
PYTHON DAY5 TENSORFLOW之定义一个SLP模型
读数总结:使用tf构建一个简单的SLP模型,部分定义需要在上一学习笔记中复习。
分为导入模块、数据构建、模型定义、学习阶段、测试及准确率计算,共五个部分。
##5.1 导入模块
此次建模主要用到numpy用于构建数据,TensorFlow用于构建模型,matplotlib用于数据可视化。
##5.2 数据构建
本次学习的数据是11个点的坐标及对应的点的类型,建模的目标是找到一条直线能够正确划分两类点。
inputX是用于训练模型的点坐标,使用浮点格式便于深度学习算法的需要(这样就可以输出一个点是这类的可能性概率值)
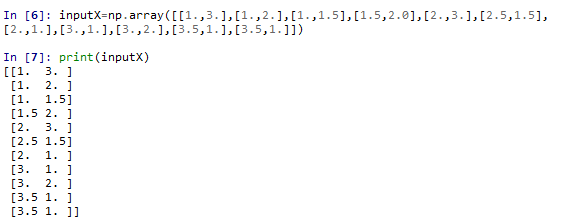
inputY是用于训练模型的点类型

接下来将数据画在图上,并按照类型区分点的颜色,直观理解数据。
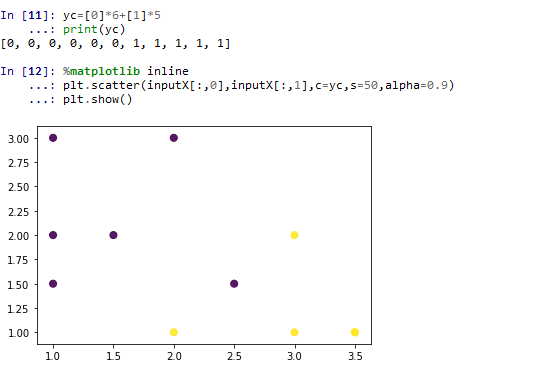
首先:生成颜色变量(yc),取类型的值,在图中作为颜色的值,可以将不同类型的点化成不同的颜色;
然后:使用点的第一列作为x轴的坐标,第二列作为y轴的坐标,使用类型作为颜色,绘制图形。
可以直观发现左上角的点是第一类,右下角的点是第二类。
##5.3 模型定义
在进行学习之前,需要先把模型定义出来,书上是通过定义许多参数来实现SLP的构建的,具体定义的参数包括学习率、学习轮数、监控轮数、数据维度、每批学习的维度、总共需要学习的批数、输入、输出、权重、偏置、凭据、输出概率值、损失函数、优化器,通过定义他们、层层嵌套,实现网络的隐式定义,以及显示定义输入及输出的张量。
定义学习率learning_rate:调整神经网络效率(在实际过程中,它的值是通过不同测试调整这个参数来找到能使准确率最高的一个值,这里是直接给出的通用值0.01);这个参数在后面通过定义优化器optimizer中通过tf.train,GradientDescentOptimizer来使用,优化器则直接在学习阶段得到执行。

定义学习轮数training_epochs:设定学习阶段神经网络训练的轮数;这个参数直接在学习阶段通过控制循环的次数来参与模型定义。

定义监控轮数display_epochs:设定学习结论学习多少次的时候输出一次阶段性成果,来监控学习进展,合理取值一般是50~100,输出的结果保存起来能够量化学习过程的优化效果。直接在学习过程中调用。

定义数据维度n_sample、每批学习的维度batch_size、总共需要学习的批数total_batch:用于提高代码的可重复性,可通过这些参数来指定训练集的元素数量以及所需批次(但是在本次学习中,由于只有11个元素,并没有用到)。n_sample在计算mse的公式中调用了。
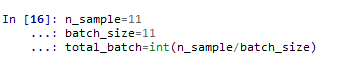
定义输入数据维度n_input、输出数据的类别数量n_classes:在定义输入、输出的时候,调用这两个参数来确定输入输出的维度。
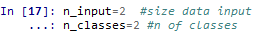
定义输入张量x、输出张量y:用占位符来定义神经网络的输入和输出,用于存放整个神经网络所需的数据。x、y通过既定义凭据来参与学习过程,也在学习过程中直接参与优化器的执行。
实际上这里就已经隐式定义了一个SLP模型,他的输入层有n_input个也就是2个神经元,输出层是n_classes个也是2个输出神经元,定义输入占位符x和输出占位符y各有2个值。
注:tf.placeholder(dtype,shape)就是用指定类型的数据占位指定形状的数据,其中shape形状默认是None也就是一维数据,在本学习的例子张量x里,是定义了未知行数、n_input列的浮点数据用于存放数据。

定义权重W、偏置b:定义W、b的占位符,用于存放建立的模型y_=Wx+b的相关参数,使用zeros函数初始化为0,在凭据中作为数学公式的一部分参与学习。

凭据evidence:通过matmul(相乘)和add(相加)两个函数构建了y_=Wx+b的数学公式,这个参数就是用数学公式描述神经网络的本体(这个例子中直接知道公式了),但因为输出的值是数,还需要转换为输出值的概率值。通过定义y_参与学习过程。
输出概率值y_:根据凭据的值,计算的输出值的概率,也就是点是某类的概率值。这个参数通过定义cost参与学习过程,并且是一个输出值,在学习完成后作为输出来打印,直接决定了点的类型。
注:tf.nn.softmax()归一化指数函数。将含有任意实数的K维向量A压缩到一个K维向量B中,使得B中每一个元素都在(0,1)之间,并且所有元素相加的和为1。得到的值通常可以认为是各种分类的概率。

损失函数cost:用损失函数来确定上面所有参数最小化的规则,这里是MSE的计算公式。首先通过pow函数计算(y-y_)的2次幂,然后用reduce函数将每个“(y-y_)的2次幂”求和,然后去除以2倍n_sample,得到MSE的值。这个参数通过参与优化器的定义进入学习过程,并且是一个每轮计算都会打印出来的、直观展示优化效果的重要参数值。
优化器optimizer:定义了损失函数后,通过这个算法,在每轮学习执行最小化代价函数值的操作。这里是用的tf.train,GradientDescentOptimizer函数作为优化器,它基于梯度下降算法。这个参数直接在学习过程中调用。

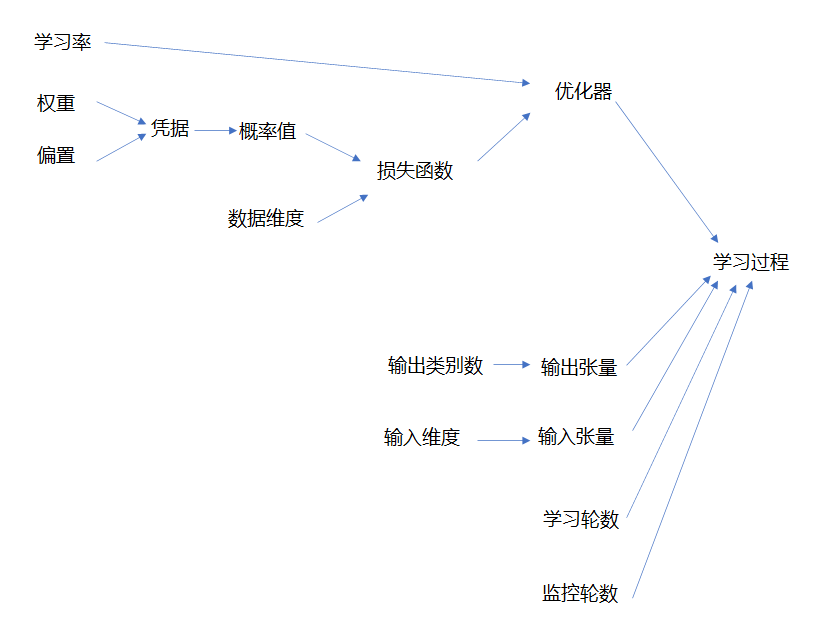
至此,参数已经全部完成定义,它们参与学习过程的逻辑是下图这样的(有点糙)。总之,直接参与学习过程的是这4个参数,其他参数都是间接参与和控制学习过程,但其中最优权重、偏置是属于最优模型的参数(也就是建模的模型本身),概率值是输出,损失函数是量化优化效果的值,在学习过程中还是有直观的展示和应用的。
##5.4 学习阶段
完成参数定义后,就可以进入学习阶段,学习阶段包括定义学习结果列表、学习过程(初始化→学习→学习结果输出)、优化过程可视化、学习结果可视化,共4个部分。
结果列表和初始化函数
开始学习之前,先定义几个列表用于存储学习阶段的结果,在优化过程可视化中会用到这两个绘制代价趋势来了解神经网络所用学习方法的效率。
定义avg_set:存放每轮的mse(损失函数值、代价)
定义epoch_set:存放次的轮数。
定义初始化函数init:来初始化全局变量的定义

学习过程如图(初始化→学习→学习结果输出)

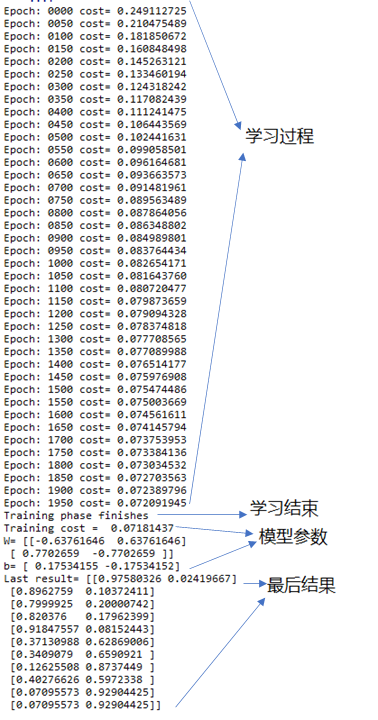
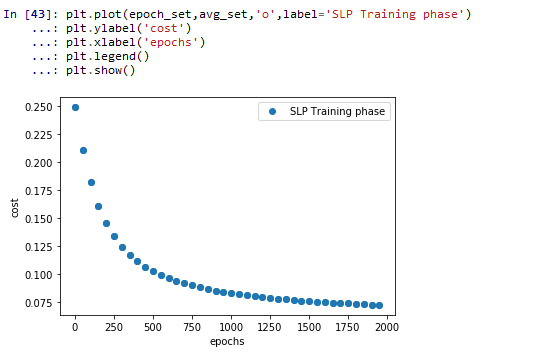
结果如图:可以看到每轮的cost都有变小,最后到了0.07左右
优化过程可视化:分析神经网络学习阶段的代价趋势
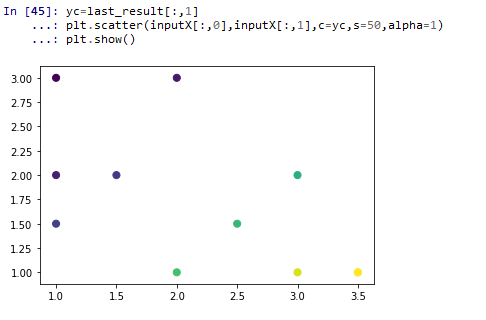
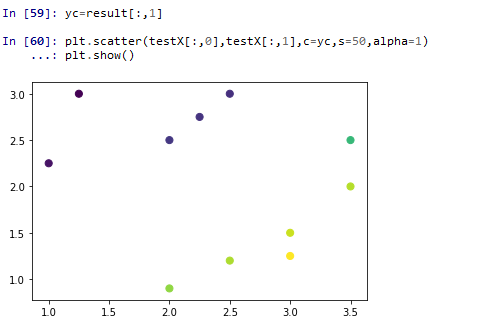
学习结果可视化:把概率值作为颜色绘图,可以看到深色的是第一类点,浅色的是第二类点,中间的三个点类别不太确定但应归为第二类,也就是点(2.5,1.5)没能成功判断(这符合预期,这个点是代表了例外情况,为了增加第二类的不确定性而设置的)
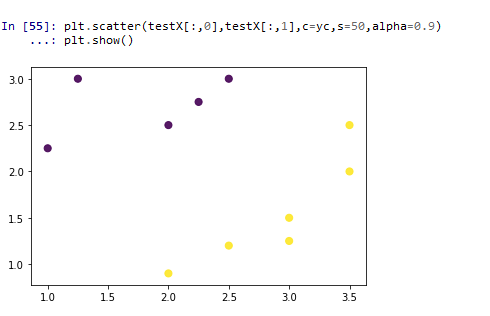
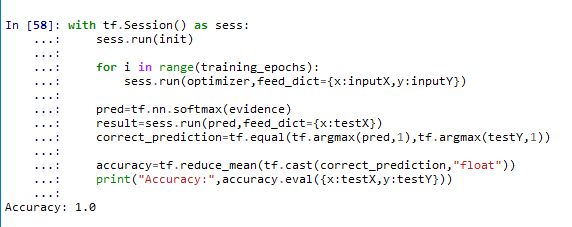
##5.5 测试及准确率计算
累了,不写了,大概是一个构件测试数据、可视化测试数据、评估SLP模型(这部分笔记见书上247页)、可视化测试结果的过程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号