直观理解为什么分类问题用交叉熵损失而不用均方误差损失?
博客:blog.shinelee.me | 博客园 | CSDN
交叉熵损失与均方误差损失
常规分类网络最后的softmax层如下图所示,传统机器学习方法以此类比,
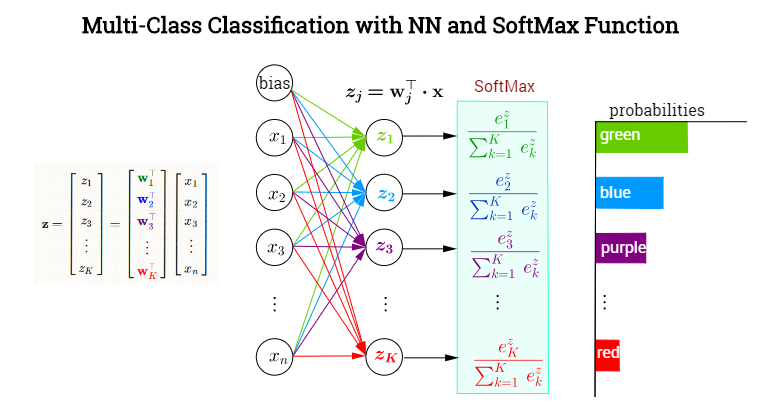
一共有类,令网络的输出为,对应每个类别的概率,令label为 。对某个属于类的样本,其label中,均为0。
对这个样本,交叉熵(cross entropy)损失为
均方误差损失(mean squared error,MSE)为
则个样本的损失为
对比交叉熵损失与均方误差损失,只看单个样本的损失即可,下面从两个角度进行分析。
损失函数角度
损失函数是网络学习的指挥棒,它引导着网络学习的方向——能让损失函数变小的参数就是好参数。
所以,损失函数的选择和设计要能表达你希望模型具有的性质与倾向。
对比交叉熵和均方误差损失,可以发现,两者均在时取得最小值0,但在实践中只会趋近于1而不是恰好等于1,在的情况下,
- 交叉熵只与label类别有关,越趋近于1越好
- 均方误差不仅与有关,还与其他项有关,它希望越平均越好,即在时取得最小值
分类问题中,对于类别之间的相关性,我们缺乏先验。
虽然我们知道,与“狗”相比,“猫”和“老虎”之间的相似度更高,但是这种关系在样本标记之初是难以量化的,所以label都是one hot。
在这个前提下,均方误差损失可能会给出错误的指示,比如猫、老虎、狗的3分类问题,label为,在均方误差看来,预测为要比要好,即认为平均总比有倾向性要好,但这有悖我们的常识。
而对交叉熵损失,既然类别间复杂的相似度矩阵是难以量化的,索性只能关注样本所属的类别,只要越接近于1就好,这显示是更合理的。
softmax反向传播角度
softmax的作用是将的几个实数映射到之间且之和为1,以获得某种概率解释。
令softmax函数的输入为,输出为,对结点有,
不仅与有关,还与有关,这里仅看,则有
为正确分类的概率,为0时表示分类完全错误,越接近于1表示越正确。根据链式法则,按理来讲,对与相连的权重,损失函数的偏导会含有这一因子项,时分类错误,但偏导为0,权重不会更新,这显然不对——分类越错误越需要对权重进行更新。
对交叉熵损失,
则有
恰好将中的消掉,避免了上述情形的发生,且越接近于1,偏导越接近于0,即分类越正确越不需要更新权重,这与我们的期望相符。
而对均方误差损失,
则有,
显然,仍会发生上面所说的情况——,分类错误,但不更新权重。
综上,对分类问题而言,无论从损失函数角度还是softmax反向传播角度,交叉熵都比均方误差要好。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!