


关于MapReduce的理解
其实我们可以从word count这个实例来理解MapReduce。
MapReduce大体上分为六个步骤:
input, split, map, shuffle, reduce, output。
细节描述如下:
输入(input):如给定一个文档,
包含如下四行:
Hello Java
Hello C
Hello Java
Hello C++
拆分(split):
将上述文档中每一行的内容转换为key-value对,
即:
0 - Hello Java
1 - Hello C
2 – Hello Java
3 - Hello C++
3. 映射(map):
将拆分之后的内容转换成新的key-value对,
即:
(Hello , 1)
(Java , 1)
(Hello , 1)
(C , 1)
(Hello , 1)
(Java , 1)
(Hello , 1)
(C++ , 1)
4. 派发(shuffle):
将key相同的扔到一起去,
即:
(Hello , 1)
(Hello , 1)
(Hello , 1)
(Hello , 1)
(Java , 1)
(Java , 1)
(C , 1)
(C++ , 1)
注意:这一步需要移动数据,原来的数据可能在不同的datanode上,这一步过后,相同key的数据会被移动到同一台机器上。
最终,它会返回一个list包含各种k-value对,
即:
{ Hello: 1,1,1,1}
{Java: 1,1}
{C: 1}
{C++: 1}
5. 缩减(reduce):
把同一个key的结果加在一起。
如:
(Hello , 4)
(Java , 2)
(C , 1)
(C++,1)
6. 输出(output): 输出缩减之后的所有结果。
前面文章中我们已经介绍了 Hadoop 中重要的模块 HDFS,今天我们来说说MapReduce,那么为什么要说 MapReduce 呢?
老规矩,我们再来说个小故事。回忆起小时候念书的时候个子比较瘦小,在学校经常受到其他大个子同学的欺负,没办法谁让我打不过他呢?那怎么办呢,总不能老是白白的给人欺负吧,当然不,哥也不是好惹的,我一个人打不过没关系的,我记得有一次真把我惹毛了,我就去叫了几个玩的要好的小伙伴,合起来去揍他,最后结果就是打的他鼻青脸肿的,一次就把他治的服服帖帖的。这个小故事我只想说明一点:
人多力量大,一个人干不过他,那就多找几个人一起。
1.MapReduce编程模型
HDFS 解决了大数据存储的问题,那么 MapReduce 自然要解决的是数据计算问题。前面已经说强调了一点,人多力量大啊,同样的道理,在处理大数据计算中,一个台机器是无法满足大批量数据计算的,那怎么办?轮到 MapReduce 闪亮登场了,MapReduce是一种编程模型,用于大规模数据集的并行计算,需要将数据分配到大量的机器上计算,每台机器运行一个子计算任务,最后再合并每台机器运算结果并输出。 MapReduce 的思想就是 『分而治之』
MapReduce 将整个并行计算过程抽象到两个函数,在 Map 中进行数据的读取和预处理,之后将预处理的结果发送到 Reduce 中进行合并。一个简单的 MapReduce 程序只需要指定 map()、reduce()、 input 和output,剩下的事由框架完成。
Map ( 映射 ) : 对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。
Reduce( 化简 ) : 对一个列表的元素进行合并。
2.MapReduce执行流程
以经典的 WordCount 的例子来说明一下MapReduce的执行流程,WordCount就是统计每个单词出现的次数。
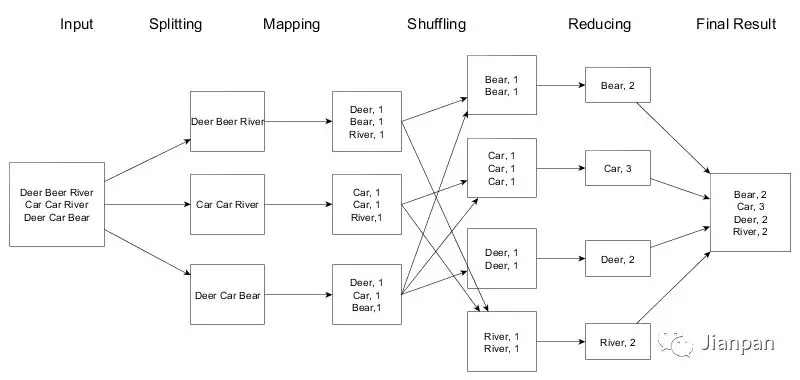
MapReduce计算框架的一般流程有以下几个步骤:
-
输入 ( Input ) 和拆分 ( Split ):
对数据进行分片处理。将源文件内容分片成一系列的 InputSplit,每个 InputSplit 存储着对应分片的数据信息,记住是对文件内容进行分片,并不是将源文件拆分成多个小文件。
-
迭代 ( iteration ):
遍历输入数据,并将之解析成 key/value 对。拆分数据片经过格式化成键值对的格式,其中 key 为偏移量,value 是每一行的内容,这一步由MapReduce框架自动完成。
-
映射 ( Map ):
将输入 key/value 对映射 ( map ) 成另外一些 key/value 对。MapReduce 开始在机器上执行 map 程序,map 程序的具体实现由我们自己定义,对输入的 key/value 进行处理,输出新的 key/value,这也是hadoop 并行事实发挥作用的地方。
-
洗牌 ( Shuffer ) 过程:
依据 key 对中间数据进行分组 ( grouping )。这是一个洗牌的过程,得到map方法输出的 <key,value> 对后,Mapper 会将它们按照 key 值进行处理,这包括 sort (排序)、combiner (合并)、partition (分片) 等操作达到排序分组和均衡分配,得到 Mapper 的最终输出结果交给 Reducer。mapper 和 reducer 一般不在一个节点上,这就导致了reducer 需要从不同的节点上下载数据,经过处理后才能交给 reducer 处理。
-
归并( Reduce ):
以组为单位对数据进行归约 ( reduce )。Reducer 先对从 Mapper 接收的数据进行排序,再交由用户自定义的 reduce方法进行处理。
-
迭代:
将最终产生的 key/value 对保存到输出文件中。得到新的 <key,value> 对,保存到输出文件中,即保存在 HDFS 中。
3.数据本地化
前面的文章中我已经介绍了 Hadoop 的核心就是存储( HDFS )和计算( MapReduce )。HDFS 提供了对海量数据的存储支持,MapReduce提供了对海量数据计算处理。
上篇 HDFS 的文章中已经介绍了 NameNode(文件系统),DataNode(数据节点)。MapReduce 计算框架中负责计算任务调度的 JobTracker 对应 HDFS 的 NameNode 的角色,只不过一个负责计算任务调度,一个负责存储任务调度。MapReduce 计算框架中负责真正计算任务的 TaskTracker 对应到 HDFS 的 DataNode 的角色,一个负责计算,一个负责管理存储数据。
考虑到数据本地化的原则,一般将 JobTracker 和 NameNode 部署在一台机器上,而将 TaskTracker 和对应的 DataNode 部署在一个机器上。为什么要这样分配呢?都说近水楼台先得月,你数据跟我计算任务挨得近,我不是轻而易举的就给你处理了,省去了不同机器之间数据传输的消耗,这就是所谓的 "运算移动,数据不移动"。
下一篇将深入 MapReduce 工作原理,Shuffer 过程等,敬请期待。

