
Hadoop3 HDFS HA 高可用搭建及测试
1. 什么是HA
HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上,以保证服务的高可用。
Hadoop的HA模式是最常见的生产环境上的安装部署方式。
Hadoop Ha包含HDFS HA和Yarn Ha。
DataNode和NodeManager本身就是被设计为高可用的,不用对它们进行特殊的高可用处理。
1.1HDFS Ha原理
单NameNode的缺陷存在单点故障的问题,如果NameNode不可用,会导致整个HDFS文件系统不可用 。所以设计高可用的HDFS(Hadoop Ha)来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode,但一旦引入多个 NameNode,就需要解决如下的问题?
- 保证NameNode内存中元数据数据一致,并且保证编辑日志文件的安全性
- 多个NameNode如何协作
- 客户端如何正确地访问到可用的 NameNode
- 保证任意时刻只能有一个NameNode处于对外提供服务状态
解决方法
对于保证NameNode元数据的一致性和编辑日志的安全性,采用zk来存储编辑日志文件。
两个 NameNode一个是Active状态,一个是Standby状态,一个时间点只能有一个Active状态。
NameNode提供服务,两个NameNode存储的元数据是实时同步的,当Active的NameNode出现问题时,通过zk实时切换到Standby的NameNode上,并将Standby改为Active状态。
客户端通过连接zk的代理来确定当时是哪个NameNode处于服务状态。
HDFS HA架构图
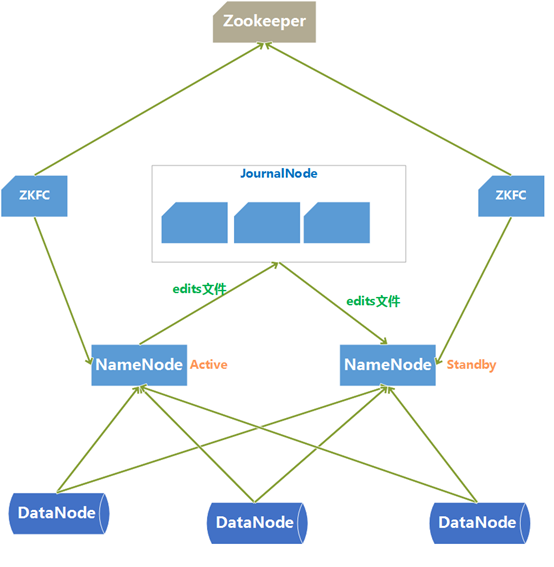
HDFS HA架构中有两台NameNode节点,一台处于活动状态(Active)为客户提供服务,另一台处于热备份状态(Standby)。元数据文件有两个:fsImage和edits,备份元数据就是备份这两个文件。
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的 元数据信息和Active NameNode上的 元数据信息一致,以实现热备份。
当Active NameNode失效时,Zookeeper会自动将Standby NameNode修改为Active状态。
ZKFC(失效检测控制)是Hadoop里的一个zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个 ZNode节点,节点里保存了NameNode的状态信息。当NameNode失效后,ZKFC监测到报告给Zookeeper,Zookeeper会把对应 的Znode删除掉,Standby ZKFC发现没有Active状态 的NameNode时,就会用shell命令将自己监控的 NameNode改为Active状态,并修改Znode数据。
Znode是一个临时节点,临时节点特征是客户端的 连接断开后就会把znode删掉,所以当ZKFC失效时,也会导致切换NameNode。
DataNode会将心跳信息和Block块,汇报信息同时发送给NameNode,但DataNode只会接受Active NameNode发来的 文件读写命令。
2.节点规划
| NameNode | ZkFc | DataNode | JournalNode | ResourceManager | zk集群 | |
|---|---|---|---|---|---|---|
| master | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |
| slave1 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |
| slave2 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
3.节点免密配置
各个节点均都配置
防火墙关闭
systemctl stop firewalld
systemctl disable firewalld
hosts文件配置
vi /etc/hosts
192.168.64.102 master
192.168.64.103 slave1
192.168.64.104 slave2
节点免密配置
ssh-keygen -t rsa
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
JDK和Hadoop安装包解压并配置到环境变量
vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_211
export HADOOP_HOME=/opt/hadoop-3.1.3
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.13
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
4.zookeeper安装
4.1 解压并安装
tar -zxvf zookeeper-3.4.13.tar.gz -C /opt
cd /opt/zookeeper-3.4.13
# 创建数据目录
mkdir -p data
cp zoo_sample.cfg zoo.cfg
4.2修改zk配置
在数据目录/opt/zookeeper-3.4.13/data目录下创建识别文件 myid,在myid文件中设置标识(数字),语文配置文件中 的server.1有对应。各个节点配置为对应的数字。
echo 1 > myid
zoo.cfg文件
vi zoo.cfg
# 修改数据目录
dataDir=/opt/zookeeper-3.4.13/data
# 文件末尾zk集群添加信息
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
在其他节点(slave1、slave2)上执行 相同的配置,其中差异点为myid中的数值与zoo.cfg中匹配。
scp -r /opt/opt/zookeeper-3.4.13/conf/zoo.cfg slave1:`PWD`
scp -r /opt/opt/zookeeper-3.4.13/conf/zoo.cfg slave2:`PWD`
# slave1上执行
echo 2 > myid
# slave1上执行
echo 3 > myid
4.3启动 zk集群
# 各个节点均需执行启动命令
zkServer.sh start
# 查看各个节点的状态
zkServer.sh status
使用jps查看进程信息
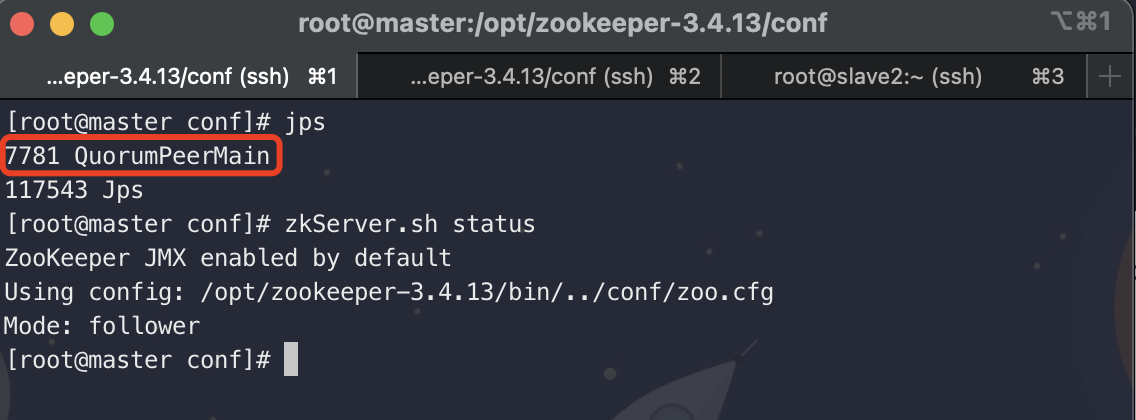
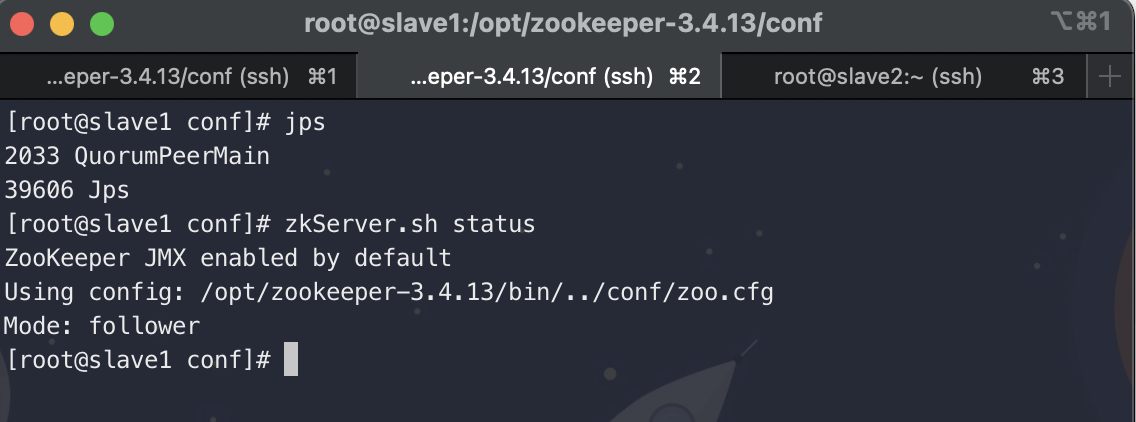
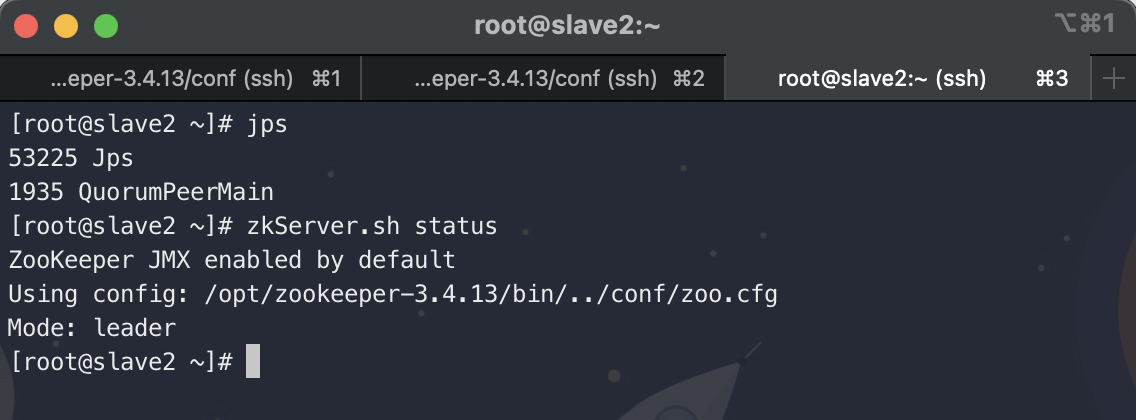
5. HDFS Ha搭建
5.1 配置
在master上进行配置,随后分发到slave1、slave2机器上。
hadop-env.sh中配置JDK
export JAVA_HOME=/opt/jdk1.8.0_211
修改works指定datanode的节点
master
slave1
slave2
修改core-site.xml
<configuration>
<!-- 指定NameNode的地址,名称中不要使用中划线 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.3/data</value>
</property>
<!--指定每个zookeeper服务器的位置和客户端端口号-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!-- 解决HDFS web页面上删除、创建文件权限不足的问题 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
集群名称可使用中划线,不可使用下划线
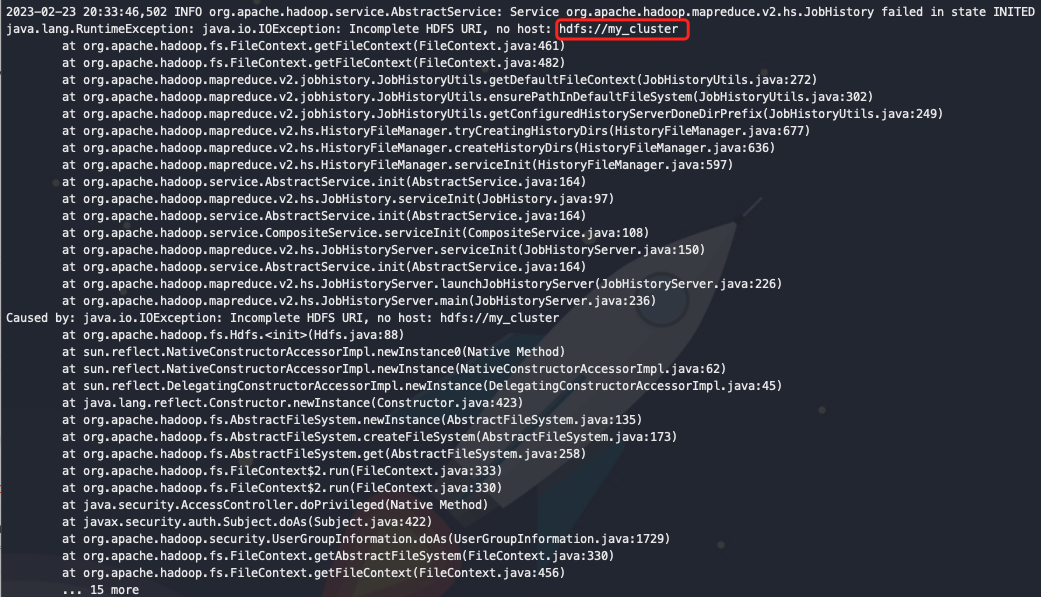
修改hdfs-site.xml
<configuration>
<!--集群名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--集群中NameNode节点-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--NameNode RPC通讯地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave2:9820</value>
</property>
<!--NameNode http通讯地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave2:9870</value>
</property>
<!--NameNode元数据在JournalNode上存放的位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/my_cluster</value>
</property>
<!--JournalNode数据存放目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.1.3/data/journal/data</value>
</property>
<!--启用nn故障自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--访问代理类:client用于确定哪个NameNode为Active-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制,即同一时刻只能有一台服务器对外响应-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时需要ssh秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--隔离的超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
先同步配置文件到slave1、slave2(可删除 share/doc减轻传输文件数量 )
rm -rf /opt/hadoop-3.1.3/share/doc/
scp hadoop-env.sh core-site.xml hdfs-site.xml slave1:`pwd`
scp hadoop-env.sh core-site.xml hdfs-site.xml slave2:`pwd`
5.2 启动
启动zk集群,master、slave1、slave2上分别执行
zkServer.sh start
在master、slave1、slave2上启动journal node
hdfs --daemon start journalnode
[root@master hadoop]# hdfs --daemon start journalnode
WARNING: /opt/hadoop-3.1.3/logs does not exist. Creating.
[root@master hadoop]# jps
122130 JournalNode
122178 Jps
7781 QuorumPeerMain
选择master,格式化HDFS
hdfs namenode -format
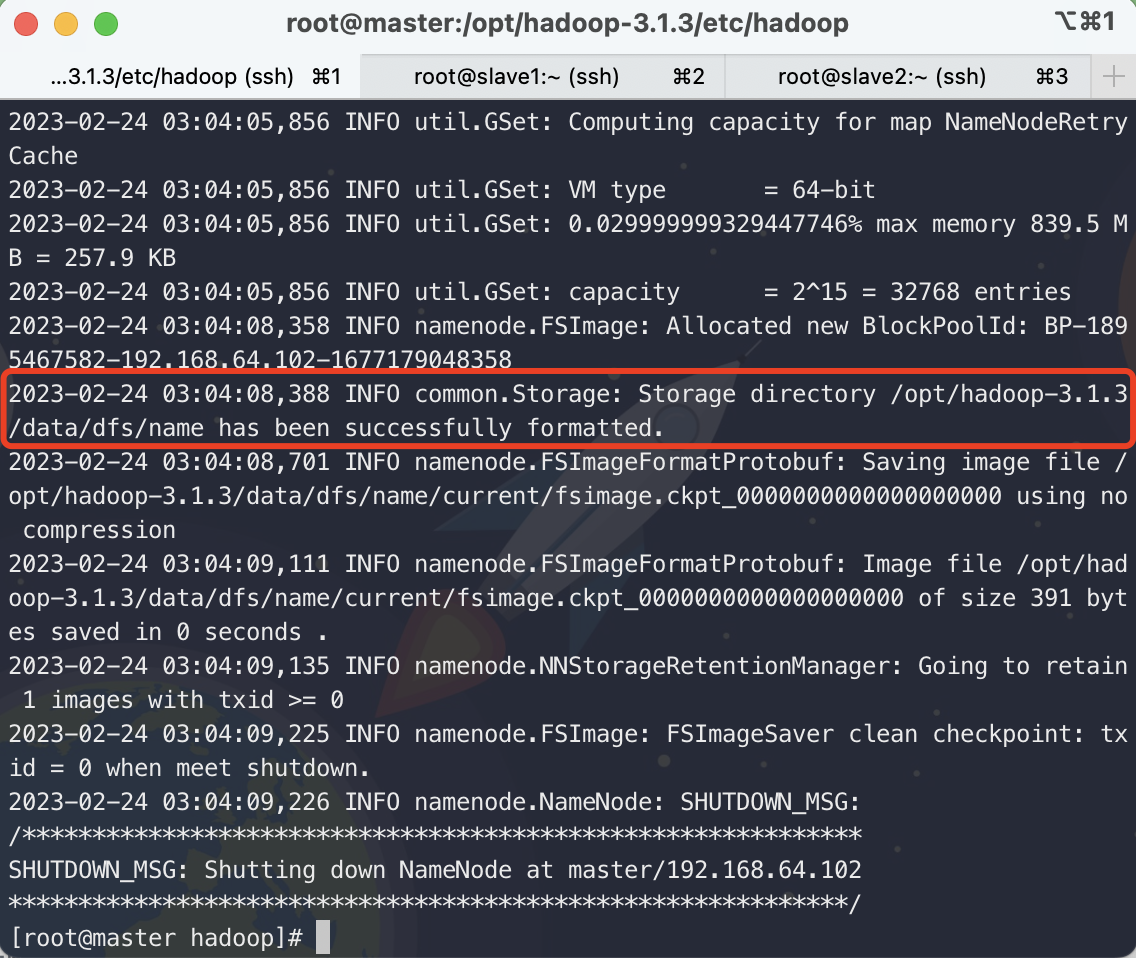
格式化后,在master上启动namenode进程
[root@master hadoop]# hdfs --daemon start namenode
[root@master hadoop]# jps
122130 JournalNode
7781 QuorumPeerMain
122406 NameNode
122446 Jps
在另一台namenode机器(slave2)上同步元数据信息,然后在该节点启动NameNode
# 同步元数据信息
[root@slave2 ~]# hdfs namenode -bootstrapStandby
# 执行信息
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://master:9870
Other NN's IPC address: master/192.168.64.102:9820
Namespace ID: 668316271
Block pool ID: BP-1895467582-192.168.64.102-1677179048358
Cluster ID: CID-a14a7c8c-5b81-4f8b-9cf6-ff25735f6543
Layout version: -64
isUpgradeFinalized: true
=====================================================
2023-02-24 03:10:58,141 INFO common.Storage: Storage directory /opt/hadoop-3.1.3/data/dfs/name has been successfully formatted.
# 启动namenode
[root@slave2 ~]# hdfs --daemon start namenode
[root@slave2 ~]# jps
53650 Jps
53431 JournalNode
53581 NameNode #可看到NameNode已启动
1935 QuorumPeerMain
在master上执行格式化
hdfs zkfc -formatZK
# 执行信息
2023-02-24 03:09:29,842 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
执行到此处,还没有启动3个DataNode和2个ZKFC进程
启动hadoop集群,在master上执行
start-dfs.sh
以Root用户启动会出现如下错误
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Starting ZK Failover Controllers on NN hosts [node1 node2]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
解决方法:将未定义的用户配置到全局变量,或者start-dfs.sh和stop-dfs.sh中
# 添加如下信息到配置首行(start-dfs和stop-dfs):
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
# 添加到/etc/profile中添加到行尾
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_ZKFC_USER=root
随后再次启动start-dfs.sh
[root@master hadoop]# jps
123585 Jps
123520 DFSZKFailoverController
122130 JournalNode
123106 DataNode
7781 QuorumPeerMain
122406 NameNode
在启动zkCli.sh,观察节点信息
zkCli.sh -server 192.168.64.102
[zk: 192.168.64.102(CONNECTED) 0] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: 192.168.64.102(CONNECTED) 1] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn1master �L(�>
cZxid = 0x900000009
ctime = Fri Feb 24 03:15:06 CST 2023
mZxid = 0x900000009
mtime = Fri Feb 24 03:15:06 CST 2023
pZxid = 0x900000009
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x1000226b7dc0000
dataLength = 30
numChildren = 0
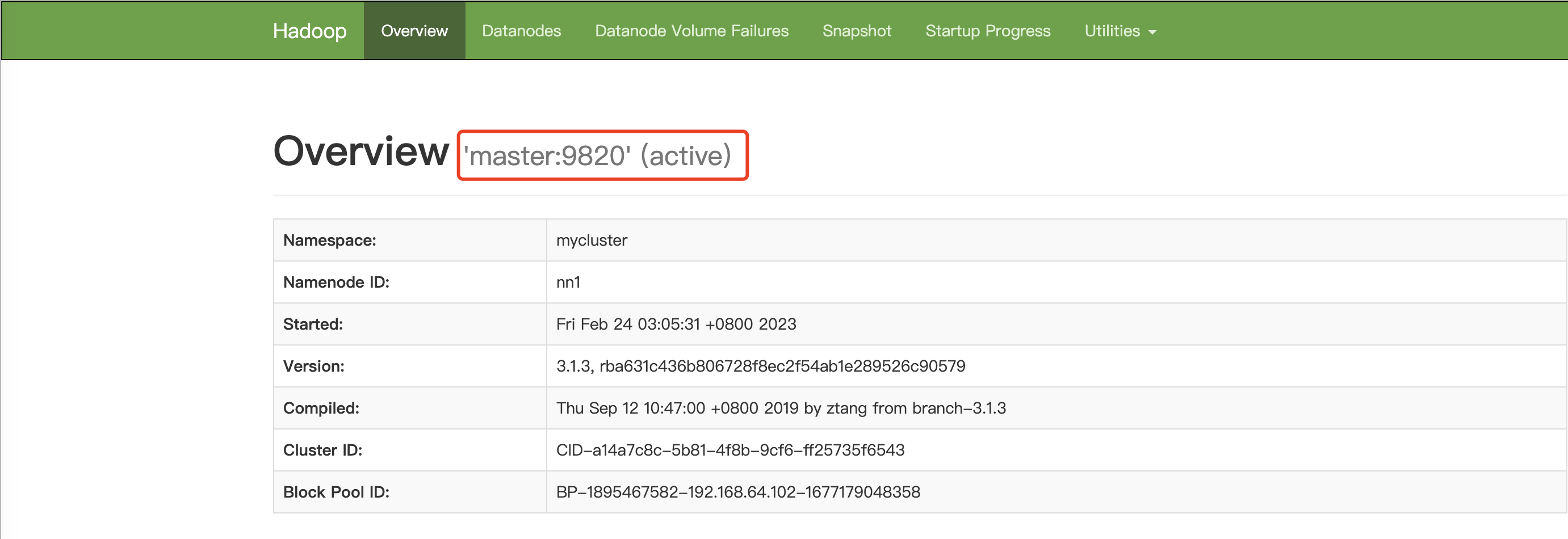
可以从zk中看到master节点占用锁,它状态应为active,浏览器访问http://master:9870
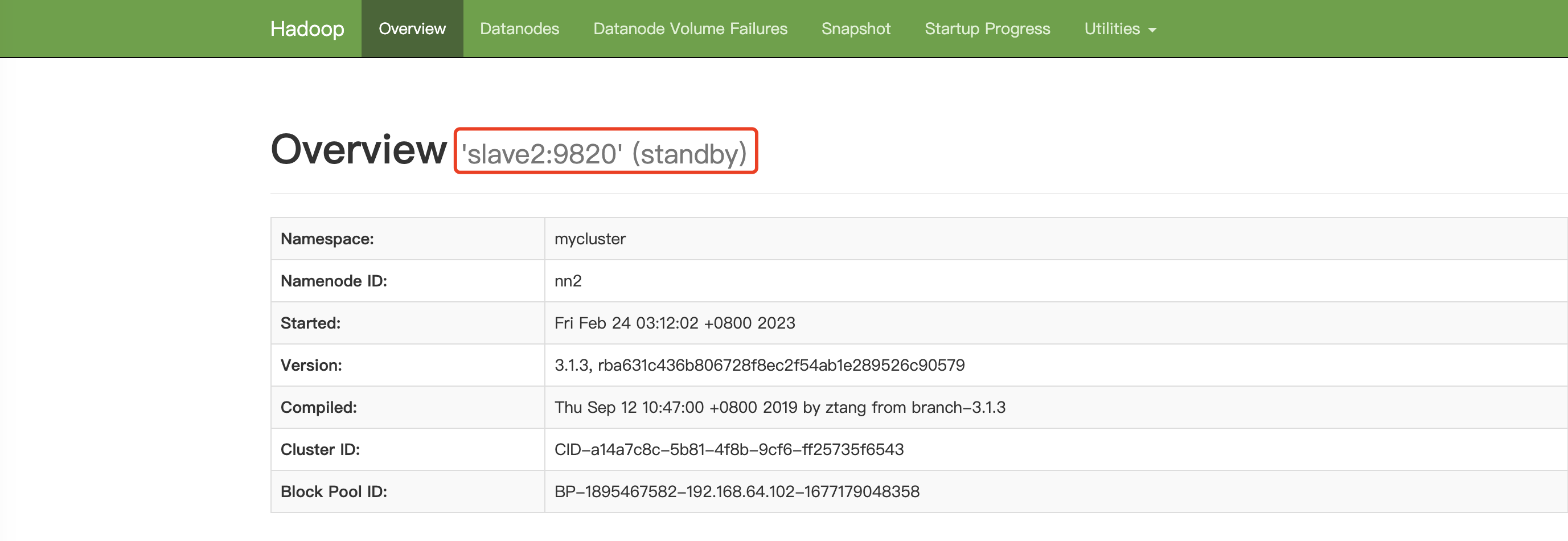
而slave2应为Standby状态,浏览器访问 http://slave2:9870
5.4 测试
将处于active状态对应节点上的NameNode进程关闭
[root@master hadoop]# jps
123520 DFSZKFailoverController
122130 JournalNode
123106 DataNode
7781 QuorumPeerMain
122406 NameNode
124156 Jps
[root@master hadoop]# kill 122406
[root@master hadoop]# jps
123520 DFSZKFailoverController
122130 JournalNode
123106 DataNode
7781 QuorumPeerMain
124200 Jps
进入zk中查看节点信息
zk: 192.168.64.102(CONNECTED) 0] ls /hadoop-ha/mycluster/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: 192.168.64.102(CONNECTED) 0] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2slave2 �L(�>
cZxid = 0x900000064
ctime = Fri Feb 24 03:26:23 CST 2023
mZxid = 0x900000064
mtime = Fri Feb 24 03:26:23 CST 2023
pZxid = 0x900000064
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x1000226b7dc000a
dataLength = 30
numChildren = 0
可以观察到已经切换到slave2上,但通过浏览器观察依旧slave2显示standby。
这是因为缺少一个rpm包:psmisc,给3台机器分别安装
yum -y install psmisc
master访问不通,slave2访问切换为Active状态
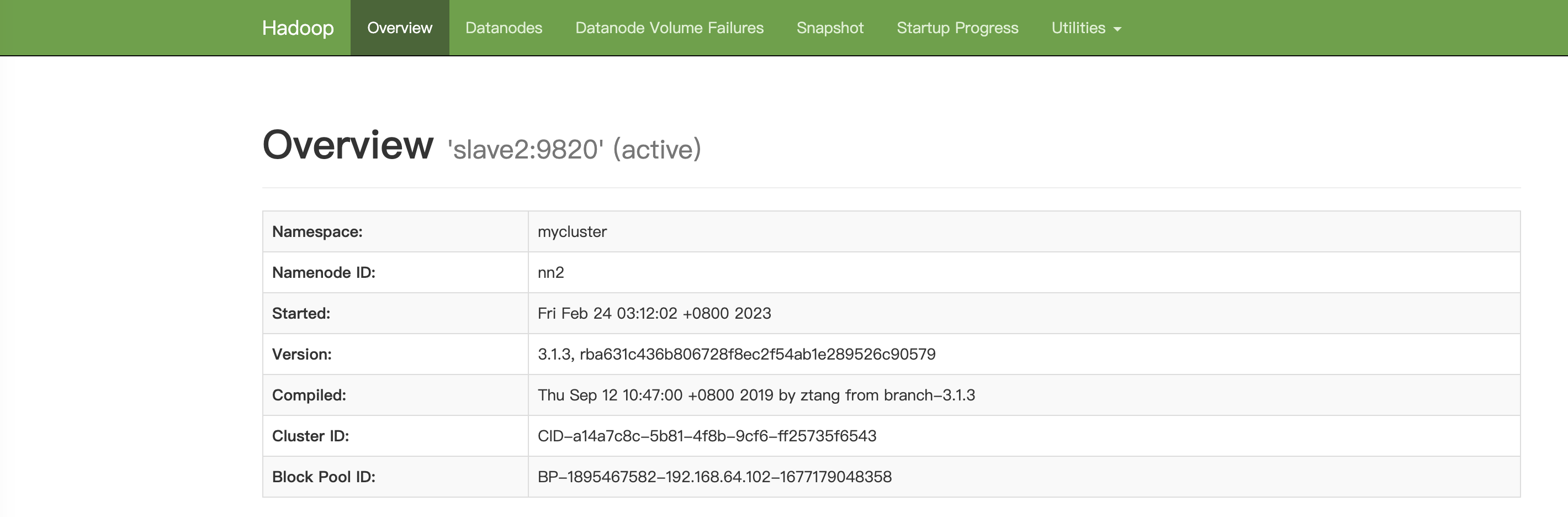
恢复master1上NameNode进程
[root@master hadoop]# hdfs --daemon start namenode
[root@master hadoop]# jps
123520 DFSZKFailoverController
122130 JournalNode
123106 DataNode
125650 Jps
7781 QuorumPeerMain
125614 NameNode
5.5 hadmin
查看服务状态
[root@master hadoop]# hdfs haadmin -getAllServiceState
master:9820 standby
slave2:9820 active
查看nn1,nn2各自状态
# 此处的nn1和nn2取自hdfs-site.xml中配置的nn1和nn2
[root@master hadoop]# hdfs haadmin -getServiceState nn1
standby
[root@master hadoop]# hdfs haadmin -getServiceState nn2
active
切换主备状态,例如此时nn2为Active NameNode,想让nn1为Active NameNode,可执行如下命令。如果nn2已经是Active状态,执行完此命令,nn2仍为新的Active NameNode
[root@master hadoop]# hdfs haadmin -failover nn2 nn1
Failover to NameNode at master/192.168.64.102:9820 successful
[root@master hadoop]# hdfs haadmin -getAllServiceState
master:9820 active
slave2:9820 standby
下一篇将重点介绍Yarn Ha搭建。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号