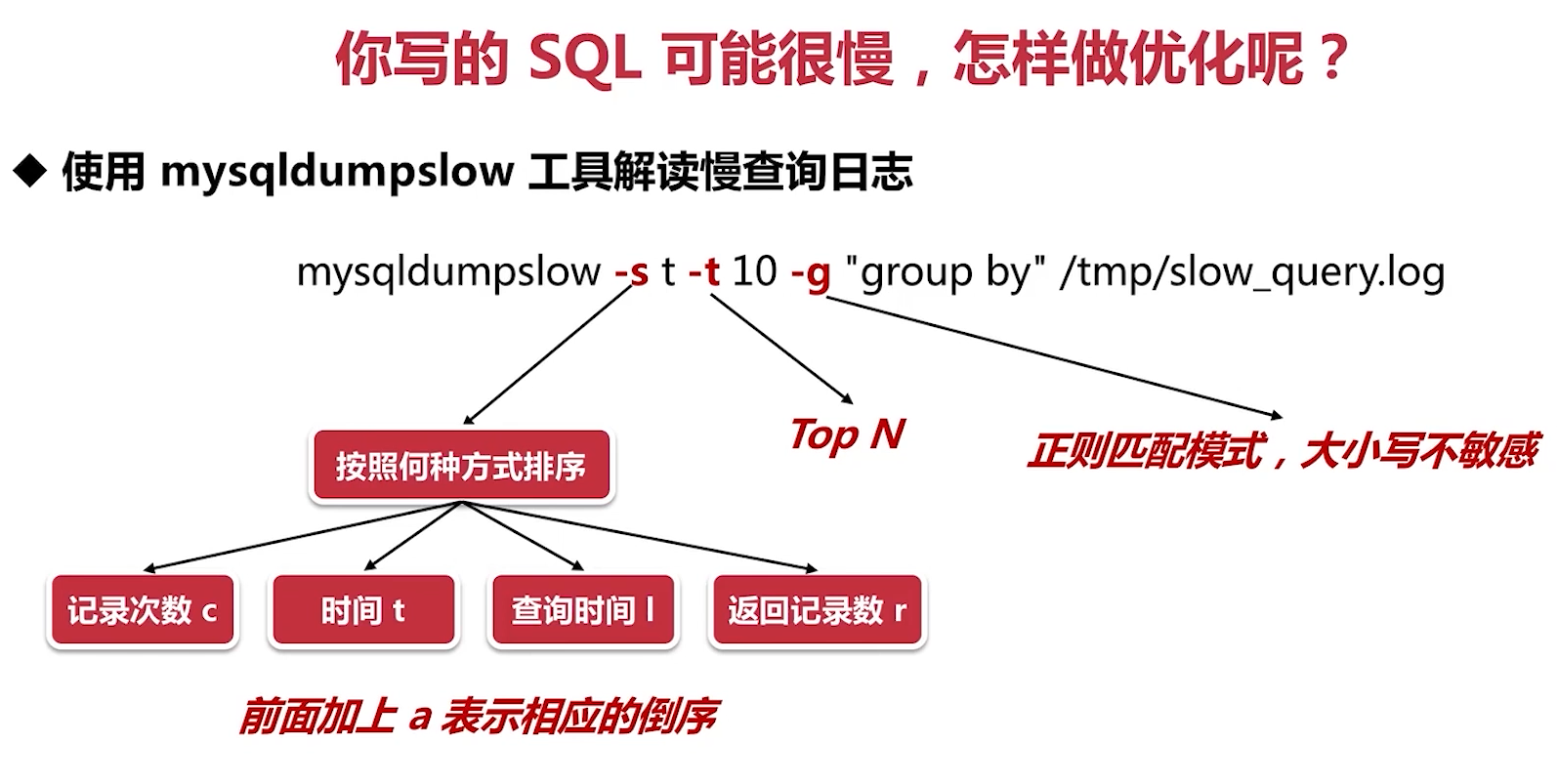
使用mysqldumpslow工具解读慢查询日志
使用explain/desc分析执行的SQL语句

慢查询问题总结建议
- SELECT太多数据行、数据列(大数据量查询)
- 没有定义合适的索引
- 没有按照索引定义的顺序查询
- 定义了索引,但是MySQL并没有选择
- 复杂查询

数据量逐渐增大,才考虑分库分表可行么?
业务发展过程中遇见了哪些问题?

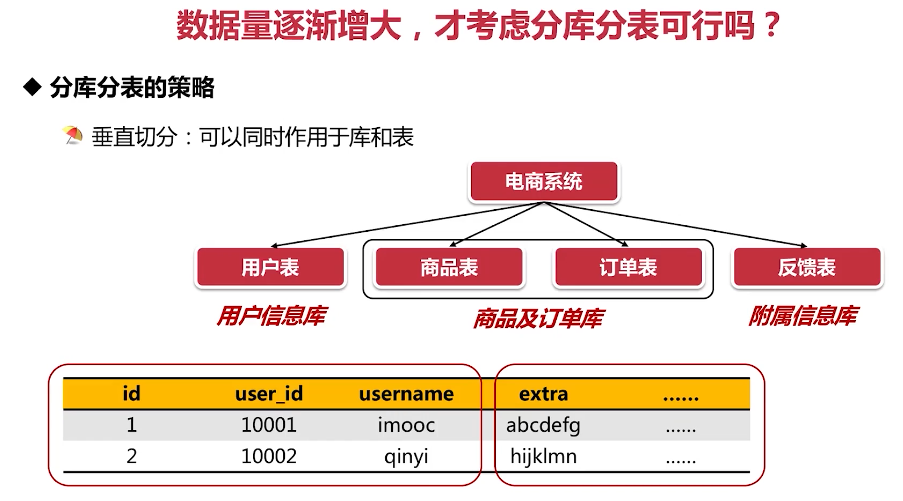
分库分表的策略
- 分库分表的策略
垂直切分:可以同时作用于库和表
水平切分:只适用于数据表
垂直切分的优点
- 消除苦中存在的业务表耦合,使数据表之间的关系更加清晰
- 将数据库的连接资源,单机硬件资源隔离,更利于业务的扩展
垂直切分的缺点
- 表语表之间很难做到完全的join,只能通过多次查询的方式聚合数据
- 查询多个表会将单表事务升级为分布式事务,实现难度大大增加
- 仍然可能会存在单表数据量过大的问题

分库分表引发的问题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号