
python Day1 数据
day01:数据处理工具Pandas
买了本新书,写点笔记.
----
准备数据

## 1.1数据读取与存储
read_csv()
- filepath_or_buffer
- sep : 默认逗号
- delimiter : 可选, 作为sep配置分隔符的别名
- delim_whitespace : 配置是否用空格作为分隔符, 如果值为True, 那么sep参数就失效了
- header : 配置用行数作为列名,默认为自动推断
- names : 列名,如果目标文件没有表头, 则需要配置header=None, 否则第一行会被配置为列名
- usecols : 用来选择读取csv文件的指定列名
- dtype : 配置所读数据的类型
- encoding : 一般使用UTF-8或者GBK
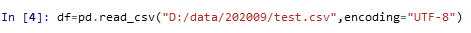
to_csv()
- path_or_buf
- sep
- na_rep : 配置空值补全的值, 默认用空格
- float_format : 配置将浮点数转为字符串
- columns : 配置需要写入列的列名, 默认从第一列开始写入
- header : 配置是否写入列名, 默认写入
- index : 配置是否写入行名, 默认写入
- index_label : 配置用来作为列索引的列
- mode : 写入模式, 默认为W
- encoding : 编码, 只针对py3以前的版本
- line_terminator : 配置每行的结束符, 默认\n
- quotin : csv引用规则
- quotechar : 配置用来作为引用的空格,默认空格
- chunksize : 配置每次写入的行数
- tuplesize_cols : 写入list的格式,默认是元组
- date_format : 配置时间数据的格式

to_json()
- path_or_buf
- data_format : 配置时间数据的格式,epoch表示配置成时间戳的格式,iso表示配置成ISO 8601格式
- double_precision : 配置小数点后保留的位数,默认10位
- force_ascii : 是否强制将String转码为ASCII,默认转
- date_unit : 配置时间数据的格式,可以精确到秒级或毫秒级

read_json()
- filepath_or_buffer
- type : 配置生成Series或是DataFrame,默认后者

## 1.2数据查看
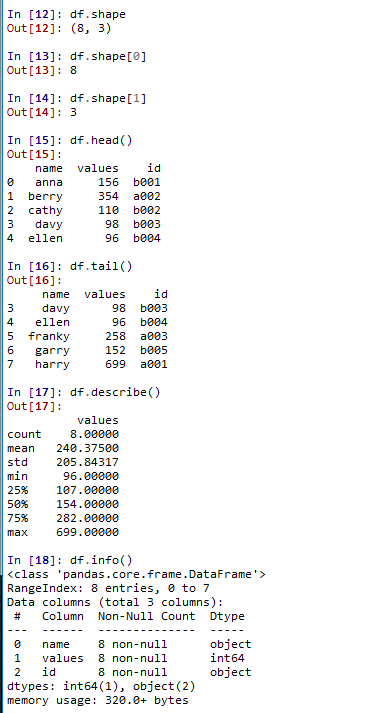
df.shape #查看数据的维度,shape[0]返回行数,shape[1]返回列数
df.head() #返回前五行,可以将想看的行数传进去
df.tail() #返回后五行
df.describe() #数据汇总
df.info() #查看数据情况
## 1.3数据选择
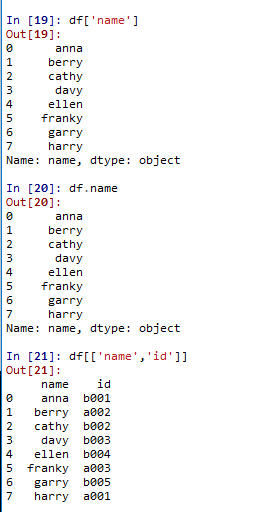
(1)用列名选择
df[col_name]
df.colname
df[[col1,col2]]
(2)用索引选择
df.iloc[1] #第二行元素
df.loc[0] #取行索引叫0的行

## 1.4数据合并
pd.concat([df1,df2]) #按行拼接数据
pd.merge(df1,df3,on='id') #按列进行拼接
pd.append() #增加某列的数据

## 1.5数据清理
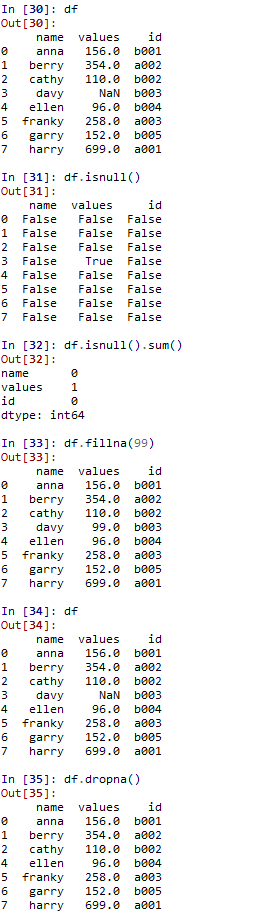
df.isnull() #检查是否是空值
df.isnull().sum() #空值的统计,按列
df.fillna(n) #用n替换空值
df.dropna() #删除包含空值的行或者列,默认删除行,输入参数axis=1则删除包含空值的列

## 1.6数据处理
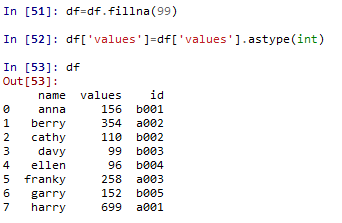
df.astype() #转换数据类型
df['values'].astype(float)#将df数据中的values列转换为float格式
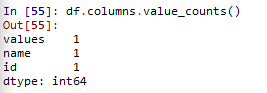
df.columns.value_counts() #统计唯一值的个数
df.sort_values(by=colname,ascending=True) #序列排序

以上为全部内容■■■

 浙公网安备 33010602011771号
浙公网安备 33010602011771号