

redis服务器
这一次主要讲下redis中服务器这个结构体相关代码,主要从是代码层面进行讲解
redis服务器
redis服务器结构体主要代码在redis.h/redisServer,下面给出该结构体源码,可以看到源码中对该结构体定义很长,这一节我们一点点分析,当然有些地方可能我也理解不到位hhh
// redis服务器实例
struct redisServer {
char *configfile; /* 配置文件的绝对路径 */
int hz; /* serverCron() 每秒调用的次数 */
redisDb *db; /* 数据库数组,里面存放的是该服务器所有的数据库 */
dict *commands; /* 命令表(受到 rename 配置选项的作用) */
dict *orig_commands; /* 命令表(无 rename 配置选项的作用) */
aeEventLoop *el; /* 事件状态 */
unsigned lruclock:REDIS_LRU_BITS; /* 最近一次使用时钟 */
int shutdown_asap; /* 关闭服务器的标识 */
int activerehashing; /* 在执行 serverCron() 时进行渐进式 rehash */
char *requirepass; /* 是否设置了密码 */
char *pidfile; /* PID 文件路径 */
int arch_bits; /* 架构类型32or64 */
int cronloops; /* serverCron() 函数的运行次数计数器 */
char runid[REDIS_RUN_ID_SIZE+1]; /* 本服务器的 RUN ID ID在每秒都会变化 */
int sentinel_mode; /* 服务器是否运行在 SENTINEL 模式 */
int port; /* TCP 监听端口 */
int tcp_backlog; /* TCP连接中已完成队列(完成三次握手之后)的长度 */
char *bindaddr[REDIS_BINDADDR_MAX]; /* 绑定地址 */
int bindaddr_count; /* bindaddr地址数量 */
char *unixsocket; /* UNIX socket 路径 */
mode_t unixsocketperm; /* UNIX socket permission */
int ipfd[REDIS_BINDADDR_MAX]; /* TCP套接字描述符 */
int ipfd_count; /* ipfd中使用的套接字数量 */
int sofd; /* Unix套接字描述符 */
int cfd[REDIS_BINDADDR_MAX];/* 集群总线监听套接字 */
int cfd_count; /* cfd使用到的套接字数量 */
list *clients; /* 链表,保存了所有客户端状态结构 */
list *clients_to_close; /* 链表,保存了所有待关闭的客户端 */
list *slaves, *monitors; /* 链表,保存了所有从服务器,以及所有监视器 */
redisClient *current_client; /* C服务器的当前客户端,仅用于崩溃报告 */
int clients_paused; /* 客服端是否被paused */
mstime_t clients_pause_end_time; /* 执行undo clients_paused的时间 */
char neterr[ANET_ERR_LEN]; /* anet.c网络错误缓冲区 */
dict *migrate_cached_sockets;/* MIGRATE缓冲套接字 */
int loading; /* 服务器是否正在被载入 */
off_t loading_total_bytes; /* 正在载入的数据的大小 */
off_t loading_loaded_bytes; /* 已载入数据的大小 */
time_t loading_start_time; /* 开始进行载入的时间 */
off_t loading_process_events_interval_bytes;
// 常用命令的快捷连接
struct redisCommand *delCommand, *multiCommand, *lpushCommand, *lpopCommand,
*rpopCommand;
time_t stat_starttime; /* 服务器启动时间 */
long long stat_numcommands; /* 已处理命令的数量 */
long long stat_numconnections; /* 服务器接到的连接请求数量 */
long long stat_expiredkeys; /* 已过期的键数量 */
long long stat_evictedkeys; /* 因为回收内存而被释放的过期键的数量 */
long long stat_keyspace_hits; /* 成功查找键的次数 */
long long stat_keyspace_misses; /* 查找键失败的次数 */
size_t stat_peak_memory; /* 已使用内存峰值 */
long long stat_fork_time; /* 最后一次执行 fork() 时消耗的时间 */
long long stat_rejected_conn; /* 服务器因为客户端数量过多而拒绝客户端连接的次数 */
long long stat_sync_full; /* 执行 full sync 的次数 */
long long stat_sync_partial_ok; /* PSYNC 成功执行的次数 */
long long stat_sync_partial_err;/* PSYNC 执行失败的次数 */
list *slowlog; /* 保存了所有慢查询日志的链表 */
long long slowlog_entry_id; /* SLOWLOG当前条目ID */
long long slowlog_log_slower_than; /* 服务器配置 slowlog-log-slower-than 选项的值(SLOWLOG时间限制) */
unsigned long slowlog_max_len; /* 服务器配置 slowlog-max-len 选项的值(SLOWLOG记录的最大项目数) */
size_t resident_set_size; /* serverCron()中rss采样次数. */
long long ops_sec_last_sample_time; /* 最后一次进行抽样的时间 */
long long ops_sec_last_sample_ops; /* 最后一次抽样时,服务器已执行命令的数量 */
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES]; /* 抽样结果 */
int ops_sec_idx; /* 数组索引,用于保存抽样结果,并在需要时回绕到 0 */
int verbosity; /* 日志等级 Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice */
int maxidletime; /* 客户端超时最大时间 */
int tcpkeepalive; /* 是否开启SO_KEEPALIVE选项 */
int active_expire_enabled; /* 测试时候可以禁用 */
size_t client_max_querybuf_len; /* 客户端查询缓冲区长度限制 */
int dbnum; /* 服务器初始化应该创建多少个服务器 config中databases 16可以设定该选项 */
int daemonize; /* 如果作为守护进程运行,则为True */
// 客户端输出缓冲区大小限制
// 数组的元素有 REDIS_CLIENT_LIMIT_NUM_CLASSES 个
// 每个代表一类客户端:普通、从服务器、pubsub,诸如此类
clientBufferLimitsConfig client_obuf_limits[REDIS_CLIENT_LIMIT_NUM_CLASSES];
int aof_state; /* AOF 状态(开启/关闭/可写) */
int aof_fsync; /* 所使用的 fsync 策略(每个写入/每秒/从不) */
char *aof_filename; /* AOF文件名字 */
int aof_no_fsync_on_rewrite; /* 如果重写是在prog中,请不要fsync */
int aof_rewrite_perc; /* Rewrite AOF if % growth is > M and... */
off_t aof_rewrite_base_size; /* 最后一次执行 BGREWRITEAOF 时, AOF 文件的大小 */
off_t aof_current_size; /* AOF 文件的当前字节大小 */
int aof_rewrite_scheduled; /* BGSAVE终止后重写 */
pid_t aof_child_pid; /* 负责进行 AOF 重写的子进程 ID */
list *aof_rewrite_buf_blocks; /* AOF 重写缓存链表,链接着多个缓存块 */
sds aof_buf; /* AOF 缓冲区 */
int aof_fd; /* 当前所选AOF文件的文件描述符 */
int aof_selected_db; /* 当前在AOF中选择的数据库 */
time_t aof_flush_postponed_start; /*推迟AOF flush的UNIX时间 */
time_t aof_last_fsync; /* 最后一直执行 fsync 的时间 */
time_t aof_rewrite_time_last; /* 最后一次AOF重写运行所用的时间 */
time_t aof_rewrite_time_start; /* 当前AOF重写开始时间 */
int aof_lastbgrewrite_status; /* 最后一次执行 BGREWRITEAOF 的结果REDIS_OK或REDIS_ERR */
unsigned long aof_delayed_fsync; /* 记录 AOF 的 write 操作被推迟了多少次 */
int aof_rewrite_incremental_fsync;/* 指示是否需要每写入一定量的数据,就主动执行一次 fsync() */
int aof_last_write_status; /* REDIS_OK or REDIS_ERR */
int aof_last_write_errno; /* 如果aof_last_write_status是ERR,则有效 */
long long dirty; /* 自从上次 SAVE 执行以来,数据库被修改的次数 */
long long dirty_before_bgsave; /* BGSAVE 执行前的数据库被修改次数 */
pid_t rdb_child_pid; /* 负责执行 BGSAVE 的子进程的 ID,没在执行 BGSAVE 时,设为 -1 */
struct saveparam *saveparams; /* 为RDB保存点数组 */
int saveparamslen; /* saveparams长度 */
char *rdb_filename; /* RDB文件的名称 */
int rdb_compression; /* 是否在RDB中使用压缩 */
int rdb_checksum; /* 是否使用RDB校验和 */
time_t lastsave; /* 最后一次完成 SAVE 的时间 */
time_t lastbgsave_try; /* 最后一次尝试执行 BGSAVE 的时间 */
time_t rdb_save_time_last; /* 最近一次 BGSAVE 执行耗费的时间 */
time_t rdb_save_time_start; /* 数据库最近一次开始执行 BGSAVE 的时间 */
int lastbgsave_status; /* 最后一次执行 SAVE 的状态REDIS_OK or REDIS_ERR */
int stop_writes_on_bgsave_err; /* 如果不能BGSAVE,不允许写入 */
/* Propagation of commands in AOF / replication */
redisOpArray also_propagate; /* Additional command to propagate. */
char *logfile; /* 日志文件的路径 */
int syslog_enabled; /* 是否启用了syslog */
char *syslog_ident; /* 指定syslog的标示符,如果上面的syslog-enabled no,则这个选项无效 */
int syslog_facility; /* 指定syslog facility,必须是USER或者LOCAL0到LOCAL7 */
int slaveseldb; /* Last SELECTed DB in replication output */
long long master_repl_offset; /* 全局复制偏移量(一个累计值) */
int repl_ping_slave_period; /* Master每N秒ping一次slave */
// backlog 本身
char *repl_backlog; /* Replication backlog for partial syncs */
long long repl_backlog_size; /* Backlog循环缓冲区大小 */
long long repl_backlog_histlen; /* backlog 中数据的长度 */
long long repl_backlog_idx; /* backlog 的当前索引 */
long long repl_backlog_off; /* backlog 中可以被还原的第一个字节的偏移量 */
time_t repl_backlog_time_limit; /* backlog 的过期时间 */
time_t repl_no_slaves_since; /* 距离上一次有从服务器的时间 */
int repl_min_slaves_to_write; /* 是否开启最小数量从服务器写入功能 */
int repl_min_slaves_max_lag; /* 定义最小数量从服务器的最大延迟值 */
int repl_good_slaves_count; /* 延迟良好的从服务器的数量 lag <= max_lag. */
char *masterauth; /* 主服务器的验证密码 */
char *masterhost; /* 主服务器的地址 */
int masterport; /* 主服务器的端口 */
int repl_timeout; /* 主机空闲N秒后超时 */
redisClient *master; /* 主服务器所对应的客户端 */
redisClient *cached_master; /* 被缓存的主服务器,PSYNC 时使用 */
int repl_syncio_timeout; /* Timeout for synchronous I/O calls */
int repl_state; /* 复制的状态(服务器是从服务器时使用) */
off_t repl_transfer_size; /* 在同步期间从主机读取的RDB的大小 */
off_t repl_transfer_read; /* 在同步期间从主设备读取的RDB字节数 */
// 最近一次执行 fsync 时的偏移量
// 用于 sync_file_range 函数
off_t repl_transfer_last_fsync_off; /* 上次fsync-ed时偏移 */
int repl_transfer_s; /* 主服务器的套接字 */
int repl_transfer_fd; /* 保存 RDB 文件的临时文件的描述符 */
char *repl_transfer_tmpfile; /* 保存 RDB 文件的临时文件名字 */
time_t repl_transfer_lastio; /* 最近一次读入 RDB 内容的时间 */
int repl_serve_stale_data; /* Serve stale data when link is down? */
int repl_slave_ro; /* 从服务器是否只读 */
time_t repl_down_since; /* 连接断开的时长 */
int repl_disable_tcp_nodelay; /* 是否要在 SYNC 之后关闭 NODELAY */
int slave_priority; /* 从服务器优先级 */
char repl_master_runid[REDIS_RUN_ID_SIZE+1]; /*本服务器(从服务器)当前主服务器的 RUN ID */
long long repl_master_initial_offset; /* Master PSYNC offset. */
/* ---------下面一些属性有些很难用到,对此我也没仔细看 */
/* Replication script cache. */
// 复制脚本缓存
// 字典
dict *repl_scriptcache_dict; /* SHA1 all slaves are aware of. */
// FIFO 队列
list *repl_scriptcache_fifo; /* First in, first out LRU eviction. */
// 缓存的大小
int repl_scriptcache_size; /* Max number of elements. */
/* Synchronous replication. */
list *clients_waiting_acks; /* Clients waiting in WAIT command. */
int get_ack_from_slaves; /* If true we send REPLCONF GETACK. */
int maxclients; /* 最大并发客户端数 */
unsigned long long maxmemory; /* 要使用的最大内存字节数 */
int maxmemory_policy; /* Policy for key eviction */
int maxmemory_samples; /* Pricision of random sampling */
unsigned int bpop_blocked_clients; /* 列表阻止的客户端数量 */
list *unblocked_clients; /* 在下一个循环之前解锁的客户端列表 */
list *ready_keys; /* List of readyList structures for BLPOP & co */
/* Sort parameters - qsort_r() is only available under BSD so we
* have to take this state global, in order to pass it to sortCompare() */
int sort_desc;
int sort_alpha;
int sort_bypattern;
int sort_store;
/* Zip structure config, see redis.conf for more information */
size_t hash_max_ziplist_entries;
size_t hash_max_ziplist_value;
size_t list_max_ziplist_entries;
size_t list_max_ziplist_value;
size_t set_max_intset_entries;
size_t zset_max_ziplist_entries;
size_t zset_max_ziplist_value;
size_t hll_sparse_max_bytes;
time_t unixtime; /* Unix time sampled every cron cycle. */
long long mstime; /* Like 'unixtime' but with milliseconds resolution. */
/* Pubsub */
// 字典,键为频道,值为链表
// 链表中保存了所有订阅某个频道的客户端
// 新客户端总是被添加到链表的表尾
dict *pubsub_channels; /* Map channels to list of subscribed clients */
// 这个链表记录了客户端订阅的所有模式的名字
list *pubsub_patterns; /* A list of pubsub_patterns */
int notify_keyspace_events; /* Events to propagate via Pub/Sub. This is an
xor of REDIS_NOTIFY... flags. */
/* Cluster */
int cluster_enabled; /* 群集是否已启用 */
mstime_t cluster_node_timeout; /* 集群节点超时时间. */
char *cluster_configfile; /* 集群自动生成的配置文件名 */
struct clusterState *cluster; /* 集群的状态*/
int cluster_migration_barrier; /* Cluster replicas migration barrier. */
/* Scripting */
// Lua 环境
lua_State *lua; /* The Lua interpreter. We use just one for all clients */
// 复制执行 Lua 脚本中的 Redis 命令的伪客户端
redisClient *lua_client; /* The "fake client" to query Redis from Lua */
// 当前正在执行 EVAL 命令的客户端,如果没有就是 NULL
redisClient *lua_caller; /* The client running EVAL right now, or NULL */
// 一个字典,值为 Lua 脚本,键为脚本的 SHA1 校验和
dict *lua_scripts; /* A dictionary of SHA1 -> Lua scripts */
// Lua 脚本的执行时限
mstime_t lua_time_limit; /* Script timeout in milliseconds */
// 脚本开始执行的时间
mstime_t lua_time_start; /* Start time of script, milliseconds time */
// 脚本是否执行过写命令
int lua_write_dirty; /* True if a write command was called during the
execution of the current script. */
// 脚本是否执行过带有随机性质的命令
int lua_random_dirty; /* True if a random command was called during the
execution of the current script. */
// 脚本是否超时
int lua_timedout; /* True if we reached the time limit for script
execution. */
// 是否要杀死脚本
int lua_kill; /* Kill the script if true. */
/* Assert & bug reporting */
char *assert_failed;
char *assert_file;
int assert_line;
int bug_report_start; /* True if bug report header was already logged. */
int watchdog_period; /* Software watchdog period in ms. 0 = off */
};
下面重点讲下redis服务器启动的流程,主要包括以下几个步骤,不懂的同学可以看下redis.c/main函数,就可以大致了解其过程
- 检查服务器是否以
Sentinel模式启动 - 初始化全局服务器配置
initServerConfig() - 如果是
Sentinel模式,则初始化相关配置initSentinelConfig、initSentinel - 加载配置文件
loadServerConfig() - 将服务器进程设置为守护进程
daemonize - 初始化服务器
initServer - 如果服务器进程为守护进程,则创建PID文件
createPidFile - 为服务器进程设置名字
redisSetProcTitle - 打印logo
redisAsciiArt - 加载数据库
loadDataFromDisk:- AOF 持久化已打开,则使用
loadAppendOnlyFile(), - 否则使用加载RDB文件
rdbLoad()
- AOF 持久化已打开,则使用
- 运行事件处理器,一直到服务器关闭为止
aeMain
下面对上面几个函数依次进行讲解
Sentinel模式
Sentinel模式就是哨兵模式,下面给出该模式的一个例子
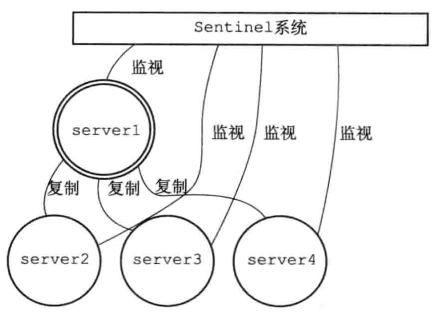
其中server1是主服务器,其余server2,3,4为从服务器。在生产环境中,不免会有意外原因导致redis服务器挂掉,如果此时挂掉的是一个master节点,主节点宕机,主从复制将不能继续进行,写数据将会阻塞,而哨兵的存在主要是为了切换掉宕机的master,然后从master下面的slave节点中选举一个作为新的master,并且把旧的master的slave全部转移到新的master上面,继续原有的主从复制。 哨兵本身是一个独立的进程,本身也是有单点问题的,所以哨兵也有自身的集群,用来保证哨兵本身的容错机制。
可以将redis中sentinel想成一个特殊的redis服务器,但是他不会像redis普通服务器那样去加载rdb或者aof文件,在initSentinel函数中,会创建一个sentinel结构体 sentinelState,代码如下
/* Sentinel 的状态结构 */
struct sentinelState {
// 当前纪元
uint64_t current_epoch;
// 保存了所有被这个 sentinel 监视的主服务器
// 字典的键是主服务器的名字
// 字典的值则是一个指向 sentinelRedisInstance 结构的指针
dict *masters;
// 是否进入了 TILT 模式?
int tilt;
// 目前正在执行的脚本的数量
int running_scripts;
// 进入 TILT 模式的时间
mstime_t tilt_start_time;
// 最后一次执行时间处理器的时间
mstime_t previous_time;
// 一个 FIFO 队列,包含了所有需要执行的用户脚本
list *scripts_queue;
} sentinel;
// 以 Sentinel 模式初始化服务器
void initSentinel(void) {
int j;
// 清空 Redis 服务器的命令表(该表用于普通模式)
dictEmpty(server.commands,NULL);
// 将 SENTINEL 模式所用的命令添加进命令表
for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) {
int retval;
struct redisCommand *cmd = sentinelcmds+j;
retval = dictAdd(server.commands, sdsnew(cmd->name), cmd);
redisAssert(retval == DICT_OK);
}
/* 初始化 Sentinel 的状态 */
// 初始化纪元
sentinel.current_epoch = 0;
// 初始化保存主服务器信息的字典
sentinel.masters = dictCreate(&instancesDictType,NULL);
// 初始化 TILT 模式的相关选项
sentinel.tilt = 0;
sentinel.tilt_start_time = 0;
sentinel.previous_time = mstime();
// 初始化脚本相关选项
sentinel.running_scripts = 0;
sentinel.scripts_queue = listCreate();
}
其中有一个master字典,这里面记录了记录了所有被 Sentinel 监视的主服务器的相关信息, 其中:
- 字典的键是被监视主服务器的名字。
- 而字典的值则是被监视主服务器对应的
sentinel.c/sentinelRedisInstance结构。
每个 sentinelRedisInstance 结构代表一个被 Sentinel 监视的 Redis 服务器实例(instance), 这个实例可以是主服务器、从服务器、或者另外一个 Sentinel 。下面给出这个结构体的代码
// Sentinel 会为每个被监视的 Redis 实例创建相应的 sentinelRedisInstance 实例
// (被监视的实例可以是主服务器、从服务器、或者其他 Sentinel )
typedef struct sentinelRedisInstance {
// 标识值,记录了实例的类型,以及该实例的当前状态
// 当为SRI_MASTER为主服务器,当为SRI_SLAVE为从服务器,当为SRI_SENTINEL为sentinel服务器
int flags;
// 实例的名字
// 主服务器的名字由用户在配置文件中设置
// 从服务器以及 Sentinel 的名字由 Sentinel 自动设置
// 格式为 ip:port ,例如 "127.0.0.1:26379"
char *name;
// 实例的运行 ID
char *runid;
// 配置纪元,用于实现故障转移
uint64_t config_epoch;
// 实例的地址
sentinelAddr *addr;
// 用于发送命令的异步连接
redisAsyncContext *cc;
// 用于执行 SUBSCRIBE 命令、接收频道信息的异步连接
// 仅在实例为主服务器时使用
redisAsyncContext *pc;
// 已发送但尚未回复的命令数量
int pending_commands;
// cc 连接的创建时间
mstime_t cc_conn_time;
// pc 连接的创建时间
mstime_t pc_conn_time;
// 最后一次从这个实例接收信息的时间
mstime_t pc_last_activity;
// 实例最后一次返回正确的 PING 命令回复的时间
mstime_t last_avail_time;
// 实例最后一次发送 PING 命令的时间
mstime_t last_ping_time;
// 实例最后一次返回 PING 命令的时间,无论内容正确与否
mstime_t last_pong_time;
// 最后一次向频道发送问候信息的时间
// 只在当前实例为 sentinel 时使用
mstime_t last_pub_time;
// 最后一次接收到这个 sentinel 发来的问候信息的时间
// 只在当前实例为 sentinel 时使用
mstime_t last_hello_time;
// 最后一次回复 SENTINEL is-master-down-by-addr 命令的时间
// 只在当前实例为 sentinel 时使用
mstime_t last_master_down_reply_time;
// 实例被判断为 SDOWN 状态的时间
mstime_t s_down_since_time;
// 实例被判断为 ODOWN 状态的时间
mstime_t o_down_since_time;
// SENTINEL down-after-milliseconds 选项所设定的值
// 实例无响应多少毫秒之后才会被判断为主观下线(subjectively down)
mstime_t down_after_period;
// 从实例获取 INFO 命令的回复的时间
mstime_t info_refresh;
// 实例的角色
int role_reported;
// 角色的更新时间
mstime_t role_reported_time;
// 最后一次从服务器的主服务器地址变更的时间
mstime_t slave_conf_change_time;
/* 主服务器实例特有的属性 */
// 其他同样监控这个主服务器的所有 sentinel
dict *sentinels;
// 如果这个实例代表的是一个主服务器
// 那么这个字典保存着主服务器属下的从服务器
// 字典的键是从服务器的名字,字典的值是从服务器对应的 sentinelRedisInstance 结构
dict *slaves;
// SENTINEL monitor <master-name> <IP> <port> <quorum> 选项中的 quorum 参数
// 判断这个实例为客观下线(objectively down)所需的支持投票数量
int quorum;
// SENTINEL parallel-syncs <master-name> <number> 选项的值
// 在执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
int parallel_syncs;
// 连接主服务器和从服务器所需的密码
char *auth_pass;
/* 从服务器实例特有的属性*/
// 主从服务器连接断开的时间
mstime_t master_link_down_time;
// 从服务器优先级
int slave_priority;
// 执行故障转移操作时,从服务器发送 SLAVEOF <new-master> 命令的时间
mstime_t slave_reconf_sent_time;
// 主服务器的实例(在本实例为从服务器时使用)
struct sentinelRedisInstance *master;
// INFO 命令的回复中记录的主服务器 IP
char *slave_master_host;
// INFO 命令的回复中记录的主服务器端口号
int slave_master_port;
// INFO 命令的回复中记录的主从服务器连接状态
int slave_master_link_status;
// 从服务器的复制偏移量
unsigned long long slave_repl_offset;
/* 故障转移相关属性*/
// 如果这是一个主服务器实例,那么 leader 将是负责进行故障转移的 Sentinel 的运行 ID 。
// 如果这是一个 Sentinel 实例,那么 leader 就是被选举出来的领头 Sentinel 。
// 这个域只在 Sentinel 实例的 flags 属性的 SRI_MASTER_DOWN 标志处于打开状态时才有效。
char *leader;
// 领头的纪元
uint64_t leader_epoch;
// 当前执行中的故障转移的纪元
uint64_t failover_epoch;
// 故障转移操作的当前状态
int failover_state;
// 状态改变的时间
mstime_t failover_state_change_time;
// 最后一次进行故障迁移的时间
mstime_t failover_start_time;
// SENTINEL failover-timeout <master-name> <ms> 选项的值
// 刷新故障迁移状态的最大时限
mstime_t failover_timeout;
mstime_t failover_delay_logged;
// 指向被提升为新主服务器的从服务器的指针
struct sentinelRedisInstance *promoted_slave;
// 一个文件路径,保存着 WARNING 级别的事件发生时执行的,
// 用于通知管理员的脚本的地址
char *notification_script;
// 一个文件路径,保存着故障转移执行之前、之后、或者被中止时,
// 需要执行的脚本的地址
char *client_reconfig_script;
} sentinelRedisInstance;
假如此时启动sentinel时候,配置文件如下
#####################
# master1 configure #
#####################
sentinel monitor master1 127.0.0.1 6379 2
sentinel down-after-milliseconds master1 30000
sentinel parallel-syncs master1 1
sentinel failover-timeout master1 900000
#####################
# master2 configure #
#####################
sentinel monitor master2 127.0.0.1 12345 5
sentinel down-after-milliseconds master2 50000
sentinel parallel-syncs master2 5
sentinel failover-timeout master2 450000
则会为2个服务器创建如下结构体
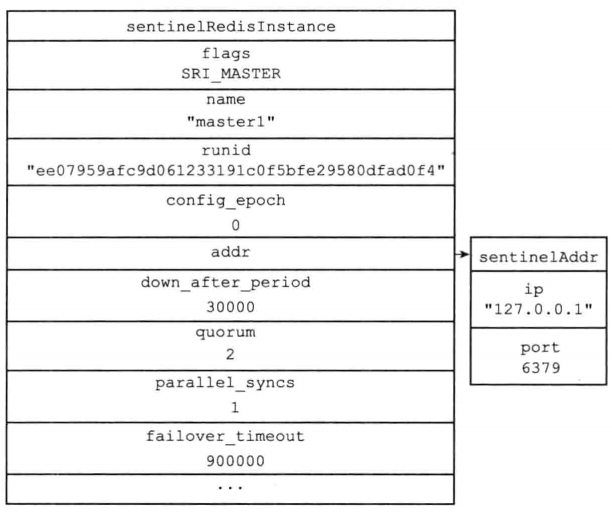
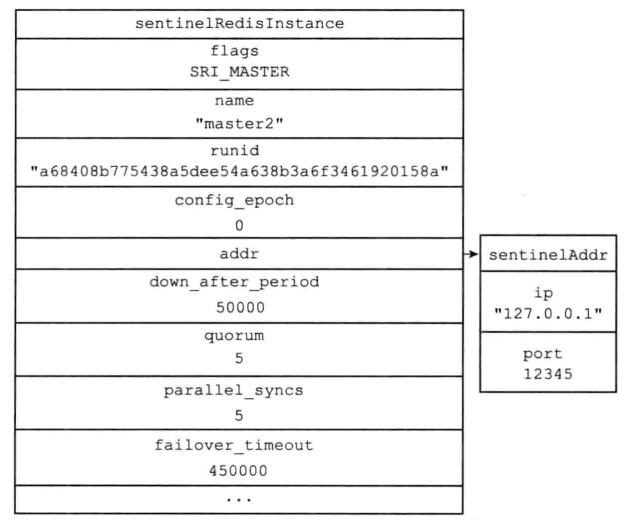
sentinel结构体中maste字典内容如下

当一个redis服务器以sentinel模式启动,则它会自动去替换一些普通模式服务器的代码,比如普通redis服务器使用redis.h/REDIS_SERVERPORT作为端口,但是sentinel模式下会以sentinel.c/REDIS_SENTINEL_PORT作为端口,同时普通redis服务器的支持的命令在redis.c/redisCommandTable中,但是sentinel模式下支持的命令在sentinel.c/sentinelcmds,其中代码较少,下面给出代码
// 服务器在 sentinel 模式下可执行的命令
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"publish",sentinelPublishCommand,3,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"",0,NULL,0,0,0,0,0}
};
sentinel主要就是为了应用于主服务器下线导致集群不可用情况,因此最重要的就是如何检测和如何防范,下面通过主观下线和客观下线两种方式进行说明
- 主观下线
默认情况下,每个sentinel会每秒钟向其他所有主服务器、从服务器、sentinels发送ping消息,返回结果分为有效返回(+PONG、-LOADING、-MASTERDOWN)三者之一或无效返回(上述三种其他回复或者指定时间内没有回复),若出现无效返回情况,则会将sentinelRedisInstance属性中的flag字段打开SRI_S_DOWN标志
- 客观下线
当一个sentinel对一台服务器设置为主观下线后,还需要判断是否客观下线,它会向其他监视该服务器的sentinels进行询问,当接收到足够数量(设置的quorum参数)的sentinels说该服务器也下线,则表明该服务器客观下线。客观下线会打开SRI_O_DOWN标志
当一个主服务器被判定为客观下线后,监视这个下线服务器的全部sentinels会进行协商,选举出一个lead sentinel,这个lead sentinel会对下线服务器进行故障转移,包括三个步骤
1、在已下线主服务器的从服务器中选一个主服务器,然后向其发送SLAVEOF no one命令,设置为主服务器
2、让已下线主服务器下面的从服务器用刚刚选举的主服务器作为主服务器
3、将已下线的主服务器认刚刚选举的主服务器作为自己的主服务器,当这个下线服务器再次上线时,就会真的设置为自己的主服务器
初始化全局服务器配置
redis.c/initServerConfig()
void initServerConfig() {
int j;
// 设置服务器的运行 ID
getRandomHexChars(server.runid,REDIS_RUN_ID_SIZE);
// 设置默认配置文件路径
server.configfile = NULL;
// 设置默认服务器频率
server.hz = REDIS_DEFAULT_HZ;
// 为运行 ID 加上结尾字符
server.runid[REDIS_RUN_ID_SIZE] = '\0';
// 设置服务器的运行架构
server.arch_bits = (sizeof(long) == 8) ? 64 : 32;
// 设置默认服务器端口号
server.port = REDIS_SERVERPORT;
server.tcp_backlog = REDIS_TCP_BACKLOG;
server.bindaddr_count = 0;
server.unixsocket = NULL;
server.unixsocketperm = REDIS_DEFAULT_UNIX_SOCKET_PERM;
server.ipfd_count = 0;
server.sofd = -1;
server.dbnum = REDIS_DEFAULT_DBNUM;
server.verbosity = REDIS_DEFAULT_VERBOSITY;
server.maxidletime = REDIS_MAXIDLETIME;
server.tcpkeepalive = REDIS_DEFAULT_TCP_KEEPALIVE;
server.active_expire_enabled = 1;
server.client_max_querybuf_len = REDIS_MAX_QUERYBUF_LEN;
server.saveparams = NULL;
server.loading = 0;
server.logfile = zstrdup(REDIS_DEFAULT_LOGFILE);
server.syslog_enabled = REDIS_DEFAULT_SYSLOG_ENABLED;
server.syslog_ident = zstrdup(REDIS_DEFAULT_SYSLOG_IDENT);
server.syslog_facility = LOG_LOCAL0;
server.daemonize = REDIS_DEFAULT_DAEMONIZE;
server.aof_state = REDIS_AOF_OFF;
server.aof_fsync = REDIS_DEFAULT_AOF_FSYNC;
server.aof_no_fsync_on_rewrite = REDIS_DEFAULT_AOF_NO_FSYNC_ON_REWRITE;
server.aof_rewrite_perc = REDIS_AOF_REWRITE_PERC;
server.aof_rewrite_min_size = REDIS_AOF_REWRITE_MIN_SIZE;
server.aof_rewrite_base_size = 0;
server.aof_rewrite_scheduled = 0;
server.aof_last_fsync = time(NULL);
server.aof_rewrite_time_last = -1;
server.aof_rewrite_time_start = -1;
server.aof_lastbgrewrite_status = REDIS_OK;
server.aof_delayed_fsync = 0;
server.aof_fd = -1;
server.aof_selected_db = -1; /* 保证不选中任意数据库 */
server.aof_flush_postponed_start = 0;
server.aof_rewrite_incremental_fsync = REDIS_DEFAULT_AOF_REWRITE_INCREMENTAL_FSYNC;
server.pidfile = zstrdup(REDIS_DEFAULT_PID_FILE);
server.rdb_filename = zstrdup(REDIS_DEFAULT_RDB_FILENAME);
server.aof_filename = zstrdup(REDIS_DEFAULT_AOF_FILENAME);
server.requirepass = NULL;
server.rdb_compression = REDIS_DEFAULT_RDB_COMPRESSION;
server.rdb_checksum = REDIS_DEFAULT_RDB_CHECKSUM;
server.stop_writes_on_bgsave_err = REDIS_DEFAULT_STOP_WRITES_ON_BGSAVE_ERROR;
server.activerehashing = REDIS_DEFAULT_ACTIVE_REHASHING;
server.notify_keyspace_events = 0;
server.maxclients = REDIS_MAX_CLIENTS;
server.bpop_blocked_clients = 0;
server.maxmemory = REDIS_DEFAULT_MAXMEMORY;
server.maxmemory_policy = REDIS_DEFAULT_MAXMEMORY_POLICY;
server.maxmemory_samples = REDIS_DEFAULT_MAXMEMORY_SAMPLES;
server.hash_max_ziplist_entries = REDIS_HASH_MAX_ZIPLIST_ENTRIES;
server.hash_max_ziplist_value = REDIS_HASH_MAX_ZIPLIST_VALUE;
server.list_max_ziplist_entries = REDIS_LIST_MAX_ZIPLIST_ENTRIES;
server.list_max_ziplist_value = REDIS_LIST_MAX_ZIPLIST_VALUE;
server.set_max_intset_entries = REDIS_SET_MAX_INTSET_ENTRIES;
server.zset_max_ziplist_entries = REDIS_ZSET_MAX_ZIPLIST_ENTRIES;
server.zset_max_ziplist_value = REDIS_ZSET_MAX_ZIPLIST_VALUE;
server.hll_sparse_max_bytes = REDIS_DEFAULT_HLL_SPARSE_MAX_BYTES;
server.shutdown_asap = 0;
server.repl_ping_slave_period = REDIS_REPL_PING_SLAVE_PERIOD;
server.repl_timeout = REDIS_REPL_TIMEOUT;
server.repl_min_slaves_to_write = REDIS_DEFAULT_MIN_SLAVES_TO_WRITE;
server.repl_min_slaves_max_lag = REDIS_DEFAULT_MIN_SLAVES_MAX_LAG;
server.cluster_enabled = 0;
server.cluster_node_timeout = REDIS_CLUSTER_DEFAULT_NODE_TIMEOUT;
server.cluster_migration_barrier = REDIS_CLUSTER_DEFAULT_MIGRATION_BARRIER;
server.cluster_configfile = zstrdup(REDIS_DEFAULT_CLUSTER_CONFIG_FILE);
server.lua_caller = NULL;
server.lua_time_limit = REDIS_LUA_TIME_LIMIT;
server.lua_client = NULL;
server.lua_timedout = 0;
server.migrate_cached_sockets = dictCreate(&migrateCacheDictType,NULL);
server.loading_process_events_interval_bytes = (1024*1024*2);
// 初始化 LRU 时间
server.lruclock = getLRUClock();
// 初始化并设置保存条件
resetServerSaveParams();
appendServerSaveParams(60*60,1); /* save after 1 hour and 1 change */
appendServerSaveParams(300,100); /* save after 5 minutes and 100 changes */
appendServerSaveParams(60,10000); /* save after 1 minute and 10000 changes */
// 初始化和复制相关的状态
server.masterauth = NULL;
server.masterhost = NULL;
server.masterport = 6379;
server.master = NULL;
server.cached_master = NULL;
server.repl_master_initial_offset = -1;
server.repl_state = REDIS_REPL_NONE;
server.repl_syncio_timeout = REDIS_REPL_SYNCIO_TIMEOUT;
server.repl_serve_stale_data = REDIS_DEFAULT_SLAVE_SERVE_STALE_DATA;
server.repl_slave_ro = REDIS_DEFAULT_SLAVE_READ_ONLY;
server.repl_down_since = 0; /* Never connected, repl is down since EVER. */
server.repl_disable_tcp_nodelay = REDIS_DEFAULT_REPL_DISABLE_TCP_NODELAY;
server.slave_priority = REDIS_DEFAULT_SLAVE_PRIORITY;
server.master_repl_offset = 0;
// 初始化 PSYNC 命令所使用的 backlog
server.repl_backlog = NULL;
server.repl_backlog_size = REDIS_DEFAULT_REPL_BACKLOG_SIZE;
server.repl_backlog_histlen = 0;
server.repl_backlog_idx = 0;
server.repl_backlog_off = 0;
server.repl_backlog_time_limit = REDIS_DEFAULT_REPL_BACKLOG_TIME_LIMIT;
server.repl_no_slaves_since = time(NULL);
// 设置客户端的输出缓冲区限制
for (j = 0; j < REDIS_CLIENT_LIMIT_NUM_CLASSES; j++)
server.client_obuf_limits[j] = clientBufferLimitsDefaults[j];
// 初始化浮点常量
R_Zero = 0.0;
R_PosInf = 1.0/R_Zero;
R_NegInf = -1.0/R_Zero;
R_Nan = R_Zero/R_Zero;
// 初始化命令表
// 在这里初始化是因为接下来读取 .conf 文件时可能会用到这些命令
server.commands = dictCreate(&commandTableDictType,NULL);
server.orig_commands = dictCreate(&commandTableDictType,NULL);
populateCommandTable();
server.delCommand = lookupCommandByCString("del");
server.multiCommand = lookupCommandByCString("multi");
server.lpushCommand = lookupCommandByCString("lpush");
server.lpopCommand = lookupCommandByCString("lpop");
server.rpopCommand = lookupCommandByCString("rpop");
// 初始化慢查询日志
server.slowlog_log_slower_than = REDIS_SLOWLOG_LOG_SLOWER_THAN;
server.slowlog_max_len = REDIS_SLOWLOG_MAX_LEN;
// 初始化调试项
server.assert_failed = "<no assertion failed>";
server.assert_file = "<no file>";
server.assert_line = 0;
server.bug_report_start = 0;
server.watchdog_period = 0;
}
主要包括以下几个方面
- 网络监听相关,如绑定地址,TCP端口等
- 虚拟内存相关,如swap文件、page大小等
- 保存机制,多长时间内有多少次更新才进行保存
- 复制相关,如是否是slave,master地址、端口
- Hash相关设置
- 初始化命令表
加载配置文件
上面加载的可以想象成是一个默认配置文件,若 初始化时候,指定了配置文件,则会将其中一些字段进行修改config.c/loadServerConfig
void loadServerConfig(char *filename, char *options) {
sds config = sdsempty();
char buf[REDIS_CONFIGLINE_MAX+1];
// 载入文件内容
if (filename) {
FILE *fp;
if (filename[0] == '-' && filename[1] == '\0') {
fp = stdin;
} else {
if ((fp = fopen(filename,"r")) == NULL) {
redisLog(REDIS_WARNING,
"Fatal error, can't open config file '%s'", filename);
exit(1);
}
}
while(fgets(buf,REDIS_CONFIGLINE_MAX+1,fp) != NULL)
config = sdscat(config,buf);
if (fp != stdin) fclose(fp);
}
// 追加 options 字符串到内容的末尾
if (options) {
config = sdscat(config,"\n");
config = sdscat(config,options);
}
// 根据字符串内容,设置服务器配置
loadServerConfigFromString(config);
sdsfree(config);
}
设置为守护进程
代码如下
void daemonize(void) {
int fd;
if (fork() != 0) exit(0); /* 父进程退出 */
setsid(); /* 创建新会话 */
/* 将输出定位到/dev/null */
if ((fd = open("/dev/null", O_RDWR, 0)) != -1) {
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
if (fd > STDERR_FILENO) close(fd);
}
}
初始化服务器initServer
代码如下
void initServer() {
int j;
// 设置信号处理函数
// 因为是守护进程,所以没有控制终端,屏蔽SIGHUP
signal(SIGHUP, SIG_IGN);
// SIGPIPE是写管道发现读进程终止时产生的信号,redis是服务器,会遇到各种client,所以需要忽略
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
// 设置 syslog
if (server.syslog_enabled) {
openlog(server.syslog_ident, LOG_PID | LOG_NDELAY | LOG_NOWAIT,
server.syslog_facility);
}
// 初始化并创建数据结构
server.current_client = NULL;
server.clients = listCreate();
server.clients_to_close = listCreate();
server.slaves = listCreate();
server.monitors = listCreate();
server.slaveseldb = -1;
server.unblocked_clients = listCreate();
server.ready_keys = listCreate();
server.clients_waiting_acks = listCreate();
server.get_ack_from_slaves = 0;
server.clients_paused = 0;
// 创建共享对象
createSharedObjects();
adjustOpenFilesLimit();
server.el = aeCreateEventLoop(server.maxclients+REDIS_EVENTLOOP_FDSET_INCR);
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
// 打开 TCP 监听端口,用于等待客户端的命令请求
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == REDIS_ERR)
exit(1);
// 打开 UNIX 本地端口
if (server.unixsocket != NULL) {
unlink(server.unixsocket); /* don't care if this fails */
server.sofd = anetUnixServer(server.neterr,server.unixsocket,
server.unixsocketperm, server.tcp_backlog);
if (server.sofd == ANET_ERR) {
redisLog(REDIS_WARNING, "Opening socket: %s", server.neterr);
exit(1);
}
anetNonBlock(NULL,server.sofd);
}
/* Abort if there are no listening sockets at all. */
if (server.ipfd_count == 0 && server.sofd < 0) {
redisLog(REDIS_WARNING, "Configured to not listen anywhere, exiting.");
exit(1);
}
// 创建并初始化数据库结构
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
server.db[j].ready_keys = dictCreate(&setDictType,NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
server.db[j].eviction_pool = evictionPoolAlloc();
server.db[j].id = j;
server.db[j].avg_ttl = 0;
}
// 创建 PUBSUB 相关结构
server.pubsub_channels = dictCreate(&keylistDictType,NULL);
server.pubsub_patterns = listCreate();
listSetFreeMethod(server.pubsub_patterns,freePubsubPattern);
listSetMatchMethod(server.pubsub_patterns,listMatchPubsubPattern);
server.cronloops = 0;
server.rdb_child_pid = -1;
server.aof_child_pid = -1;
aofRewriteBufferReset();
server.aof_buf = sdsempty();
server.lastsave = time(NULL); /* At startup we consider the DB saved. */
server.lastbgsave_try = 0; /* At startup we never tried to BGSAVE. */
server.rdb_save_time_last = -1;
server.rdb_save_time_start = -1;
server.dirty = 0;
resetServerStats();
/* A few stats we don't want to reset: server startup time, and peak mem. */
server.stat_starttime = time(NULL);
server.stat_peak_memory = 0;
server.resident_set_size = 0;
server.lastbgsave_status = REDIS_OK;
server.aof_last_write_status = REDIS_OK;
server.aof_last_write_errno = 0;
server.repl_good_slaves_count = 0;
updateCachedTime();
/* Create the serverCron() time event, that's our main way to process
* background operations. */
// 为 serverCron() 创建时间事件
if(aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
redisPanic("Can't create the serverCron time event.");
exit(1);
}
/* Create an event handler for accepting new connections in TCP and Unix
* domain sockets. */
// 为 TCP 连接关联连接应答(accept)处理器
// 用于接受并应答客户端的 connect() 调用
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
redisPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
// 为本地套接字关联应答处理器
if (server.sofd > 0 && aeCreateFileEvent(server.el,server.sofd,AE_READABLE,
acceptUnixHandler,NULL) == AE_ERR) redisPanic("Unrecoverable error creating server.sofd file event.");
/* Open the AOF file if needed. */
// 如果 AOF 持久化功能已经打开,那么打开或创建一个 AOF 文件
if (server.aof_state == REDIS_AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT,0644);
if (server.aof_fd == -1) {
redisLog(REDIS_WARNING, "Can't open the append-only file: %s",
strerror(errno));
exit(1);
}
}
// 对于 32 位实例来说,默认将最大可用内存限制在 3 GB
if (server.arch_bits == 32 && server.maxmemory == 0) {
redisLog(REDIS_WARNING,"Warning: 32 bit instance detected but no memory limit set. Setting 3 GB maxmemory limit with 'noeviction' policy now.");
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = REDIS_MAXMEMORY_NO_EVICTION;
}
// 如果服务器以 cluster 模式打开,那么初始化 cluster
if (server.cluster_enabled) clusterInit();
// 初始化复制功能有关的脚本缓存
replicationScriptCacheInit();
// 初始化脚本系统
scriptingInit();
// 初始化慢查询功能
slowlogInit();
// 初始化 BIO 系统
bioInit();
}
上面大多数注释已经对代码进行讲解,下面对slowlogInit进行单独讲解
/*
* 初始化服务器慢查询功能。
*
* 这个函数只应该在服务器启动时执行一次。
*/
void slowlogInit(void) {
// 保存日志的链表,FIFO 顺序
server.slowlog = listCreate();
// 日志数量计数器
server.slowlog_entry_id = 0;
// 日志链表的释构函数
listSetFreeMethod(server.slowlog,slowlogFreeEntry);
}
/*
* 慢查询日志
*/
typedef struct slowlogEntry {
// 命令与命令参数
robj **argv;
// 命令与命令参数的数量
int argc;
// 唯一标识符
long long id;
// 执行命令消耗的时间,以微秒为单位
// 注释里说的 nanoseconds 是错误的
long long duration;
// 命令执行时的时间,格式为 UNIX 时间戳
time_t time;
} slowlogEntry;
其中还有一个函数bioInit,redis的BIO系统在redis3.0版本主要做两件事情:AOF持久化和关闭文件,可以将BIO系统想象成下面:创建一个队列,然后创建一些线程,来了一个任务就往队列里面添加任务,线程去任务队列里面取任务出来执行
因为在redis3.0中只需要做两件事情,所以任务的结构体代码如下
/*
* 表示后台任务的数据结构
*
* 这个结构只由 API 使用,不会被暴露给外部。
*/
struct bio_job {
// 任务创建时的时间
time_t time;
/*
* 任务的参数。参数多于三个时,可以传递数组或者结构 arg1一般是文件描述符
*/
void *arg1, *arg2, *arg3;
};
- 任务初始化
首先是相关静态变量的初始化
#define REDIS_BIO_NUM_OPS 2 // 2个任务
// 工作线程,斥互和条件变量
static pthread_t bio_threads[REDIS_BIO_NUM_OPS];
static pthread_mutex_t bio_mutex[REDIS_BIO_NUM_OPS];
static pthread_cond_t bio_condvar[REDIS_BIO_NUM_OPS];
// 存放工作的队列
static list *bio_jobs[REDIS_BIO_NUM_OPS];
// 初始化变量
for (j = 0; j < REDIS_BIO_NUM_OPS; j++) {
pthread_mutex_init(&bio_mutex[j],NULL);
pthread_cond_init(&bio_condvar[j],NULL);
bio_jobs[j] = listCreate();
bio_pending[j] = 0;
}
// 创建线程
for (j = 0; j < REDIS_BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
// 这里的函数参数是arg = j,也就是每个线程传入一个编号j,0代表关闭文件,1代表aof初始化
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
redisLog(REDIS_WARNING,"Fatal: Can't initialize Background Jobs.");
exit(1);
}
bio_threads[j] = thread;
}
// bioProcessBackgroundJobs函数就是后台执行任务的函数
void *bioProcessBackgroundJobs(void *arg) {
...
if (type == REDIS_BIO_CLOSE_FILE) {
close((long)job->arg1);
} else if (type == REDIS_BIO_AOF_FSYNC) {
aof_fsync((long)job->arg1);
} else {
redisPanic("Wrong job type in bioProcessBackgroundJobs().");
}
...
}
事件处理器循环aeMain
这个循环主要就是做两件事情,beforeSleep和aeProcessEvents
// 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
// 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
/*
* 设置处理事件前需要被执行的函数
*/
void aeSetBeforeSleepProc(aeEventLoop *eventLoop, aeBeforeSleepProc *beforesleep) {
eventLoop->beforesleep = beforesleep;
}
/*
* 事件处理器的主循环
*/
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 如果有需要在事件处理前执行的函数,那么运行它
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 开始处理事件 其实就是一个事件调度函数,包括处理时间事件和文件事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
/*
* 删除事件处理器
*/
void aeDeleteEventLoop(aeEventLoop *eventLoop) {
aeApiFree(eventLoop);
zfree(eventLoop->events);
zfree(eventLoop->fired);
zfree(eventLoop);
}
下面单独对这两个函数进行讲解
beforeSleep
首先先看代码
// 每次处理事件之前执行
void beforeSleep(struct aeEventLoop *eventLoop) {
REDIS_NOTUSED(eventLoop);
// 执行一次快速的主动过期检查
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
/* 如果在之前的事件循环迭代中至少有一个客户端阻塞,则向所有slave发送ACK请求 */
if (server.get_ack_from_slaves) {
robj *argv[3];
argv[0] = createStringObject("REPLCONF",8);
argv[1] = createStringObject("GETACK",6);
argv[2] = createStringObject("*",1); /* Not used argument. */
replicationFeedSlaves(server.slaves, server.slaveseldb, argv, 3);
decrRefCount(argv[0]);
decrRefCount(argv[1]);
decrRefCount(argv[2]);
server.get_ack_from_slaves = 0;
}
/* 解除阻塞等待同步复制的所有客户端 */
if (listLength(server.clients_waiting_acks))
processClientsWaitingReplicas();
/* 尝试为刚刚解除阻塞的客户端处理挂起的命令 */
if (listLength(server.unblocked_clients))
processUnblockedClients();
// 将 AOF 缓冲区的内容写入到 AOF 文件
// void flushAppendOnlyFile(int force) force参数表明是否强制刷新,当为0时候,若后台有fsync在执行,则延迟
flushAppendOnlyFile(0);
// 在进入下个事件循环前,执行一些集群收尾工作
if (server.cluster_enabled) clusterBeforeSleep();
}
aeProcessEvents
redis中的事件主要分为两种事件:文件事件(和其他客户端连接产生的事件)和时间事件(定时时间产生的事件)
redis处理时间事件的函数会在服务器运行期间,每隔一段事件运行,处理时间事件,每个事件以链表形式挂在一起,每次处理时候,都是遍历该链表
/* Process time events
*
* 处理所有已到达的时间事件
*/
static int processTimeEvents(aeEventLoop *eventLoop) {
int processed = 0;
aeTimeEvent *te;
long long maxId;
time_t now = time(NULL);
/* If the system clock is moved to the future, and then set back to the
* right value, time events may be delayed in a random way. Often this
* means that scheduled operations will not be performed soon enough.
*
* Here we try to detect system clock skews, and force all the time
* events to be processed ASAP when this happens: the idea is that
* processing events earlier is less dangerous than delaying them
* indefinitely, and practice suggests it is. */
// 通过重置事件的运行时间,
// 防止因时间穿插(skew)而造成的事件处理混乱
if (now < eventLoop->lastTime) {
te = eventLoop->timeEventHead;
while(te) {
te->when_sec = 0;
te = te->next;
}
}
// 更新最后一次处理时间事件的时间
eventLoop->lastTime = now;
// 遍历链表
// 执行那些已经到达的事件
te = eventLoop->timeEventHead;
maxId = eventLoop->timeEventNextId-1;
while(te) {
long now_sec, now_ms;
long long id;
// 跳过无效事件
if (te->id > maxId) {
te = te->next;
continue;
}
// 获取当前时间
aeGetTime(&now_sec, &now_ms);
// 如果当前时间等于或等于事件的执行时间,那么说明事件已到达,执行这个事件
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
int retval;
id = te->id;
// 执行事件处理器,并获取返回值
retval = te->timeProc(eventLoop, id, te->clientData);
processed++;
/* After an event is processed our time event list may
* no longer be the same, so we restart from head.
* Still we make sure to don't process events registered
* by event handlers itself in order to don't loop forever.
* To do so we saved the max ID we want to handle.
*
* FUTURE OPTIMIZATIONS:
* Note that this is NOT great algorithmically. Redis uses
* a single time event so it's not a problem but the right
* way to do this is to add the new elements on head, and
* to flag deleted elements in a special way for later
* deletion (putting references to the nodes to delete into
* another linked list). */
// 记录是否有需要循环执行这个事件时间
if (retval != AE_NOMORE) {
// 是的, retval 毫秒之后继续执行这个时间事件
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else {
// 不,将这个事件删除
aeDeleteTimeEvent(eventLoop, id);
}
// 因为执行事件之后,事件列表可能已经被改变了
// 因此需要将 te 放回表头,继续开始执行事件
te = eventLoop->timeEventHead;
} else {
te = te->next;
}
}
return processed;
}
下面的代码就是redis的事件调度函数
/*
* 事件调度函数
* 处理所有已到达的时间事件,以及所有已就绪的文件事件。
* 如果不传入特殊 flags 的话,那么函数睡眠直到文件事件就绪,
* 或者下个时间事件到达(如果有的话)。
*
* 如果 flags 为 0 ,那么函数不作动作,直接返回。
* 如果 flags 包含 AE_ALL_EVENTS ,所有类型的事件都会被处理。
* 如果 flags 包含 AE_FILE_EVENTS ,那么处理文件事件。
* 如果 flags 包含 AE_TIME_EVENTS ,那么处理时间事件。
* 如果 flags 包含 AE_DONT_WAIT , 那么函数在处理完所有不许阻塞的事件之后,即刻返回。
* 函数的返回值为已处理事件的数量
*/
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
/* Nothing to do? return ASAP */
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0;
/* Note that we want call select() even if there are no
* file events to process as long as we want to process time
* events, in order to sleep until the next time event is ready
* to fire. */
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
// 获取最近的时间事件
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 如果时间事件存在的话
// 那么根据最近可执行时间事件和现在时间的时间差来决定文件事件的阻塞时间
long now_sec, now_ms;
// 计算距今最近的时间事件还要多久才能达到
// 并将该时间距保存在 tv 结构中
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;
if (shortest->when_ms < now_ms) {
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000;
tvp->tv_sec --;
} else {
tvp->tv_usec = (shortest->when_ms - now_ms)*1000;
}
// 时间差小于 0 ,说明事件已经可以执行了,将秒和毫秒设为 0 (不阻塞)
if (tvp->tv_sec < 0) tvp->tv_sec = 0;
if (tvp->tv_usec < 0) tvp->tv_usec = 0;
} else {
// 执行到这一步,说明没有时间事件
// 那么根据 AE_DONT_WAIT 是否设置来决定是否阻塞,以及阻塞的时间长度
/* If we have to check for events but need to return
* ASAP because of AE_DONT_WAIT we need to set the timeout
* to zero */
if (flags & AE_DONT_WAIT) {
// 设置文件事件不阻塞
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
/* Otherwise we can block */
// 文件事件可以阻塞直到有事件到达为止
tvp = NULL; /* wait forever */
}
}
// 处理文件事件,阻塞时间由 tvp 决定
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
/* note the fe->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
// 读事件
if (fe->mask & mask & AE_READABLE) {
// rfired 确保读/写事件只能执行其中一个
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
processed++;
}
}
// 执行时间事件
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
return processed;
}
/*
* 获取可执行事件
*/
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
// 等待时间
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
// 有至少一个事件就绪?
if (retval > 0) {
int j;
// 为已就绪事件设置相应的模式
// 并加入到 eventLoop 的 fired 数组中
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
// 返回已就绪事件个数
return numevents;
}
由上面代码可知,因为文件事件是随机出现的,如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将再次等待并处理文件事件。随着文件事件的不断执行,时间会逐渐向时间事件所设置的到达时间逼近,并最终来到到达时间,这时服务器就可以开始处理到达的时间事件了。
自己的网址:www.shicoder.top
欢迎加群聊天 452380935
本文由博客一文多发平台 OpenWrite 发布!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!