


解决Hadoop中Namenode单点故障的几个方案比较
正如大家所知,NameNode在Hadoop系统中存在单点故障问题,这个对于标榜高可用性的Hadoop来说一直是个软肋。本文讨论一下为了解决这个问题而存在的几个solution。
1. Secondary NameNode
原理:Secondary NN会定期的从NN中读取editlog,与自己存储的Image进行合并形成新的metadata image
优点:Hadoop较早的版本都自带,配置简单,基本不需要额外资源(可以与datanode共享机器)
缺点:恢复时间慢,会有部分数据丢失
2. Backup NameNode
原理:backup NN实时得到editlog,当NN宕掉后,手动切换到Backup NN;
优点:从hadoop0.21开始提供这种方案,不会有数据的丢失
缺点:因为需要从DataNode中得到Block的location信息,在切换到Backup NN的时候比较慢(依赖于数据量)
3. Avatar NameNode
原理:这是Facebook提供的一种HA方案,将client访问hadoop的editlog放在NFS中,Standby NN能够实时拿到editlog;DataNode需要同时与Active NN和Standby NN report block信息;
![]()
优点:信息不会丢失,恢复快(秒级)
缺点:Facebook基于Hadoop0.2开发的,部署起来稍微麻烦;需要额外的机器资源,NFS成为又一个单点(不过故障率低)
4. Hadoop2.0直接支持StandBy NN,借鉴Facebook的Avatar,然后做了点改进
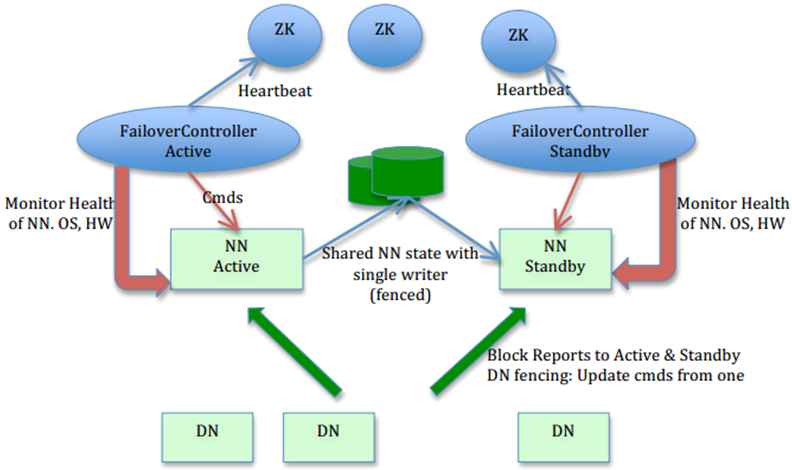
优点:信息不会丢失,恢复快(秒级),部署简单
缺点:
