

记一次生产环境性能优化真实案例
随着公司交易量增长,应用侧TPS下降,接口耗时变长,业务高峰期甚至会有请求超时的情况。但是应用服务器CPU不到50%,内存占用40%(4C8G配置),load average: 0.43, 0.45, 0.49;负载很低。
数据库为ORACLE 11G,CPU:128C,内存:512G,存储:14T。业务高峰期CPU用掉60%,IO空闲45%。
主要接口平均耗时统计,每分钟一个点,从下图可以看出在业务量不大的时候,平均耗时在25毫秒左右。一旦到了业务高峰期,平均耗时最大值突然涨到120毫秒。
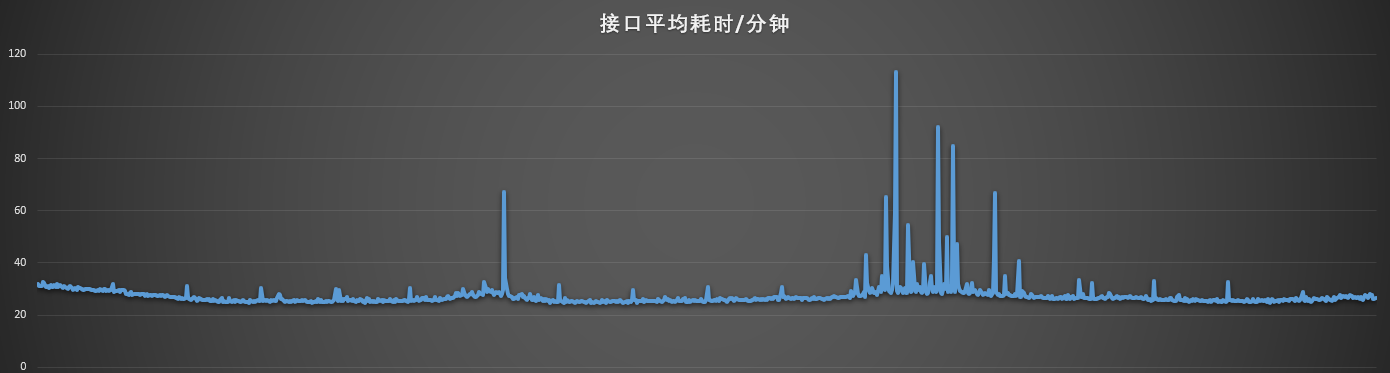
数据库监控图:高峰时段CPU和IO使用率非常高。

情况发生后,立即成立了攻关小组,毕竟临近五一假期只有一周的时间了,五一假期期间交易量至少还会增长30%。
第一阶段分析后,制定如下几点改造方案:
1、修改应用Druid连接池初始化连接数,从Druid监控看高峰时段最大连接数峰值为27,有可能是瞬间交易量激增导致连接数不够用,以往经验告诉我们新创建数据库连接耗时会比较长,会导致瞬间的请求排队等待获取连接。所以决定把初始值20改为30。
2、因账务库(Oracle)采用两主一从高可用部署(A,B为主节点,C为从节点),目前所有应用系统配置的主节点都是A,从节点都是B。决定把一部分应用主节点调成B,以降低A节点压力。
3、账务幂等表改造,现幂等表已实现分表4张(单表4亿条数据),但是从整个记账请求耗时分析,幂等表和账务流水表的查询和插入操作耗时比较严重。因此决定把幂等表扩展到64张(为什么是64张,是经过科学计算的,具体计算过程因保密不能说哈)。
4、MQ接管,因为临近五一,各方压力较大,如果以上优化点不能成功,最坏的打算是走MQ异步接管机制,但是本方案会对业务造成影响,不到万不得已不会使用。
改造方案确定后,开启加班模式,兄弟们夜以继日很快改造完成,上线投产。但上线后效果和预期相差甚远。
方案1:投产后发现高峰时段记账耗时仍然比较严重,调整druid连接池不但没有效果,反而增加了数据库连接数,浪费了资源,回退。
方案2:主次节点调换顺序后,出现数据库资源争抢严重,频繁GC,Cpu使用率反而升高,回退。
方案3:幂等表分64张之后,新表的读写速度很快平均0.7毫秒,老幂等表平均4.7毫秒,但是因为老幂等表数据量较大,没有重新做hash洗数据,所以还要代码层还要兼容老幂等表的查询,对整体效率并没有提高。
第一阶段总结:除了方案3长远看有成效,其它两个方案都没有解决问题,反思后觉得我们方向错了,还是没有对症下药。于是大家重新走上了求医道路。
第二阶段分析后,又制定了如下两个方案:
1、就在此时DBA发现一个新的问题,业务高峰期,账务流水表和会计流水表存在索引分裂问题,初步怀疑是因为流水号采用了递增模式(通过sequence生成,且为索引列),PS:发生索引分裂主要是因为较小的序号往比它大的值前面插入,而当前索引块空间已经不够了,就需要把原索引块(Index Block)分裂成两个,以保证较小的值能够插到前面去。这样就带来一个问题,旧有块的部分数据需要放到新开辟的索引块上去。频繁的索引分裂肯定不是一个好事。所以决定把流水号生成方式改成雪化算法。
索引分裂:index block split : 就是索引块的分裂,当一次DML 事务操作修改了索引块上的数据,但是旧有的索引块没有足够的空间去容纳新修改的数据,那么将分裂出一个新的索引块,旧有块的部分数据放到新开辟的索引块上去。
2、目前流水表按照日期采用5天一个分区,保留2个月数据。讨论后决定改成1天一个分区且只保留近10天数据。为什么不做分表,因为流水表涉及数据同步,很多业务线都用到这个表,短时间内无法完成分表改造,而分区对应用系统而言是透明的。
PS:关于索引分裂请参考这个帖子:http://blog.itpub.net/26736162/viewspace-2139232,我们遇到的情况属于9-1分裂,不管是什么类型的索引分裂,对系统而言肯定都不是什么好事。
和第一阶段一样,又开始了加班模式。但是最后投产后效果和第一阶段一样,又白忙乎了。高峰时段数据库压力仍然很大,且高峰时段记账平均耗时依然超过100ms。此时此刻心态已经炸裂,毕竟大家已经加班一周了,身心早已疲惫。但是问题还要继续解决,不然五一黄金周就不用放假了。。。
第三阶段开始,所谓一生二,二生三,三生万物,万物变幻,九九八十一后又再循环,归一。第一阶段优化时就提到从整个记账请求耗时分析,幂等表和账务流水表的查询和插入操作耗时比较严重,此时幂等表已经分表完成,那么如果把插流水操作改成异步插入呢?没错,首先流水异步插入不会对业务造成影响,其次改成异步后可以降低整个事务周期,事务耗时小了,可以更快的释放资源。最后就算没有效果,通过异步写入也可以达到一个削峰的目的。通过MQ积压,降低数据库写入速度,保护数据库。
PS:因为流水表每天都是亿级流水写入,数据量还是比较大的。
修改后我们很快上线了,毕竟时间宝贵,果然九九归一,有效果了。

上图中灰色是我们把流水改为异步插入后的耗时曲线,和之前比效果非常明显。即使高峰时段,耗时也只有30几毫秒。
再看一下数据库监控图,和之前比,压力已经下降的非常明显了,此时终于松了一口气。开始幻想单县老家的羊肉汤了,哈哈。

第四阶段优化:但是作为一个技术人,此时不应该得到满足,回头想想索引分裂的事情,确实是科学的,不应该改了没有作用。重新梳理后发现开发小伙伴使用的雪化算法是变异后的算法,说白了就是只能保证全局散列(分布式而言),但是局部仍然是连续的(单机而言)。如果直接改用uuid呢,抱着试一试的想法,又进行了一轮改造。果然这一想法得到验证。
投产后数据库压力又降了不少。下面三张图展示了优化前,应用优化,索引分裂优化的效果。
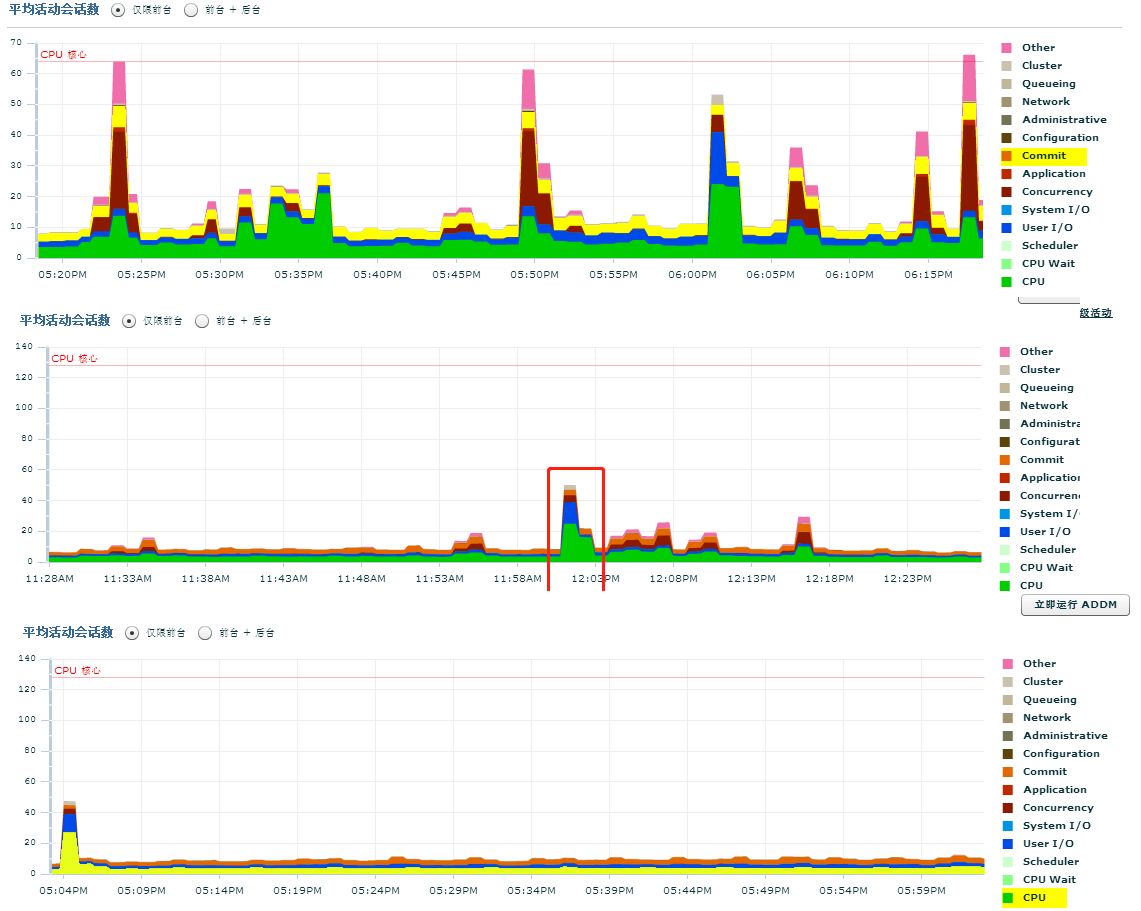
此文献给参与优化的小伙伴,献给五一假期。
补充:最后释放了8台4C8G虚拟机。

