
redis数据库
这一次主要是接着redis服务器接着进行代码讲解,因为redis服务器中包含大量的数据库,因为redis也对每个数据库设计了结构体
redis数据库
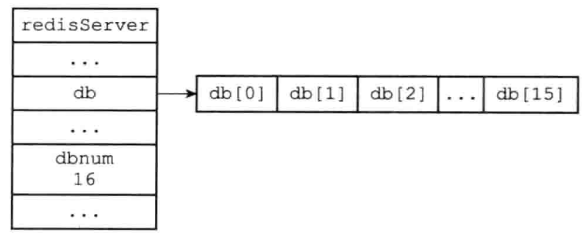
在上面redisServer中,有一个数组redisDb *db,这个数组中就是存放的是该服务器所有的数据库,redisDb就是数据库字段,redisServer中的dbnum就是该数组的大小
// redis服务器中每一个数据库都是这样一个实例
typedef struct redisDb {
// 数据库键空间,保存着数据库中的所有键值对
dict *dict;
// 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
dict *expires;
// 正处于阻塞状态的键
dict *blocking_keys;
// 可以解除阻塞的键
dict *ready_keys;
// 正在被 WATCH 命令监视的键
dict *watched_keys;
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
// 数据库号码
int id;
// 数据库的键的平均 TTL ,统计信息
long long avg_ttl;
} redisDb;
过期策略
在redisDb中,有一个字段为键的过期时间,因此针对过期的键,redis有一套自己的过期策略,下面进行讲解:
- 定时删除:在设置键过期时间的同时,创建一个定时器
- 惰性删除:每次要用这个键的时候,先检查是否过期
- 定期删除:每隔一段时间,对数据库键进行扫描,删除部分过期键
redis是使用惰性删除和定期删除配合实现的过期策略
惰性删除代码为db.c/expireIfNeeded,每次执行命令前都执行该函数
/*
* 检查 key 是否已经过期,如果是的话,将它从数据库中删除。
*
* 返回 0 表示键没有过期时间,或者键未过期。
*
* 返回 1 表示键已经因为过期而被删除了。
*
* 惰性删除 所有读写数据库的命令在执行前都会进行检查
*
*/
int expireIfNeeded(redisDb *db, robj *key) {
// 取出键的过期时间
mstime_t when = getExpire(db,key);
mstime_t now;
// 没有过期时间
if (when < 0) return 0;
// 如果服务器正在进行载入,那么不进行任何过期检查
if (server.loading) return 0;
/* If we are in the context of a Lua script, we claim that time is
* blocked to when the Lua script started. This way a key can expire
* only the first time it is accessed and not in the middle of the
* script execution, making propagation to slaves / AOF consistent.
* See issue #1525 on Github for more information. */
now = server.lua_caller ? server.lua_time_start : mstime();
// 当服务器运行在 replication 模式时
// 附属节点并不主动删除 key
// 它只返回一个逻辑上正确的返回值
// 真正的删除操作要等待主节点发来删除命令时才执行
// 从而保证数据的同步
if (server.masterhost != NULL) return now > when;
// 运行到这里,表示键带有过期时间,并且服务器为主节点
// 如果未过期,返回 0
if (now <= when) return 0;
/* Delete the key */
server.stat_expiredkeys++;
// 向 AOF 文件和附属节点传播过期信息
propagateExpire(db,key);
// 发送事件通知
notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED,
"expired",key,db->id);
// 将过期键从数据库中删除
return dbDelete(db,key);
}
定期删除代码为redis.c/activeExpireCycle,每当redis周期性执行redis.c/serverCron时候,就会调用该函数,它在规定的时间内,遍历各个数据库,随机检查一部分键,若过期则删除
/*
* 函数尝试删除数据库中已经过期的键。
* 当带有过期时间的键比较少时,函数运行得比较保守,
* 如果带有过期时间的键比较多,那么函数会以更积极的方式来删除过期键,
* 从而可能地释放被过期键占用的内存。
*
*
* 每次循环中被测试的数据库数目不会超过 REDIS_DBCRON_DBS_PER_CALL 。
*
*
* 如果 timelimit_exit 为真,那么说明还有更多删除工作要做,
* 那么在 beforeSleep() 函数调用时,程序会再次执行这个函数。
*
*
* 过期循环的类型:
*
*
* 如果循环的类型为 ACTIVE_EXPIRE_CYCLE_FAST ,
* 那么函数会以“快速过期”模式执行,
* 执行的时间不会长过 EXPIRE_FAST_CYCLE_DURATION 毫秒,
* 并且在 EXPIRE_FAST_CYCLE_DURATION 毫秒之内不会再重新执行。
*
* 如果循环的类型为 ACTIVE_EXPIRE_CYCLE_SLOW ,
* 那么函数会以“正常过期”模式执行,
* 函数的执行时限为 REDIS_HS 常量的一个百分比,
* 这个百分比由 REDIS_EXPIRELOOKUPS_TIME_PERC 定义。
*
* 定期删除 服务器周期性执行redis.c/serverConn时候会执行该函数
*
* 函数执行大概流程:
*
* 1、函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
*
* 2、全局变量current_db会记录当前activeExpireCycle函数检查的进度,
* 并在下一次activeExpireCycle函数调用时,接着上一次的进度进行处理。
* 比如说,如果当前activeExpirecycle函数在遍历10号数据库时返回了,
* 那么下次activeExpirecycle函数执行时,将从11号数据库开始查找并删除过期键。
*
* 3、随着activeExpireCycle函数的不断执行,服务器中的所有数据库都会被检查一遍,
* 这时函数将current_db变量重置为0,然后再次开始新一轮的检查工作。
*/
void activeExpireCycle(int type) {
// 静态变量,用来累积函数连续执行时的数据
// 表明目前检测到哪个数据库了
static unsigned int current_db = 0;
static int timelimit_exit = 0;
static long long last_fast_cycle = 0;
unsigned int j, iteration = 0;
// 默认每次处理的数据库数量
unsigned int dbs_per_call = REDIS_DBCRON_DBS_PER_CALL;
// 函数开始的时间
long long start = ustime(), timelimit;
// 快速模式
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
// 如果上次函数没有触发 timelimit_exit ,那么不执行处理
if (!timelimit_exit) return;
// 如果距离上次执行未够一定时间,那么不执行处理
if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return;
// 运行到这里,说明执行快速处理,记录当前时间
last_fast_cycle = start;
}
/*
* 一般情况下,函数只处理 REDIS_DBCRON_DBS_PER_CALL 个数据库,
* 除非:
*
* 1) 当前数据库的数量小于 REDIS_DBCRON_DBS_PER_CALL
* 2) 如果上次处理遇到了时间上限,那么这次需要对所有数据库进行扫描,
* 这可以避免过多的过期键占用空间
*/
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC percentage of CPU time
* per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
// 函数处理的微秒时间上限
// ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 默认为 25 ,也即是 25 % 的 CPU 时间
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
// 如果是运行在快速模式之下
// 那么最多只能运行 FAST_DURATION 微秒
// 默认值为 1000 (微秒)
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* in microseconds. */
// 遍历数据库
for (j = 0; j < dbs_per_call; j++) {
int expired;
// 指向要处理的数据库
redisDb *db = server.db+(current_db % server.dbnum);
// 为 DB 计数器加一,如果进入 do 循环之后因为超时而跳出
// 那么下次会直接从下个 DB 开始处理
current_db++;
/* Continue to expire if at the end of the cycle more than 25%
* of the keys were expired. */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
// 获取数据库中带过期时间的键的数量
// 如果该数量为 0 ,直接跳过这个数据库
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
// 获取数据库中键值对的数量
slots = dictSlots(db->expires);
// 当前时间
now = mstime();
// 这个数据库的使用率低于 1% ,扫描起来太费力了(大部分都会 MISS)
// 跳过,等待字典收缩程序运行
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones.
*
* 样本计数器
*/
// 已处理过期键计数器
expired = 0;
// 键的总 TTL 计数器
ttl_sum = 0;
// 总共处理的键计数器
ttl_samples = 0;
// 每次最多只能检查 LOOKUPS_PER_LOOP 个键
// 默认每个数据库检查的键数量
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;
// 开始遍历数据库
while (num--) {
dictEntry *de;
long long ttl;
// 从 expires 中随机取出一个带过期时间的键
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
// 计算 TTL
ttl = dictGetSignedIntegerVal(de)-now;
// 如果键已经过期,那么删除它,并将 expired 计数器增一
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl < 0) ttl = 0;
// 累积键的 TTL
ttl_sum += ttl;
// 累积处理键的个数
ttl_samples++;
}
// 为这个数据库更新平均 TTL 统计数据
if (ttl_samples) {
// 计算当前平均值
long long avg_ttl = ttl_sum/ttl_samples;
// 如果这是第一次设置数据库平均 TTL ,那么进行初始化
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
// 取数据库的上次平均 TTL 和今次平均 TTL 的平均值
db->avg_ttl = (db->avg_ttl+avg_ttl)/2;
}
// 更新遍历次数
iteration++;
// 每遍历 16 次执行一次
if ((iteration & 0xf) == 0 &&
(ustime()-start) > timelimit)
{
// 如果遍历次数正好是 16 的倍数
// 并且遍历的时间超过了 timelimit
// 那么断开 timelimit_exit
timelimit_exit = 1;
}
// 已经超时了,返回
if (timelimit_exit) return;
// 如果已删除的过期键占当前总数据库带过期时间的键数量的 25 %
// 那么不再遍历
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
}
redis客户端
因为redis可以和多个客户端进行连接,因此为了区分每个客户端,redis内部为每个连接客户端创建一个结构体redisClient,然后将多个结构体用链表连接在一起
typedef struct redisClient {
// 套接字描述符
int fd;
// 当前正在使用的数据库 使用select可以切换数据库,因为服务器刚开始创建了16个
redisDb *db;
// 当前正在使用的数据库的 id (号码)
int dictid;
// 客户端的名字
robj *name;
// 查询缓冲区
sds querybuf;
// 查询缓冲区长度峰值
size_t querybuf_peak;
// 参数数量
int argc;
// 参数对象数组
robj **argv;
// 记录被客户端执行的命令
struct redisCommand *cmd, *lastcmd;
// 请求的类型:内联命令还是多条命令
int reqtype;
// 剩余未读取的命令内容数量
int multibulklen;
// 命令内容的长度
long bulklen;
// 回复链表
list *reply;
// 回复链表中对象的总大小
unsigned long reply_bytes; /
// 已发送字节,处理 short write 用
int sentlen;
// 创建客户端的时间
time_t ctime;
// 客户端最后一次和服务器互动的时间
time_t lastinteraction;
// 客户端的输出缓冲区超过软性限制的时间
time_t obuf_soft_limit_reached_time;
// 客户端状态标志
int flags;
// 当 server.requirepass 不为 NULL 时
// 代表认证的状态
// 0 代表未认证, 1 代表已认证
int authenticated;
// 复制状态
int replstate;
// 用于保存主服务器传来的 RDB 文件的文件描述符
int repldbfd;
// 读取主服务器传来的 RDB 文件的偏移量
off_t repldboff;
// 主服务器传来的 RDB 文件的大小
off_t repldbsize;
sds replpreamble;
// 主服务器的复制偏移量
long long reploff;
// 从服务器最后一次发送 REPLCONF ACK 时的偏移量
long long repl_ack_off;
// 从服务器最后一次发送 REPLCONF ACK 的时间
long long repl_ack_time;
// 主服务器的 master run ID
// 保存在客户端,用于执行部分重同步
char replrunid[REDIS_RUN_ID_SIZE+1];
// 从服务器的监听端口号
int slave_listening_port;
// 事务状态
multiState mstate;
// 阻塞类型
int btype;
// 阻塞状态
blockingState bpop;
// 最后被写入的全局复制偏移量
long long woff;
// 被监视的键
list *watched_keys;
// 这个字典记录了客户端所有订阅的频道
// 键为频道名字,值为 NULL
// 也即是,一个频道的集合
dict *pubsub_channels;
// 链表,包含多个 pubsubPattern 结构
// 记录了所有订阅频道的客户端的信息
// 新 pubsubPattern 结构总是被添加到表尾
list *pubsub_patterns;
sds peerid;
// 回复偏移量
int bufpos;
// 回复缓冲区
char buf[REDIS_REPLY_CHUNK_BYTES];
} redisClient;
自己的网址:www.shicoder.top
欢迎加群聊天 452380935
本文由博客一文多发平台 OpenWrite 发布!


