原理剖析:InnoDB与MyISAM 聚集索引与非聚集索引
索引(Index)概述
索引(Index)是帮助MySQL高效获取数据的数据结构。MyISAM和Innodb都使用了B+树这种数据结构做为索引。
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。索引分为聚簇索引和非聚簇索引两种,在一个表中只能有一个聚集索引,一般以主键作为聚集索引,而非聚集索引可以有多个。
Innodb引擎
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
MyIASM引擎
MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
两种引擎的选择
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,关于这个问题我会在下文中讲到。大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些,但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
Mysql的存储引擎和索引
可以说数据库必须有索引,没有索引则检索过程变成了顺序查找,O(n)的时间复杂度几乎是不能忍受的。我们非常容易想象出一个只有单关键字组成的表如何使用B+树进行索引,只要将关键字存储到树的节点即可。当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。
有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。对于非聚簇索引存储来说,主键B+树在叶子节点存储指向真正数据行的指针,而非主键。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。并且和MyISAM不同,InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
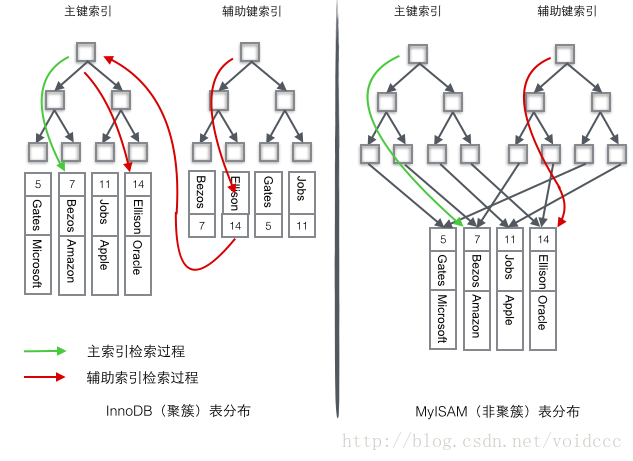
我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
---------------------
本文参考自:
https://blog.csdn.net/voidccc/article/details/40077329
https://www.2cto.com/database/201503/385669.html
————————————————
版权声明:本文为CSDN博主「MagnumLu」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_28584889/article/details/88778741

 浙公网安备 33010602011771号
浙公网安备 33010602011771号