人脸检测中,如何构建输入图像金字塔
博客:blog.shinelee.me | 博客园 | CSDN
写在前面
在文章《特征,特征不变性,尺度空间与图像金字塔》中我们初步谈到了图像金字塔,在这篇文章中将介绍如何在人脸检测任务中构建输入图像金子塔。
人脸检测中的图像金字塔
人脸检测任务,输入是一张图像,输出图像中人脸所在位置的Bounding Box。因为卷积神经网络强大的特征表达能力,现在的人脸检测方法通常都基于卷积神经网络,如MTCNN等。网络确定后,通常只适用于检测一定尺寸范围内的人脸,比如MTCNN中的P-Net,用于判断\(12 \times 12\)大小范围内是否含有人脸,但是输入图像中人脸的尺寸是未知的,因此需要构建图像金字塔,以获得不同尺寸的图像,只要某个人脸被放缩到\(12\times12\)左右,就可以被检测出来。下图为MTCNN 的Pipeline,来自链接。

构建金字塔需要解决几个问题:
- 金字塔要建多少层,即一共要生成多少张图像
- 每张图像的尺寸如何确定
下面直接从代码层面看是如何实现的,也可以直接跳到总结查看结论。
代码实现
MTCNN
以下为MTCNN 人脸检测 matlab代码
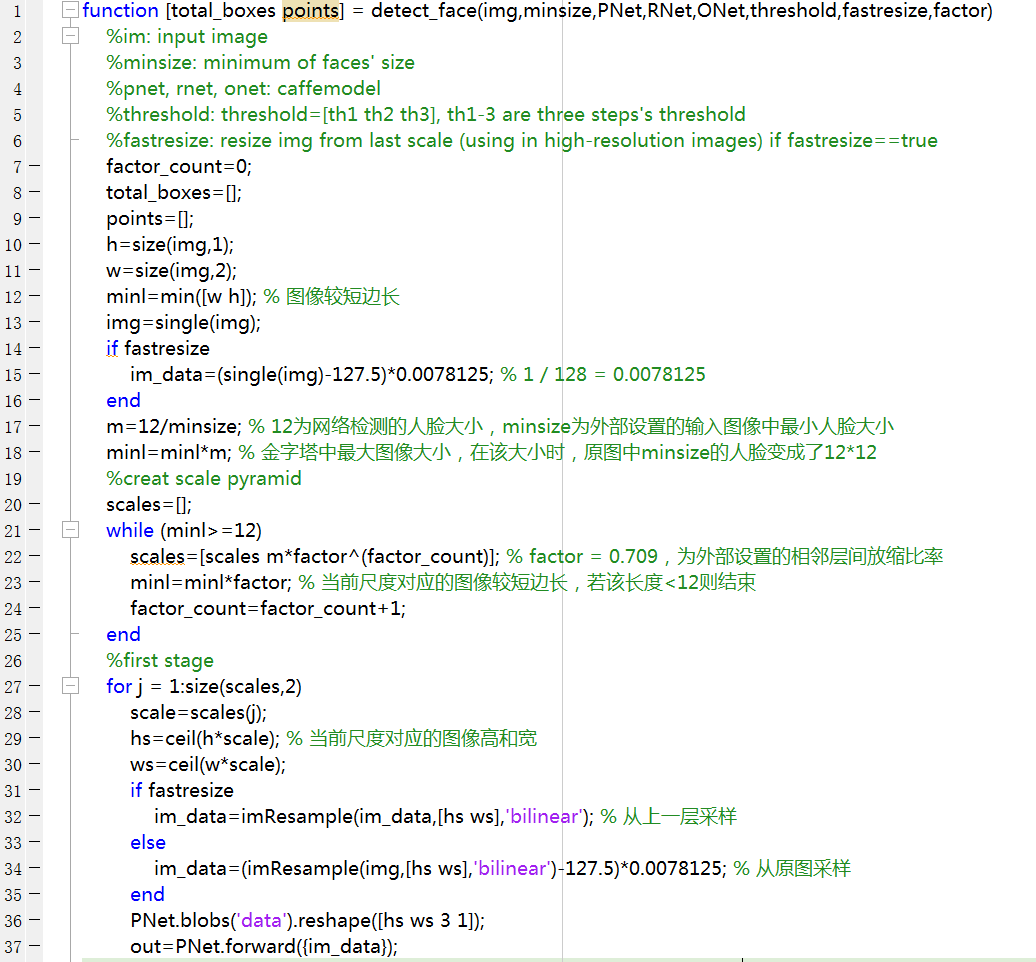
在人脸检测,通常要设置要原图中要检测的最小人脸尺寸,原图中小于这个尺寸的人脸不必care,MTCNN代码中为minsize=20,MTCNN P-Net用于检测\(12\times12\)大小的人脸。如果输入图像为\(100 \times 120\),其中人脸最小为\(20 \times 20\),最大为\(100 \times 100\)——对应图像较短边长,为了将人脸放缩到\(12 \times 12\),同时保证相邻层间缩放比率factor=0.709,则金子塔中图像尺寸依次为\(60 \times 72\)、\(52 \times 61\)、\(36 \times 43\)、\(26 \times 31\)、\(18 \times 22\)、\(13 \times 16\),其中\(60 \times 72\)对应把\(20\times 20\)的人脸缩放到\(12 \times 12\),\(13 \times 16\)对应把\(100 \times 100\)的人脸缩放到\(12 \times 12\)(在保证缩放比率一致的情况下近似)。
现在就可以回答上面的两个问题了:
- 给定输入图像,根据设置的最小人脸尺寸以及网络能检测的人脸尺寸,确定图像金子塔中最大图像和最小图像
- 根据设置的金字塔层间缩放比率,确定每层图像的尺寸
Seetaface
可以再看一下Seetaface中是如何构建图像金字塔的,Seetaface人脸检测使用的是非深度学习的方法,检测窗口大小impl_->kWndSize = 40,其对应MTCNN中网络适宜检测的人脸大小。
// 设置最大人脸,计算最大
void FaceDetection::SetMinFaceSize(int32_t size) {
if (size >= 20) {
impl_->min_face_size_ = size;
impl_->img_pyramid_.SetMaxScale(impl_->kWndSize / static_cast<float>(size));
}
}
// 设置最大尺度
inline void SetMaxScale(float max_scale) {
max_scale_ = max_scale;
scale_factor_ = max_scale;
UpdateBufScaled();
}
// 设置最小人脸
void FaceDetection::SetMaxFaceSize(int32_t size) {
if (size >= 0)
impl_->max_face_size_ = size;
}
// 设置相邻层放缩比率
void FaceDetection::SetImagePyramidScaleFactor(float factor) {
if (factor >= 0.01f && factor <= 0.99f)
impl_->img_pyramid_.SetScaleStep(static_cast<float>(factor));
}
// 在金字塔中检测人脸
std::vector<seeta::FaceInfo> FaceDetection::Detect(
const seeta::ImageData & img) {
int32_t min_img_size = img.height <= img.width ? img.height : img.width;
min_img_size = (impl_->max_face_size_ > 0 ? (min_img_size >= impl_->max_face_size_ ?
impl_->max_face_size_ : min_img_size) : min_img_size);
// ...
// 最小尺度为 impl_->kWndSize / min_img_size,在Seetaface中impl_->kWndSize=40
impl_->img_pyramid_.SetMinScale(static_cast<float>(impl_->kWndSize) / min_img_size);
// ...
impl_->pos_wnds_ = impl_->detector_->Detect(&(impl_->img_pyramid_));
// ...
}
// 金子塔中对应尺度的图像
const seeta::ImageData* ImagePyramid::GetNextScaleImage(float* scale_factor) {
// initial scale_factor_ = max_scale = impl_->kWndSize / min_face_size
if (scale_factor_ >= min_scale_) { // min_scale_ = impl_->kWndSize / min_img_size
if (scale_factor != nullptr)
*scale_factor = scale_factor_;
width_scaled_ = static_cast<int32_t>(width1x_ * scale_factor_);
height_scaled_ = static_cast<int32_t>(height1x_ * scale_factor_);
seeta::ImageData src_img(width1x_, height1x_);
seeta::ImageData dest_img(width_scaled_, height_scaled_);
src_img.data = buf_img_;
dest_img.data = buf_img_scaled_;
seeta::fd::ResizeImage(src_img, &dest_img);
scale_factor_ *= scale_step_;
img_scaled_.data = buf_img_scaled_;
img_scaled_.width = width_scaled_;
img_scaled_.height = height_scaled_;
return &img_scaled_;
} else {
return nullptr;
}
}
看代码就很清晰了,与MTCNN是相通的。
总结
人脸检测中的图像金字塔构建,涉及如下数据:
- 输入图像尺寸,定义为
(h, w) - 最小人脸尺寸,定义为
min_face_size - 最大人脸尺寸,如果不设置,为图像高宽中较短的那个,定义为
max_face_size - 网络/方法能检测的人脸尺寸,定义为
net_face_size - 金字塔层间缩放比率,定义为
factor
缩放图像是为了将图像中的人脸缩放到网络能检测的适宜尺寸,图像金字塔中
最大尺度max_scale = net_face_size / min_face_size,
最小尺度min_scale = net_face_size / max_face_size,
中间的尺度scale_n = max_scale * (factor ^ n),
对应的图像尺寸为(h_n, w_n) = (h * scale_n, w_n * scale_n)。
以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号