
Hadoop3 Yarn ha搭建及测试排错
1. Yarn Ha原理
ResourceManager记录着当前集群的资源分配和Job运行状态,Yarn Ha利用Zookeeper等共享存储平台来存储这些信息以达到高可用。利用Zookeeper实现ResourceManager自动故障转移。
Yarn Ha架构图

MasterHADemon:控制RM的Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
2.配置
修改mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>slave1:10020</value>
</property>
</configurationc>
修改yarn-site.xml
<configuration>
<!-- 指定yarn的默认混洗方式,选择为mapreduce的默认混洗算法 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 指定ResourceManager的HA功能-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 为resourcemanage ha 集群起个id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<!-- 指定resourcemanger ha 有哪些节点名 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm12,rm13</value>
</property>
<!-- 指定第一个节点的所在机器 -->
<property>
<name>yarn.resourcemanager.hostname.rm12</name>
<value>slave1</value>
</property>
<!-- 指定第二个节点所在机器 -->
<property>
<name>yarn.resourcemanager.hostname.rm13</name>
<value>slave2</value>
</property>
<!-- 指定resourcemanger ha 所用的zookeeper 节点 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!-- 开启Recovery后,ResourceManger会将应用的状态等信息保存到yarn.resourcemanager.store.class配置的存储介质中,重启后会load这些信息,并且NodeManger会将还在运行的container信息同步到ResourceManager,整个过程不影响作业的正常运行。 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定yarn.resourcemanager.store.class的存储介质(HA集群只支持ZKRMStateStore) -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
分发到slave1、slave2上
[root@master hadoop]# scp -r mapred-site.xml yarn-site.xml slave1:`pwd`
mapred-site.xml 100% 1235 503.9KB/s 00:00
yarn-site.xml 100% 2962 828.6KB/s 00:00
[root@master hadoop]# scp -r mapred-site.xml yarn-site.xml slave2:`pwd`
mapred-site.xml 100% 1235 398.3KB/s 00:00
yarn-site.xml 100% 2962 1.1MB/s 00:00
在master上启动yarn服务
[root@master hadoop]# start-yarn.sh
Starting resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 03:10:51 CST 2023pts/1 上
Starting nodemanagers
上一次登录:五 2月 24 04:16:01 CST 2023pts/1 上
分别查看master、slave1、slave2上的进程
[root@master hadoop]# jps
129089 Jps
123520 DFSZKFailoverController
122130 JournalNode
123106 DataNode
7781 QuorumPeerMain
128905 NodeManager
125614 NameNode
[root@slave1 ~]# jps
2033 QuorumPeerMain
39972 DataNode
40455 ResourceManager #rm1
40519 NodeManager
39864 JournalNode
40824 Jps
[root@slave2 ~]# jps
53431 JournalNode
53928 DFSZKFailoverController
55564 ResourceManager #rm2
55628 NodeManager
53581 NameNode
53773 DataNode
55774 Jps
1935 QuorumPeerMain
启动slave1上的 job history服务
[root@slave1 ~]# mapred --daemon start historyserver
[root@slave1 ~]# jps
2033 QuorumPeerMain
39972 DataNode
41237 Jps
40455 ResourceManager
40519 NodeManager
39864 JournalNode
41215 JobHistoryServer
或者使用 mr-jobhistory-daemon.sh start
3. 测试Yarn
执行share包下的计算pi值任务
hadoop jar ../../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10
[2023-02-24 04:23:12.420]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://slave1:8088/cluster/app/application_1677183357397_0001 Then click on links to logs of each attempt.
. Failing the application.
2023-02-24 04:23:13,459 INFO mapreduce.Job: Counters: 0
Job job_1677183357397_0001 failed!
在mapred-site.xml中添加如上缺少配置
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
分发到slave1、slave2机器,并重启yarn
# 分发
[root@master hadoop]# scp -r mapred-site.xml slave1:`pwd`
mapred-site.xml 100% 1609 701.6KB/s 00:00
[root@master hadoop]# scp -r mapred-site.xml slave2:`pwd`
mapred-site.xml 100% 1609 455.1KB/s 00:00
# 重启
[root@master hadoop]# stop-yarn.sh
Stopping nodemanagers
上一次登录:五 2月 24 04:16:04 CST 2023pts/1 上
Stopping resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:28:08 CST 2023pts/1 上
[root@master hadoop]# start-yarn.sh
Starting resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:28:17 CST 2023pts/1 上
Starting nodemanagers
上一次登录:五 2月 24 04:28:59 CST 2023pts/1 上
重新执行计算pi任务,报错
[2023-02-24 04:35:00.699]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
log4j:WARN No appenders could be found for logger (org.apache.hadoop.mapreduce.v2.app.MRAppMaster).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
For more detailed output, check the application tracking page: http://slave2:8088/cluster/app/application_1677184408784_0001 Then click on links to logs of each attempt.
. Failing the application.
2023-02-24 04:30:50,423 INFO mapreduce.Job: Counters: 0
Job job_1677184408784_0001 failed!
使用yarn命令查看报错日志
yarn logs -applicationId application_1677184408784_0001
2023-02-24 04:35:00,225 ERROR [Listener at 0.0.0.0/38665] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.NullPointerException
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.register(RMCommunicator.java:178)
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.serviceStart(RMCommunicator.java:122)
at org.apache.hadoop.mapreduce.v2.app.rm.RMContainerAllocator.serviceStart(RMContainerAllocator.java:280)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$ContainerAllocatorRouter.serviceStart(MRAppMaster.java:979)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.serviceStart(MRAppMaster.java:1293)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$6.run(MRAppMaster.java:1761)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.initAndStartAppMaster(MRAppMaster.java:1757)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.main(MRAppMaster.java:1691)
Caused by: java.lang.NullPointerException
at org.apache.hadoop.mapreduce.v2.app.client.MRClientService.getHttpPort(MRClientService.java:177)
at org.apache.hadoop.mapreduce.v2.app.rm.RMCommunicator.register(RMCommunicator.java:159)
... 14 more
2023-02-24 04:35:00,222 INFO [TaskHeartbeatHandler PingChecker] org.apache.hadoop.mapreduce.v2.app.TaskHeartbeatHandler: TaskHeartbeatHandler thread interrupted
2023-02-24 04:35:00,230 INFO [Listener at 0.0.0.0/38665] org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.NullPointerException
可以查看到初始化MRAppMaster失败,是由于配置了高可用HA, 配置高可用的话 问题大概就是MRClientService的WebApp创建过程出错,导致WebApp对象为null,后边调用了WebApp的getHttpPort()方法,导致空指针。
方案1:在yarn-site.xml中添加rm12和rm13信息
<!--注意命名rm12、rm13应与配置中的rm名称一致-->
<property>
<name>yarn.resourcemanager.webapp.address.rm12</name>
<value>slave1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm13</name>
<value>slave2:8088</value>
</property>
方案2:如博客Hive进行数据统计时报错:org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster所言,修改hadoop-yarn-server-web-proxy-3.1.3.jar。
此处 使用方案1进行修改配置,并分发重启
[root@master hadoop]# scp -r yarn-site.xml slave1:`pwd`
yarn-site.xml 100% 3220 1.0MB/s 00:00
[root@master hadoop]# scp -r yarn-site.xml slave2:`pwd`
yarn-site.xml 100% 3220 793.6KB/s 00:00
[root@master hadoop]# stop-yarn.sh
Stopping nodemanagers
上一次登录:五 2月 24 04:29:02 CST 2023pts/1 上
Stopping resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:43:17 CST 2023pts/1 上
[root@master hadoop]# start-yarn.sh
Starting resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:43:26 CST 2023pts/1 上
Starting nodemanagers
上一次登录:五 2月 24 04:43:42 CST 2023pts/1 上
hadoop jar ../../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10
[pid=57780,containerID=container_e35_1677185292808_0001_01_000021] is running 494455296B beyond the 'VIRTUAL' memory limit. Current usage: 83.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_e35_1677185292808_0001_01_000021 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
错误产生原因是因为从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
在mapred-site.xml中添加配置
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
[root@master hadoop]# scp -r mapred-site.xml slave1:`pwd`
mapred-site.xml 100% 2033 849.4KB/s 00:00
[root@master hadoop]# scp -r mapred-site.xml slave2:`pwd`
mapred-site.xml 100% 2033 915.8KB/s 00:00
重新启动yarn并执行计算pi任务
[root@master hadoop]# stop-yarn.sh
Stopping nodemanagers
上一次登录:五 2月 24 04:43:45 CST 2023pts/1 上
Stopping resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:51:14 CST 2023pts/1 上
[root@master hadoop]# start-yarn.sh
Starting resourcemanagers on [ slave1 slave2]
上一次登录:五 2月 24 04:51:22 CST 2023pts/1 上
Starting nodemanagers
上一次登录:五 2月 24 04:51:39 CST 2023pts/1 上
[root@master hadoop]# hadoop jar ../../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10
成功执行pi任务
Job Finished in 67.406 seconds
2023-02-24 04:53:27,744 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Estimated value of Pi is 3.20000000000000000000
查看Yarn高可用状态
[root@slave1 ~]# yarn rmadmin -getAllServiceState
slave1:8033 standby
slave2:8033 active
或通过RestAPI http://
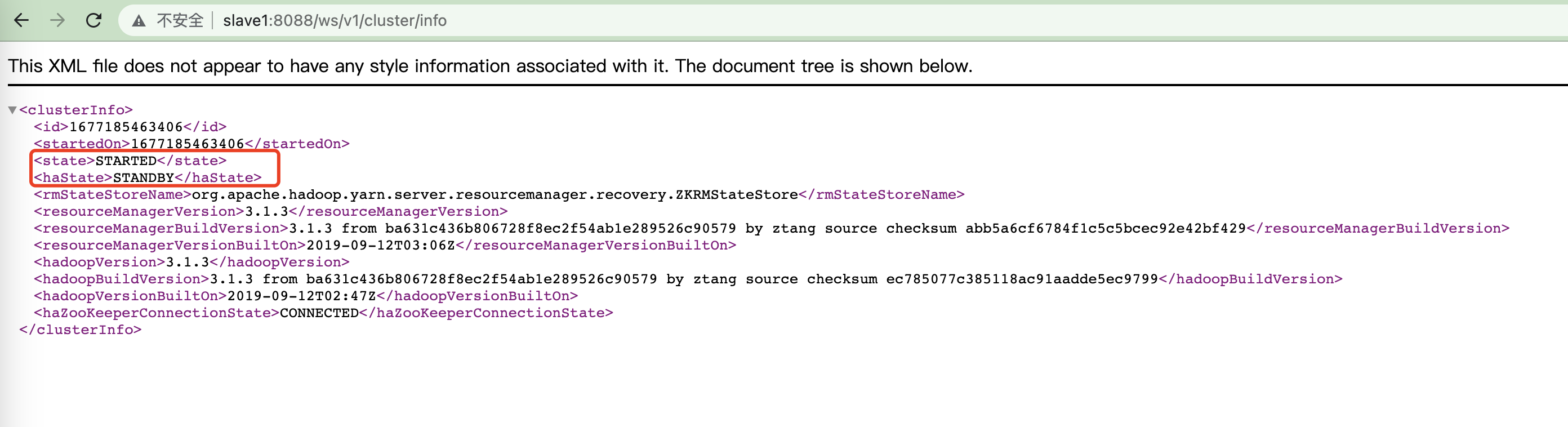
查看某个rm机器的状态
[root@slave1 ~]# yarn rmadmin -getServiceState rm12
standby
4. 测试Yarn HA
在master节点上执行计算pi任务,在rm12(slave1)集群上kill ResourceManager,查看计算π任务会不会迁移到rm13(slave2)上。
# master机器
[root@master hadoop]# hadoop jar ../../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10
# slave1机器
[root@slave1 ~]# jps
2033 QuorumPeerMain
44114 Jps
39972 DataNode
43301 NodeManager
39864 JournalNode
43231 ResourceManager
[root@slave1 ~]# kill 43231
[root@slave1 ~]# jps
2033 QuorumPeerMain
44178 Jps
39972 DataNode
43301 NodeManager
39864 JournalNode
执行日志中可以看到如下图故障切换
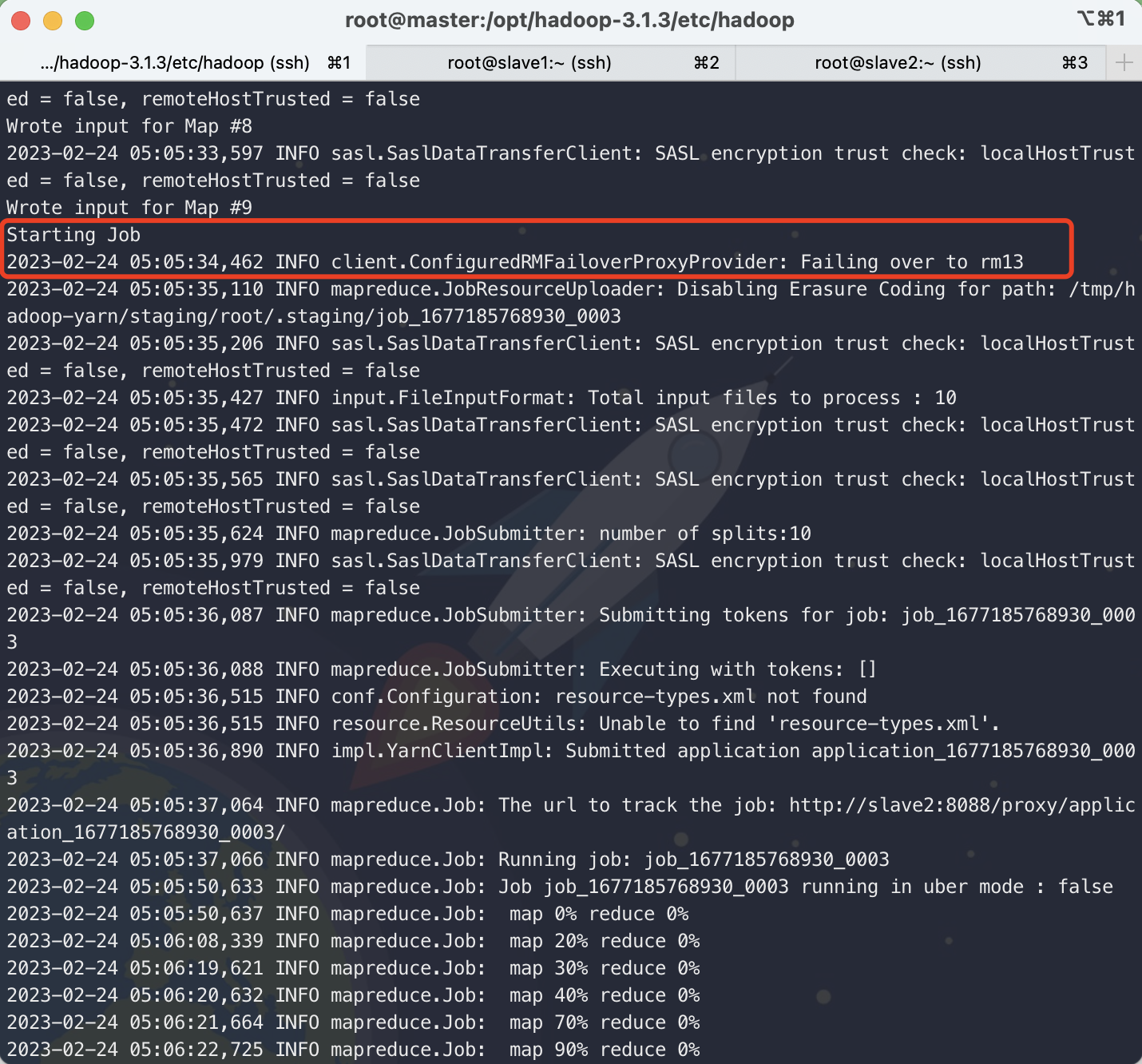
随后启动rm12上的 ResourceManager
[root@slave1 ~]# yarn-daemon.sh start resourcemanager
WARNING: Use of this script to start YARN daemons is deprecated.
WARNING: Attempting to execute replacement "yarn --daemon start" instead.
[root@slave1 ~]# yarn rmadmin -getServiceState rm12
standby

 浙公网安备 33010602011771号
浙公网安备 33010602011771号