redis持久化
本次主要是对redis中著名的持久化策略进行代码层面描述,主要包括RDB持久化和AOF持久化
因为AOF文件的更新频率比RDB高,所以如果服务器开启AOF持久化,redis优先使用AOF文件还原,只有当AOF持久化关闭,才使用RDB文件进行还原
RDB持久化
RDB持久化主要有两个命令实现:SAVE和BGSAVE
SAVE、BGSAVE
SAVE会阻塞redis服务器,知道RDB文件创建完毕
void saveCommand(redisClient *c) {
// BGSAVE 已经在执行中,不能再执行 SAVE
// 否则将产生竞争条件
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
return;
}
// 执行
if (rdbSave(server.rdb_filename) == REDIS_OK) {
addReply(c,shared.ok);
} else {
addReply(c,shared.err);
}
}
BGSAVE不会阻塞,他会创建一个子进程,由子进程处理RDB文件保存
void bgsaveCommand(redisClient *c) {
// 不能重复执行 BGSAVE
if (server.rdb_child_pid != -1) {
addReplyError(c,"Background save already in progress");
// 不能在 BGREWRITEAOF 正在运行时执行
} else if (server.aof_child_pid != -1) {
addReplyError(c,"Can't BGSAVE while AOF log rewriting is in progress");
// 执行 BGSAVE
} else if (rdbSaveBackground(server.rdb_filename) == REDIS_OK) {
addReplyStatus(c,"Background saving started");
} else {
addReply(c,shared.err);
}
}
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
// 如果 BGSAVE 已经在执行,那么出错
if (server.rdb_child_pid != -1) return REDIS_ERR;
// 记录 BGSAVE 执行前的数据库被修改次数
server.dirty_before_bgsave = server.dirty;
// 最近一次尝试执行 BGSAVE 的时间
server.lastbgsave_try = time(NULL);
// fork() 开始前的时间,记录 fork() 返回耗时用
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
/* 子进程 */
// 关闭网络连接 fd
closeListeningSockets(0);
// 设置进程的标题,方便识别
redisSetProcTitle("redis-rdb-bgsave");
// 执行保存操作
retval = rdbSave(filename);
// 打印 copy-on-write 时使用的内存数
if (retval == REDIS_OK) {
size_t private_dirty = zmalloc_get_private_dirty();
if (private_dirty) {
redisLog(REDIS_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
}
// 向父进程发送信号
exitFromChild((retval == REDIS_OK) ? 0 : 1);
} else {
/* 父进程 */
// 计算 fork() 执行的时间
server.stat_fork_time = ustime()-start;
// 如果 fork() 出错,那么报告错误
if (childpid == -1) {
server.lastbgsave_status = REDIS_ERR;
redisLog(REDIS_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return REDIS_ERR;
}
// 打印 BGSAVE 开始的日志
redisLog(REDIS_NOTICE,"Background saving started by pid %d",childpid);
// 记录数据库开始 BGSAVE 的时间
server.rdb_save_time_start = time(NULL);
// 记录负责执行 BGSAVE 的子进程 ID
server.rdb_child_pid = childpid;
// 关闭自动 rehash
updateDictResizePolicy();
return REDIS_OK;
}
return REDIS_OK; /* unreached */
}
两个命令内部都是执行rdbSave函数
/*
* 将数据库保存到磁盘上。
* 保存成功返回 REDIS_OK ,出错/失败返回 REDIS_ERR 。
*/
int rdbSave(char *filename) {
dictIterator *di = NULL;
dictEntry *de;
char tmpfile[256];
char magic[10];
int j;
long long now = mstime();
FILE *fp;
rio rdb;
uint64_t cksum;
// 创建临时文件
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
redisLog(REDIS_WARNING, "Failed opening .rdb for saving: %s",
strerror(errno));
return REDIS_ERR;
}
// 初始化 I/O
rioInitWithFile(&rdb,fp);
// 设置校验和函数
if (server.rdb_checksum)
rdb.update_cksum = rioGenericUpdateChecksum;
// 写入 RDB 版本号
snprintf(magic,sizeof(magic),"REDIS%04d",REDIS_RDB_VERSION);
// 写入错误,跳转到werr
if (rdbWriteRaw(&rdb,magic,9) == -1) goto werr;
// 遍历所有数据库
for (j = 0; j < server.dbnum; j++) {
// 指向数据库
redisDb *db = server.db+j;
// 指向数据库键空间
dict *d = db->dict;
// 跳过空数据库
if (dictSize(d) == 0) continue;
// 创建键空间迭代器
di = dictGetSafeIterator(d);
if (!di) {
fclose(fp);
return REDIS_ERR;
}
/*
* 写入 DB 选择器
*/
if (rdbSaveType(&rdb,REDIS_RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(&rdb,j) == -1) goto werr;
/*
* 遍历数据库,并写入每个键值对的数据
*/
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
// 根据 keystr ,在栈中创建一个 key 对象
initStaticStringObject(key,keystr);
// 获取键的过期时间
expire = getExpire(db,&key);
// 保存键值对数据
if (rdbSaveKeyValuePair(&rdb,&key,o,expire,now) == -1) goto werr;
}
dictReleaseIterator(di);
}
di = NULL; /* So that we don't release it again on error. */
/*
* 写入 EOF 代码
*/
if (rdbSaveType(&rdb,REDIS_RDB_OPCODE_EOF) == -1) goto werr;
/*
* CRC64 校验和。
*
* 如果校验和功能已关闭,那么 rdb.cksum 将为 0 ,
* 在这种情况下, RDB 载入时会跳过校验和检查。
*/
cksum = rdb.cksum;
memrev64ifbe(&cksum);
rioWrite(&rdb,&cksum,8);
// 冲洗缓存,确保数据已写入磁盘
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/*
* 使用 RENAME ,原子性地对临时文件进行改名,覆盖原来的 RDB 文件。
*/
if (rename(tmpfile,filename) == -1) {
redisLog(REDIS_WARNING,"Error moving temp DB file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return REDIS_ERR;
}
// 写入完成,打印日志
redisLog(REDIS_NOTICE,"DB saved on disk");
// 清零数据库脏状态
server.dirty = 0;
// 记录最后一次完成 SAVE 的时间
server.lastsave = time(NULL);
// 记录最后一次执行 SAVE 的状态
server.lastbgsave_status = REDIS_OK;
return REDIS_OK;
werr:
// 关闭文件
fclose(fp);
// 删除文件
unlink(tmpfile);
redisLog(REDIS_WARNING,"Write error saving DB on disk: %s", strerror(errno));
if (di) dictReleaseIterator(di);
return REDIS_ERR;
}
RDB文件内容
首先给出一个完整的RDB文件的格式

后续为描述方便,大写为常量,小写为变量或者数据
REDIS这个其实就是RDB文件的标识符db_version长度4字节,记录RDB文件的版本号,redis3.0一般使用0006(第六版)databases表示任意个数据库EOF表示正文内容结束check_sum校验和,8字节,通过前面4部分内容计算得出
下面重点说下databases字段,每个database都是包括如下几个部分。

-
SELECTDB一字节,表示接下来要读一个数据库号码 -
db_number表示一个数据库号码,长度1、2、5字节,当读入该数字后,redis会调用select命令进行数据库切换 -
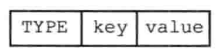
key_value_pairs表示数据库中所有的键值对数据,其中又分为不带过期时间的键值对,和带过期时间的键值对- 不带过期的键值对,由
TYPE、key、value组成
![]()
- 带过期的键值对,由
EXPIRETIME_MS、ms、TYPE、key、value组成
![image-20220416100544203]()
- 不带过期的键值对,由

AOF持久化
AOF持久化是通过保存redis服务器在运行期间所执行的写命令进行记录数据,AOF持久化分为命令追加、文件写入、文件同步三个步骤,下面分别对这三个步骤进行阐述
命令追加
当AOF持久化处于打开的状态,服务器在执行一个写命令之后,会以某种协议的方式将被执行的写命令追加到服务器redisServer中的aof_buf缓冲区末尾
文件写入与同步
上一次我们说到,redis在运行过程中,是一个事件循环,每次循环执行对应的时间事件和文件事件,因此AOF持久化的写入也在每次事件循环结束后进行,执行函数flushAppendOnlyFile
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
// 缓冲区中没有任何内容,直接返回
if (sdslen(server.aof_buf) == 0) return;
// 策略为每秒 FSYNC
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
// 是否有 SYNC 正在后台进行?
sync_in_progress = bioPendingJobsOfType(REDIS_BIO_AOF_FSYNC) != 0;
// 每秒 fsync ,并且强制写入为假
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
/*
* 当 fsync 策略为每秒钟一次时, fsync 在后台执行。
* 如果后台仍在执行 FSYNC ,那么我们可以延迟写操作一两秒
* (如果强制执行 write 的话,服务器主线程将阻塞在 write 上面)
*/
if (sync_in_progress) {
// 有 fsync 正在后台进行 。。。
if (server.aof_flush_postponed_start == 0) {
/*
* 前面没有推迟过 write 操作,这里将推迟写操作的时间记录下来
* 然后就返回,不执行 write 或者 fsync
*/
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
/*
* 如果之前已经因为 fsync 而推迟了 write 操作
* 但是推迟的时间不超过 2 秒,那么直接返回
* 不执行 write 或者 fsync
*/
return;
}
/*
* 如果后台还有 fsync 在执行,并且 write 已经推迟 >= 2 秒
* 那么执行写操作(write 将被阻塞)
*/
server.aof_delayed_fsync++;
redisLog(REDIS_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
/*
* 执行到这里,程序会对 AOF 文件进行写入。
* 清零延迟 write 的时间记录
*/
server.aof_flush_postponed_start = 0;
/*
* 执行单个 write 操作,如果写入设备是物理的话,那么这个操作应该是原子的
*
* 当然,如果出现像电源中断这样的不可抗现象,那么 AOF 文件也是可能会出现问题的
* 这时就要用 redis-check-aof 程序来进行修复。
*/
nwritten = write(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
if (nwritten != (signed)sdslen(server.aof_buf)) {
static time_t last_write_error_log = 0;
int can_log = 0;
// 将日志的记录频率限制在每行 AOF_WRITE_LOG_ERROR_RATE 秒
if ((server.unixtime - last_write_error_log) > AOF_WRITE_LOG_ERROR_RATE) {
can_log = 1;
last_write_error_log = server.unixtime;
}
// 如果写入出错,那么尝试将该情况写入到日志里面
if (nwritten == -1) {
if (can_log) {
redisLog(REDIS_WARNING,"Error writing to the AOF file: %s",
strerror(errno));
server.aof_last_write_errno = errno;
}
} else {
if (can_log) {
redisLog(REDIS_WARNING,"Short write while writing to "
"the AOF file: (nwritten=%lld, "
"expected=%lld)",
(long long)nwritten,
(long long)sdslen(server.aof_buf));
}
// 尝试移除新追加的不完整内容
if (ftruncate(server.aof_fd, server.aof_current_size) == -1) {
if (can_log) {
redisLog(REDIS_WARNING, "Could not remove short write "
"from the append-only file. Redis may refuse "
"to load the AOF the next time it starts. "
"ftruncate: %s", strerror(errno));
}
} else {
/* If the ftrunacate() succeeded we can set nwritten to
* -1 since there is no longer partial data into the AOF. */
nwritten = -1;
}
server.aof_last_write_errno = ENOSPC;
}
// 处理写入 AOF 文件时出现的错误
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* We can't recover when the fsync policy is ALWAYS since the
* reply for the client is already in the output buffers, and we
* have the contract with the user that on acknowledged write data
* is synched on disk. */
redisLog(REDIS_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting...");
exit(1);
} else {
/* Recover from failed write leaving data into the buffer. However
* set an error to stop accepting writes as long as the error
* condition is not cleared. */
server.aof_last_write_status = REDIS_ERR;
/* Trim the sds buffer if there was a partial write, and there
* was no way to undo it with ftruncate(2). */
if (nwritten > 0) {
server.aof_current_size += nwritten;
sdsrange(server.aof_buf,nwritten,-1);
}
return; /* We'll try again on the next call... */
}
} else {
// 写入成功,更新最后写入状态
if (server.aof_last_write_status == REDIS_ERR) {
redisLog(REDIS_WARNING,
"AOF write error looks solved, Redis can write again.");
server.aof_last_write_status = REDIS_OK;
}
}
// 更新写入后的 AOF 文件大小
server.aof_current_size += nwritten;
/*
* 如果 AOF 缓存的大小足够小的话,那么重用这个缓存,
* 否则的话,释放 AOF 缓存。
*/
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
// 清空缓存中的内容,等待重用
sdsclear(server.aof_buf);
} else {
// 释放缓存
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
/*
* 如果 no-appendfsync-on-rewrite 选项为开启状态,
* 并且有 BGSAVE 或者 BGREWRITEAOF 正在进行的话,
* 那么不执行 fsync
*/
if (server.aof_no_fsync_on_rewrite &&
(server.aof_child_pid != -1 || server.rdb_child_pid != -1))
return;
// 总是执行 fsnyc
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* aof_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
aof_fsync(server.aof_fd); /* Let's try to get this data on the disk */
// 更新最后一次执行 fsnyc 的时间
server.aof_last_fsync = server.unixtime;
// 策略为每秒 fsnyc ,并且距离上次 fsync 已经超过 1 秒
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
// 放到后台执行
if (!sync_in_progress) aof_background_fsync(server.aof_fd);
// 更新最后一次执行 fsync 的时间
server.aof_last_fsync = server.unixtime;
}
}
在上面代码中,我们可以看到执行fsync有几种可能,这些可能性通过appendfsync配置进行决定
| appendfsync选项的值 | flushappendonlyfile函数行为 |
|---|---|
| always | 将aof_buf缓冲区所有内容写入并同步到AOF文件 |
| everysec | 将aof buf缓冲区中的所有内容写入到AOF文件,如果上次同步AOF文件的时间距离现在超过一秒钟,那么再次对AOF 文件进行同步,并且这个同步操作是由一个线程专门负责执行的 |
| no | 将aof_buf缓冲区中的所有内容写入到AOF文件,但并不对AOF文件进行同步,何时同步由操作系统来决定 |
AOF重写
由AOF写入原理可知,每次执行命令,都会向文件中写入命令,那么这就会导致文件较大,而且对于比如这种情况:先添加一个a键,再删除一个a键,这其实最终的效果是和最初一样的,若将两次执行命令都写入,则其实是没有用的,因此redis采用AOF重写的方式,函数为rewriteAppendOnlyFileBackground
/*
* 以下是后台重写 AOF 文件(BGREWRITEAOF)的工作步骤:
*
* 1) 用户调用 BGREWRITEAOF
*
* 2) Redis 调用这个函数,它执行 fork() :
*
* 2a) 子进程在临时文件中对 AOF 文件进行重写
*
* 2b) 父进程将新输入的写命令追加到 server.aof_rewrite_buf 中
*
* 3) 当步骤 2a 执行完之后,子进程结束
*
* 4)
* 父进程会捕捉子进程的退出信号,
* 如果子进程的退出状态是 OK 的话,
* 那么父进程将新输入命令的缓存追加到临时文件,
* 然后使用 rename(2) 对临时文件改名,用它代替旧的 AOF 文件,
* 至此,后台 AOF 重写完成。
*/
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start;
// 已经有进程在进行 AOF 重写了
if (server.aof_child_pid != -1) return REDIS_ERR;
// 记录 fork 开始前的时间,计算 fork 耗时用
start = ustime();
if ((childpid = fork()) == 0) {
char tmpfile[256];
/* 子进程 */
// 关闭网络连接 fd
closeListeningSockets(0);
// 为进程设置名字,方便记认
redisSetProcTitle("redis-aof-rewrite");
// 创建临时文件,并进行 AOF 重写
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
if (rewriteAppendOnlyFile(tmpfile) == REDIS_OK) {
size_t private_dirty = zmalloc_get_private_dirty();
if (private_dirty) {
redisLog(REDIS_NOTICE,
"AOF rewrite: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
// 发送重写成功信号
exitFromChild(0);
} else {
// 发送重写失败信号
exitFromChild(1);
}
} else {
/* 父进程 */
// 记录执行 fork 所消耗的时间
server.stat_fork_time = ustime()-start;
if (childpid == -1) {
redisLog(REDIS_WARNING,
"Can't rewrite append only file in background: fork: %s",
strerror(errno));
return REDIS_ERR;
}
redisLog(REDIS_NOTICE,
"Background append only file rewriting started by pid %d",childpid);
// 记录 AOF 重写的信息
server.aof_rewrite_scheduled = 0;
server.aof_rewrite_time_start = time(NULL);
server.aof_child_pid = childpid;
// 关闭字典自动 rehash
updateDictResizePolicy();
/*
* 将 aof_selected_db 设为 -1 ,
* 强制让 feedAppendOnlyFile() 下次执行时引发一个 SELECT 命令,
* 从而确保之后新添加的命令会设置到正确的数据库中
*/
server.aof_selected_db = -1;
replicationScriptCacheFlush();
return REDIS_OK;
}
return REDIS_OK; /* unreached */
AOF重写的原理,其实是直接读取当前的数据库的值,最后使用一条写语句就可以实现AOF重写
而且AOF重写是放在后台子进程执行,这样可以避免效率太低,但是使用子进程执行重写方式,则在重写过程中,父进程还会执行新的写命令,因此这段事件的命令也要被记录下来,最后再次同步给子进程
自己的网址:www.shicoder.top
欢迎加群聊天 452380935
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号