
HiveServer2高可用 MetaStore高可用搭建详解
为提升hive可用性,提升集群稳定性。对已搭建好的hive进行高可用改造。没有搭建好hive的,请先移步搭建好hive,并且beeline测试连通,在参考本文。
hive Server2高可用
Hive 从 0.14版本开始,使用zookeeper实现了Hive Server2的HA功能,Client端可以通过指定一个nameSpace来连接HiveServer2,而不是传统的指定某一个host和port。beeline -u jdbc:hive2://master:10000 -n root
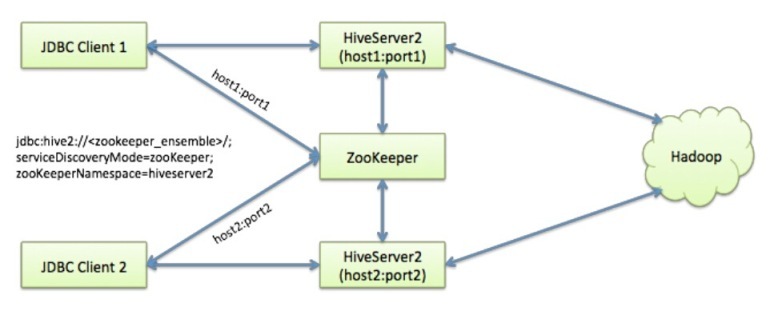
实验环境
| 组件名 | 版本号 |
|---|---|
| Hadoop | 3.1.3 |
| Zookeeper | 3.4.13 |
| Hive | 3.1.2 |
| 主机名 | 组件 |
|---|---|
| master | NameNode/NodeManager/DataNode/SecondaryNameNode/zk/hiverserver2 |
| slave1 | NodeManager/DataNode/zk/hiveserver2/metastore |
| slave2 | NodeManager/DataNode/ResourceManager/zk |
实验前已默认配置好Hadoop 全分布或者HA搭建完成,ZK集群部署完成。
zookeeper集群启动,需要在各个节点上执行 ./zkServer.sh start
master和slave无关hive sever2 配置项
<!-- hive-site.xml -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.64.102:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
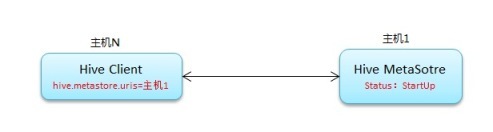
MetaStore 高可用
常规连接
高可用连接
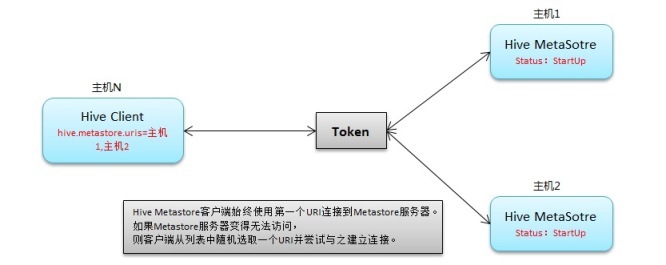
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083,thrift://slave1:9083</value>
</property>
hive server2相关的配置
master上
<!-- 这是hiveserver2 -->
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value> master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.64.102</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
slave1上
<!-- 这是hiveserver2 -->
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value> master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<!-- 与 master上 不同-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.64.103</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
完成如上配置后,在数据库中创建hive库。在master或slave机器上执行创建元数据信息语句schematool -dbType mysql -initSchema,执行完成后,在master上启动hive metastore及hiveserver2进程
nohup hive --service metastore &
nohup hive --service hiveserver2 &
使用zk客户端连接,观察节点信息。
zkCli.sh -server 192.168.64.102:2181
ls /
[zookeeper, hiveserver2_zk]
ls /hiveserver2_zk
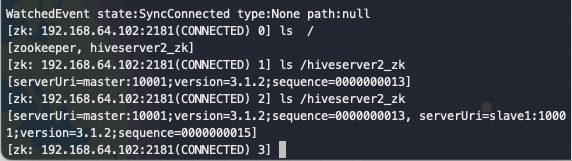
[serverUri=master:10001;version=3.1.2;sequence=0000000013]
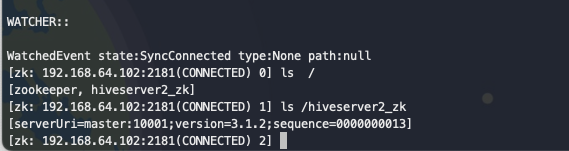
可以观察到,master上的信息已注册到zk中,随后启动slave1机器上的hiveserver2 服务
nohup hive --service hiveserver2 &
观察zk上节点的信息如下图
Beeline连接集群
> beeline
> !connect jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk root
> show databases;
此处暂未设置密码,回车即可
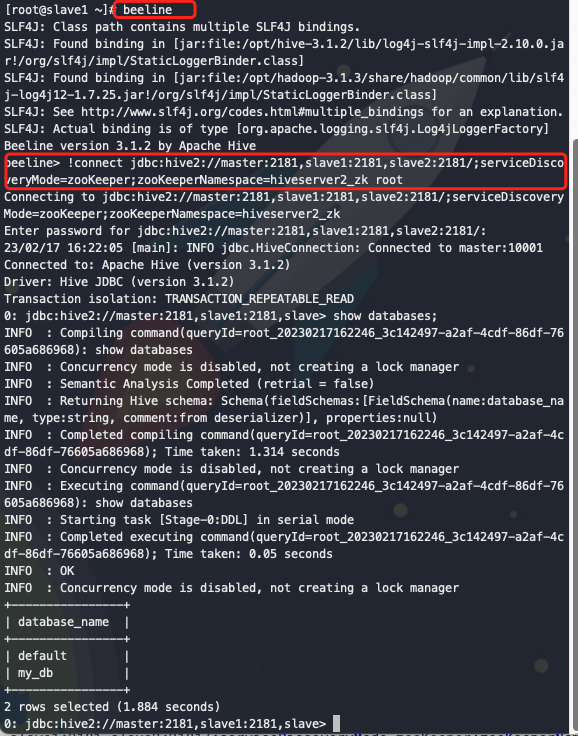
验证hive server2高可用
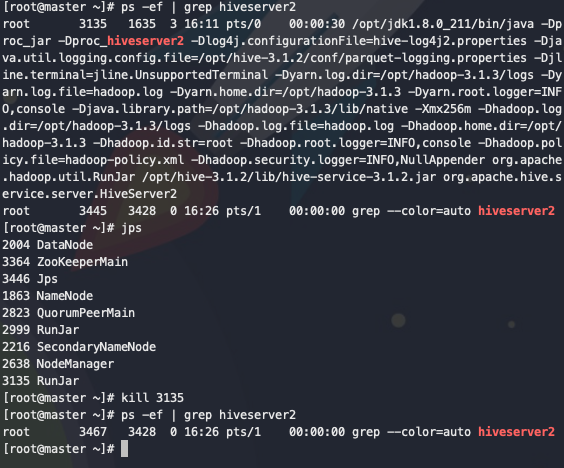
查看master主机上的hiveserver2 进程,并kill 该进程
ps -ef | grep hiveserver2
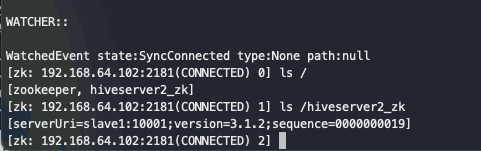
查询zk上注册的hiveserver2 节点信息,发现master上的hiveserver2 信息已下线。
ls /hiveserver2_zk
退出beeline后,重新进入连接,查看数据库,可查询到数据。
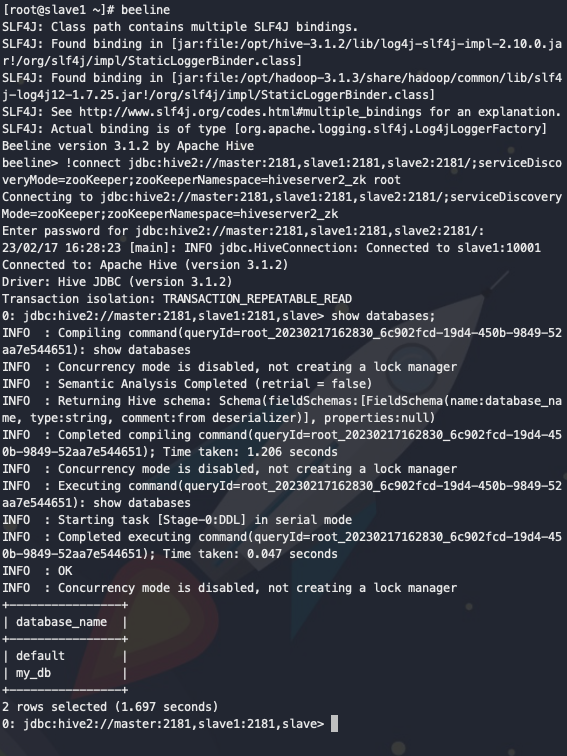
验证metastore高可用
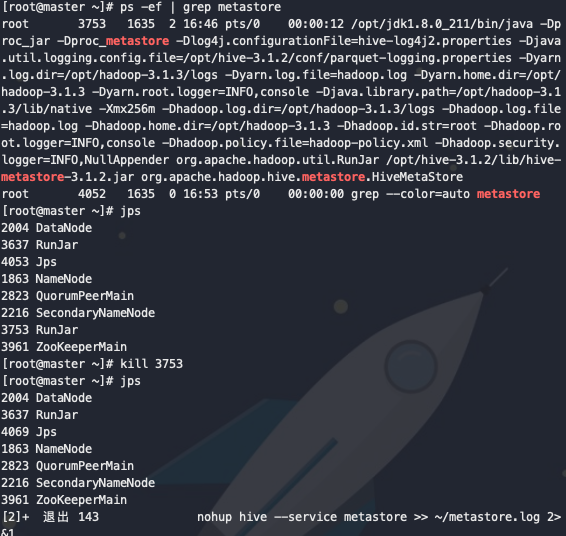
在master机器上查看metastore进程,并kill该进程
ps -ef | grep metastore
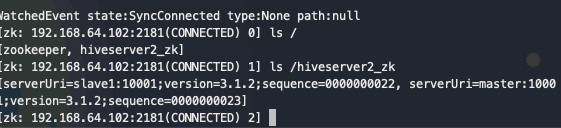
在zk上观察hiverserver2信息
ls /hiveserver2_zk
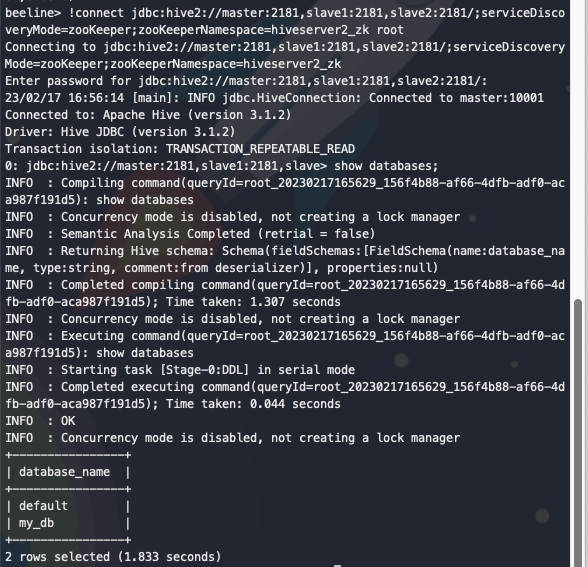
使用beeline 可正常连接
beeline> !connect jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk root
Java API
添加依赖的pom
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-metastore -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-metastore -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
代码示例
public class HiveHaTest {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Connection conn = DriverManager.getConnection("jdbc:hive2://master:2181,slave1:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk", "root", "");
Statement stmt = conn.createStatement();
// //创建数据库
// String sql = "create database db1";
// stmt.execute(sql);
// 查询所有数据库
String sql = "show databases";
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
// //查询数据
// sql = "select * from db_hive.stu";
// res = stmt.executeQuery(sql);
// while (res.next()) {
// System.out.println(res.getString(1)+"-"+res.getString(2));
// }
}
}
运行结果如下图

代码中使用 hive on spark 可参考博客https://blog.csdn.net/Leeyehong_self/article/details/123878463

 浙公网安备 33010602011771号
浙公网安备 33010602011771号