Tornado 框架使用详解, 从懵逼到开撸
安装
pip install tornado
简单 web_demo
代码

# coding:utf-8 import tornado.web import tornado.ioloop class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): # 我们修改了这里 """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) app.listen(8000) tornado.ioloop.IOLoop.current().start()
测试效果
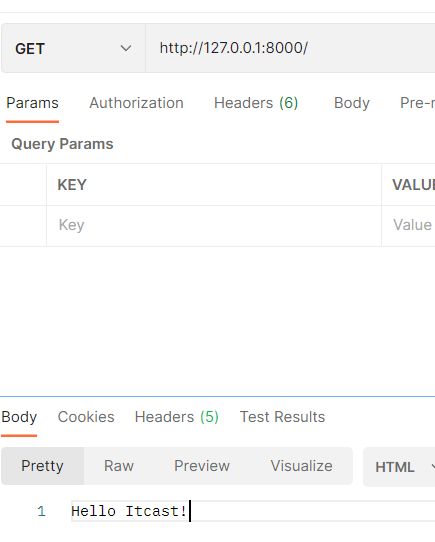
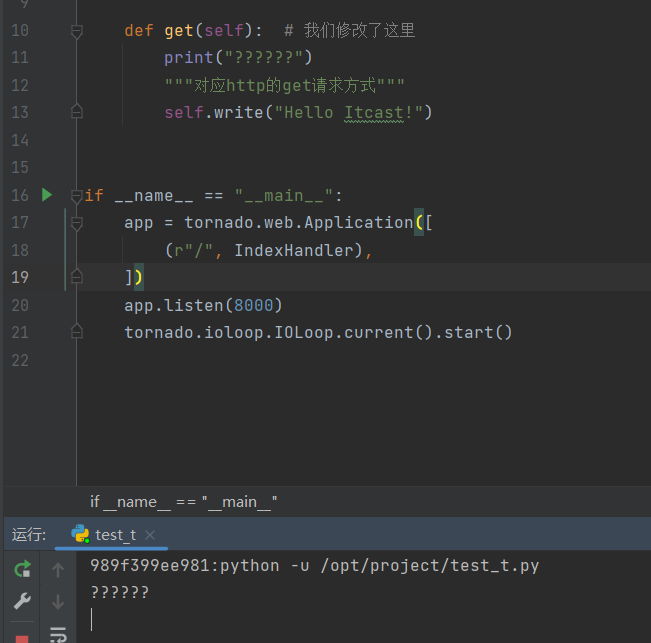
演示解析
继承自 tornado.web.RequestHandler 的类, 重写 基于 http method 的小写方法。 则可以指定该请求方式下的逻辑
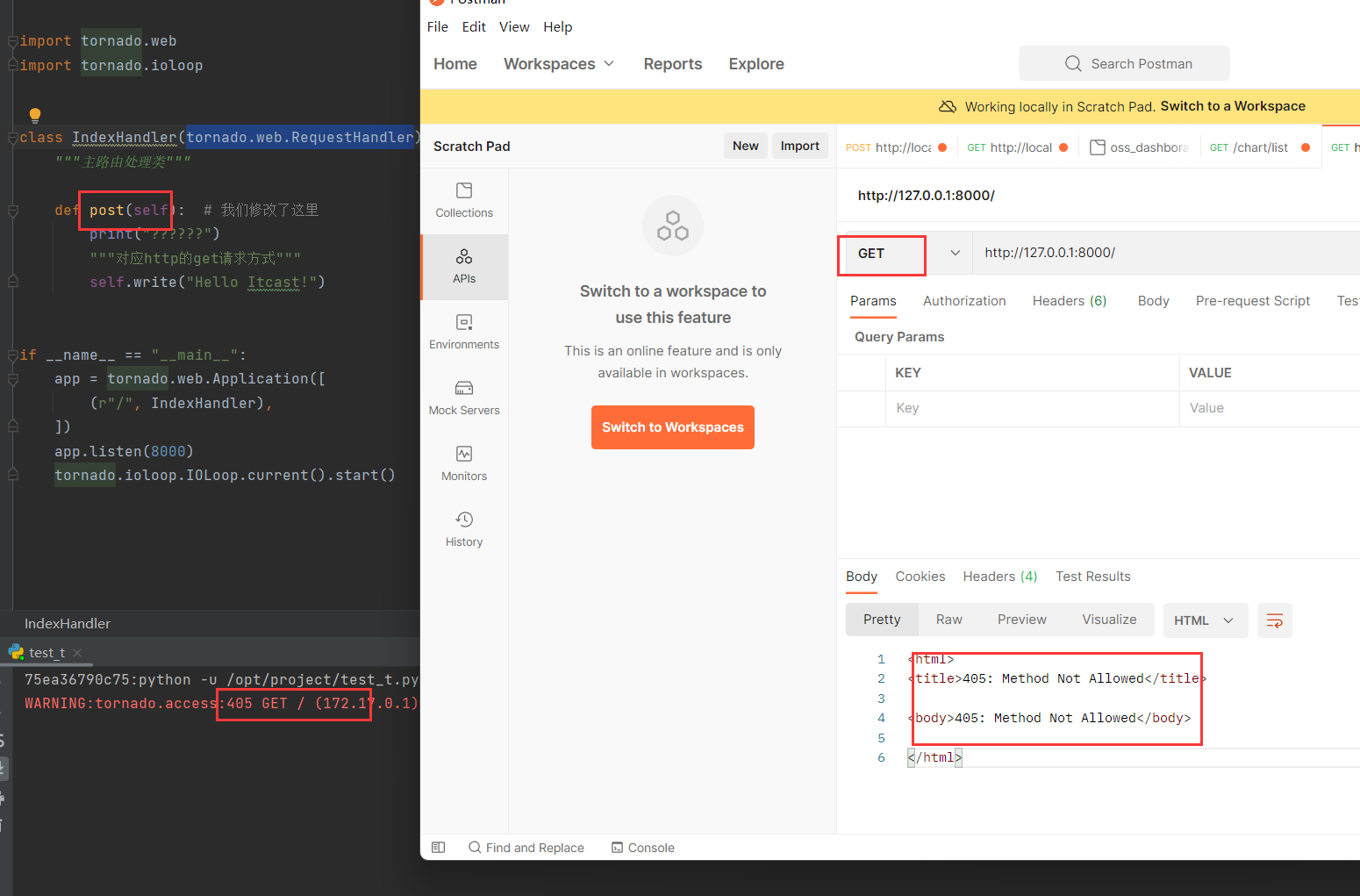
如果位指定具体的请求类型。 则不支持, 返回 405
验证 405
核心组件说明
代码demo
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver # 新引入httpserver模块 class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(8000) tornado.ioloop.IOLoop.current().start()
解析
组件
ioloop
tornado.ioloop.IOLoop.current()
它是全局的tornado事件循环,是服务器的引擎核心 ( 可包含多个 app,示例中只有1个,实际上可以允许多个,不过一般几乎不会使用多个)
app
app = tornado.web.Application([ (r"/", IndexHandler), ])
代表着一个完成的后端app,它会挂接一个服务端套接字端口对外提供服务。
一个ioloop实例里面可以有多个app实例
handler
class IndexHandler(tornado.web.RequestHandler): ...
代表着业务逻辑,我们进行服务端开发时就是编写一堆一堆的handler用来服务客户端请求
路由表
[ (r"/", IndexHandler), ]
它将指定的url规则和handler挂接起来,形成一个路由映射表。当请求到来时,根据请求的访问url查询路由映射表来找到相应的业务handler
组件关系
一个ioloop包含多个app , 一个app包含一个路由表,一个路由表包含多个handler,同一个ioloop实例运行在一个单线程环境下
ioloop是服务的引擎核心,它是发动机,负责接收和响应客户端请求,负责驱动业务handler的运行,负责服务器内部定时任务的执行
当一个请求到来时,ioloop读取这个请求解包成一个http请求对象, 找到该套接字上对应app的路由表, 通过请求对象的url查询路由表中挂接的handler
然后执行handler, handler方法执行后一般会返回一个对象,ioloop负责将对象包装成http响应对象序列化发送给客户端
单多进程
简单 demo 中的 app.listen() 和 http_server = tornado.httpserver.HTTPServer(app) / http_server.listen(8000) 不同就在于
app.listen() 是只能在单进程下使用, listen是bind和start指令的简称
相当于以下代码的简写, 就是直接只绑定了一个进程
http_server.bind(options.port)
http_server.start(num_processes=1)
多进程实现
tornado 具备一次性开启多个进程的能力,如以下代码 num_processes=2 就代表开启两个进程
ps: 在使用多进程启动的时候,需要关掉 debug 模式 settings = {'debug' : False}
from tornado.httpserver import HTTPServer if __name__ == '__main__': # 单进程启动 # app.listen(8000) # Run.instance().start() # 多进程启动 server = HTTPServer(app) server.bind(8000) server.start(num_processes=2) Run.instance().start()
多进程原理
此处引用自 这里
Tornado 多进程的处理流程是先创建 socket, 然后再 fork 子进程, 这样所有的子进程实际都监听 一个(或多个)文件描述符, 也就是都在监听同样的 socket.
当连接过来所有的子进程都会收到可读事件, 这时候所有的子进程都会跳到回调函数, 尝试建立连接.
一旦其中一个子进程成功的建立了连接, 当其他子进程再尝试建立这个连接的时候就会触发 EWOULDBLOCK (或 EAGAIN) 错误. 这时候回调函数判断是这个错误则返回函数不做处理.
当成功建立连接的子进程还在处理这个连接的时候又过来一个连接, 这时候就会有另外一个子进程接手这个连接.
Tornado 就是通过这样一种机制, 利用多进程提升效率, 由于连接只能由一个子进程成功创建, 同一个请求也就不会被多个子进程处理.
多进程问题解析
提供了便利的同时, 但是也带来了一系列问题
- 每个子进程都会从父进程中复制一份IOLoop实例,如过在创建子进程前我们的代码动了IOLoop实例,那么会影响到每一个子进程,势必会干扰到子进程IOLoop的工作
- 所有进程是由一个命令一次开启的,也就无法做到在不停服务的情况下更新代码
- 所有进程共享同一个端口,想要分别单独监控每一个进程就很困难
因此不建议直接使用自带的 多进程启动方式, 而是手动开启多个进程,并且绑定不同的端口 这部分的内容则放在部署方面后面再说
options 全局配置
tornado.options模块, 提供了全局参数定义、存储、转换
全局的options对象,所有定义的选项变量都会作为该对象的属性
导入
import tornado.options
定义
tornado.options.define() 用来定义options选项变量的方法,定义的变量可以在全局的 tornado.options.options.xxxx 中获取使用,传入参数:
- name 选项变量名,须保证全局唯一性,否则会报“Option 'xxx' already defined in ...”的错误;
- default 选项变量的默认值,如不传默认为None;
- type 选项变量的类型,从命令行或配置文件导入参数的时候tornado会根据这个类型转换输入的值
- 转换不成功时会报错,可以是str、float、int、datetime、timedelta中的某个
- 若未设置则根据default的值自动推断,若default也未设置,那么不再进行转换。
- 可以通过利用设置type类型字段来过滤不正确的输入。
- multiple 选项变量的值是否可以为多个,布尔类型,默认值为False
- 如果multiple为True,那么设置选项变量时值与值之间用英文逗号分隔,
- 选项变量是一个list列表(若默认值和输入均未设置,则为空列表[])。
- help选项变量的帮助提示信息
- 在命令行启动tornado时,通过加入命令行参数 --help 可以查看所有选项变量的信息
- 注意,代码中需要加入 tornado.options.parse_command_line()
tornado.options.options 全局的options对象,所有定义的选项变量都会作为该对象的属性。
tornado.options.parse_command_line() 转换命令行参数,并将转换后的值对应的设置到全局options对象相关属性上。 追加命令行参数的方式是--myoption=myvalue
tornado.options.parse_config_file(path) 从配置文件导入option,配置文件中的选项格式如下
ps: 配置文件中的优先级会别代码中的高, 会覆盖代码中的配置使用文件中配置
myoption = "myvalue" myotheroption = "myothervalue"
代码示例
import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options # 新导入的options模块 tornado.options.define("port", default=8000, type=int, help="run server on the given port.") # 定义服务器监听端口选项 tornado.options.define("itcast", default=[], type=str, multiple=True, help="itcast subjects.") # 无意义,演示多值情况 class IndexHandler(tornado.web.RequestHandler): def get(self): self.write("Hello Itcast!") if __name__ == "__main__": tornado.options.parse_command_line() print(tornado.options.options.port) # 输出 port 配置 print(tornado.options.options.itcast) # 输出 itcast 配置 app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(tornado.options.options.port) tornado.ioloop.IOLoop.current().start()
输出
e1e3dd436abd:python -u /opt/project/test_t.py 8000 []
文件配置写入示例
配置文件
port = 8000 itcast = ["python","c++","java","php","ios"]
代码
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options tornado.options.define("port", default=9000, type=int, help="run server on the given port.") tornado.options.define("itcast", default=[], type=str, multiple=True, help="itcast subjects.") class IndexHandler(tornado.web.RequestHandler): def get(self): self.write("Hello Itcast!") if __name__ == "__main__": tornado.options.parse_config_file("./config") # 仅仅修改了此处, 新添加了一行,文件中优先级比代码中的高 print(tornado.options.options.port) # 输出 port 配置 print(tornado.options.options.itcast) # 输出 itcast 配置 app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(tornado.options.options.port) tornado.ioloop.IOLoop.current().start()
输出
6faf7901fdae:python -u /opt/project/test_t.py 8000 ['python', 'c++', 'java', 'php', 'ios']
特殊日志说明
调用 parse_command_line() 或者 parse_config_file() 的方法时
tornado会默认为我们配置标准logging模块
即默认开启了日志功能,并向标准输出(屏幕)打印日志信息。
如果想关闭tornado默认的日志功能
可以在命令行中添加 --logging=none 或者在代码中执行如下操作
from tornado.options import options, parse_command_line options.logging = None parse_command_line()
配置文件写入
prase_config_file() 的时候,配置文件的书写格式仍需要按照python的语法要求,
其优势是可以直接将配置文件的参数转换设置到全局对象tornado.options.options中
然而,其不方便的地方在于需要在代码中调用tornado.options.define()来定义选项
而且不支持字典类型,故而在实际应用中大都不使用这种方法
在使用配置文件的时候,通常会新建一个python文件(如config.py)
然后在里面直接定义python类型的变量(可以是字典类型)
在需要配置文件参数的地方,将config.py作为模块导入从而使用其中的变量参数
示例
配置文件 config.py
# conding:utf-8 # Redis配置 redis_options = { 'redis_host':'127.0.0.1', 'redis_port':6379, 'redis_pass':'', } # Tornado app配置 settings = { 'template_path': os.path.join(os.path.dirname(__file__), 'templates'), 'static_path': os.path.join(os.path.dirname(__file__), 'statics'), 'cookie_secret':'0Q1AKOKTQHqaa+N80XhYW7KCGskOUE2snCW06UIxXgI=', 'xsrf_cookies':False, 'login_url':'/login', 'debug':True, } # 日志 log_path = os.path.join(os.path.dirname(__file__), 'logs/log')
导入
# conding:utf-8 import tornado.web import config if __name__ = "__main__": app = tornado.web.Application([], **config.settings)
debug 模式
debug,设置tornado是否工作在调试模式,默认为False即工作在生产模式
当设置debug=True 后,tornado会工作在调试/开发模式
特性
在此种模式下,tornado为方便我们开发而提供了几种特性:
- 自动重启,tornado应用会监控我们的源代码文件,当有改动保存后便会重启程序
- 一旦我们保存的更改有错误,自动重启会导致程序报错而退出,从而需要我们保存修正错误后手动启动程序
- 这一特性也可单独通过autoreload=True设置
- 取消缓存编译的模板
- 可以单独通过compiled_template_cache=False来设置
- 取消缓存静态文件hash值
- 可以单独通过static_hash_cache=False来设置
- 提供追踪信息,当RequestHandler或者其子类抛出一个异常而未被捕获后,会生成一个包含追踪信息的页面
- 可以单独通过serve_traceback=True来设置
代码生效开启 debug
import tornado.web tornado.options.parse_command_line() app = tornado.web.Application([], debug=True)
路由映射
路由映射支持多个参数和多种模式如下
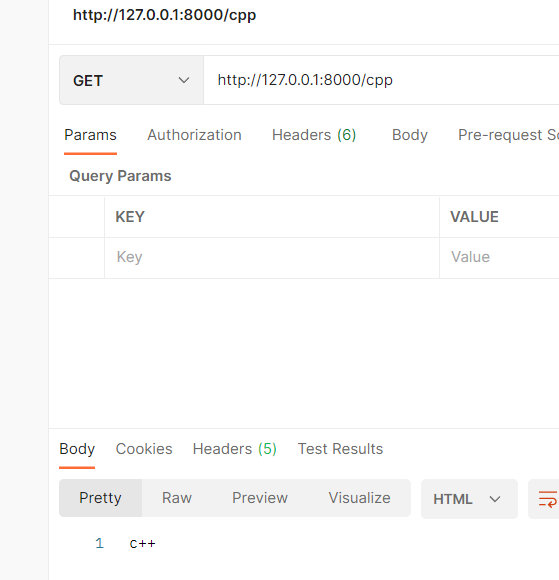
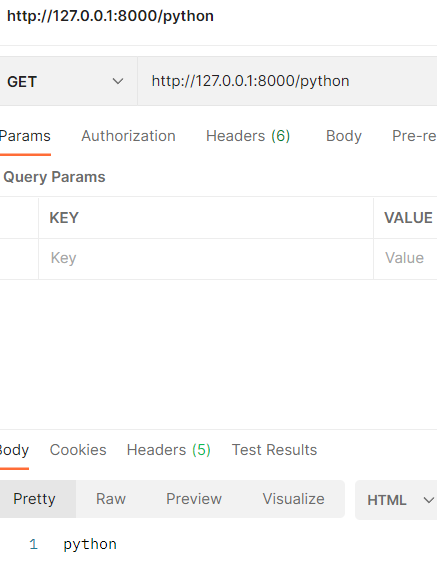
[ (r"/", Indexhandler), (r"/cpp", ItcastHandler, {"subject":"c++"}), url(r"/python", ItcastHandler, {"subject":"python"}, name="python_url") ]
常规模式 [(r"/", IndexHandler),] 直接映射到handler
带拓展信息的模式 (r"/cpp", ItcastHandler, {"subject":"c++"}), 此时路由中的字典, 会传入到对应的 RequestHandler的initialize()
from tornado.web import RequestHandler class ItcastHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject)
带 name 的时候则需要特殊的方法来封装 from tornado.web import url, RequestHandler tornado.web.url
name是给该路由起一个名字,可以通过调用 RequestHandler.reverse_url(name) 来获取该名字对应的url
代码示例
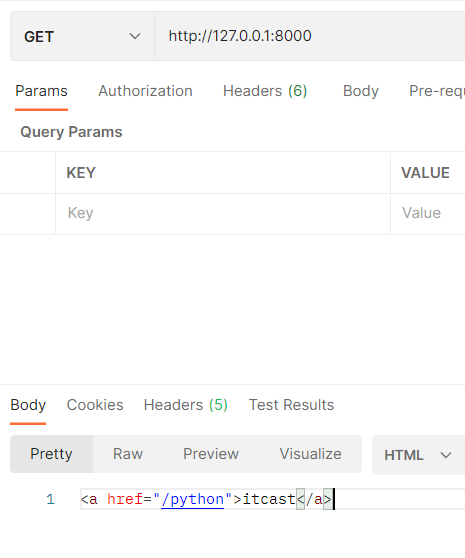
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import url, RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): python_url = self.reverse_url("python_url") self.write('<a href="%s">itcast</a>' % python_url) class ItcastHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", Indexhandler), (r"/cpp", ItcastHandler, {"subject":"c++"}), url(r"/python", ItcastHandler, {"subject":"python"}, name="python_url") ], debug = True) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()
演示
request 相关
获得请求参数
HTTP 请求的参数获取途径如下
- 查询字符串(query string),形如 key1=value1&key2=value2
- 请求体(body)中发送的数据,比如表单数据、json、xml
- 提取 url 的特定部分,如 /blogs/2016/09/0001 ,可以在服务器端的路由中用正则表达式截取
- 在http报文的头(header)中增加自定义字段,如 X-XSRFToken=itcast
获取查询URL中拼接参数
get_query_argument(name, default=_ARG_DEFAULT, strip=True)
name: 要获取的参数值,如果出现多个同名参数,则返回最后一个的值。
default: 为设值未传name参数时返回的默认值,如若default也未设置,则会抛出 tornado.web.MissingArgumentError 异常。
strip: 表示是否过滤掉左右两边的空白字符,默认为过滤。
get_query_arguments(name, strip=True)
注意返回的是list列表(即使对应name参数只有一个值)
若未找到name参数,则返回空列表[]
获取请求体中参数
get_body_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值
default与strip同前,不再赘述
get_body_arguments(name, strip=True)
一样返回的是列表
获取URL或请求体中参数
get_argument(name, default=_ARG_DEFAULT, strip=True)
get_arguments(name, strip=True)
正则定义参数
tornado中对于路由映射也支持正则提取uri
提取出来的参数会作为RequestHandler中对应请求方式的成员方法参数
若在正则表达式中定义了名字,则参数按名传递
若未定义名字,则参数按顺序传递。
提取出来的参数会作为对应请求方式的成员方法的参数
建议:提取多个值时最好用命名方式
request 中的其他属性
详细


"""A single HTTP request. All attributes are type `str` unless otherwise noted. .. attribute:: method HTTP request method, e.g. "GET" or "POST" .. attribute:: uri The requested uri. .. attribute:: path The path portion of `uri` .. attribute:: query The query portion of `uri` .. attribute:: version HTTP version specified in request, e.g. "HTTP/1.1" .. attribute:: headers `.HTTPHeaders` dictionary-like object for request headers. Acts like a case-insensitive dictionary with additional methods for repeated headers. .. attribute:: body Request body, if present, as a byte string. .. attribute:: remote_ip Client's IP address as a string. If ``HTTPServer.xheaders`` is set, will pass along the real IP address provided by a load balancer in the ``X-Real-Ip`` or ``X-Forwarded-For`` header. .. versionchanged:: 3.1 The list format of ``X-Forwarded-For`` is now supported. .. attribute:: protocol The protocol used, either "http" or "https". If ``HTTPServer.xheaders`` is set, will pass along the protocol used by a load balancer if reported via an ``X-Scheme`` header. .. attribute:: host The requested hostname, usually taken from the ``Host`` header. .. attribute:: arguments GET/POST arguments are available in the arguments property, which maps arguments names to lists of values (to support multiple values for individual names). Names are of type `str`, while arguments are byte strings. Note that this is different from `.RequestHandler.get_argument`, which returns argument values as unicode strings. .. attribute:: query_arguments Same format as ``arguments``, but contains only arguments extracted from the query string. .. versionadded:: 3.2 .. attribute:: body_arguments Same format as ``arguments``, but contains only arguments extracted from the request body. .. versionadded:: 3.2 .. attribute:: files File uploads are available in the files property, which maps file names to lists of `.HTTPFile`. .. attribute:: connection An HTTP request is attached to a single HTTP connection, which can be accessed through the "connection" attribute. Since connections are typically kept open in HTTP/1.1, multiple requests can be handled sequentially on a single connection. .. versionchanged:: 4.0 Moved from ``tornado.httpserver.HTTPRequest``. """
常用
RequestHandler.request 对象存储了关于请求的相关信息,具体属性有:
- method HTTP的请求方式,如GET或POST
- host 被请求的主机名
- uri 请求的完整资源标示,包括路径和查询字符串
- path 请求的路径部分
- query 请求的查询字符串部分
- version 使用的HTTP版本
- headers 请求的协议头,是类字典型的对象,支持关键字索引的方式获取特定协议头信息,例如:request.headers["Content-Type"]
- body 请求体数据
- remote_ip 客户端的IP地址
- files 用户上传的文件,为字典类型
tornado.httputil.HTTPFile 是接收到的文件对象,它有三个属性:
- filename 文件的实际名字,与form_filename1不同,字典中的键名代表的是表单对应项的名字
- body 文件的数据实体
- content_type 文件的类型
这三个对象属性可以像字典一样支持关键字索引,如 request.files["form_filename1"][0]["body"]
response 相关
write(chunk)
代码示例
class IndexHandler(RequestHandler): def get(self): self.write("hello itcast!")
支持多次写入如下
class IndexHandler(RequestHandler): def get(self): self.write("hello itcast 1!") self.write("hello itcast 2!") self.write("hello itcast 3!")
json 的写入, 会自动做序列化
class IndexHandler(RequestHandler): def get(self): stu = { "name":"zhangsan", "age":24, "gender":1, } self.write(stu)
注意, 如果是自己手动 json.dumps() 的方式写入时 Content-Type:text/html; charset=UTF-8
自动序列化的时候则为 application/json; charset=UTF-8
set_header(name, value)
可以手动设置一个名为name、值为value的响应头header字段
代码示例
import json class IndexHandler(RequestHandler): def get(self): stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("Content-Type", "application/json; charset=UTF-8")
set_default_headers()
该方法会在进入HTTP处理方法前先被调用,可以重写此方法来预先设置默认的headers
代码示例
class IndexHandler(RequestHandler): def set_default_headers(self): print "执行了set_default_headers()" # 设置get与post方式的默认响应体格式为json self.set_header("Content-Type", "application/json; charset=UTF-8") # 设置一个名为itcast、值为python的header self.set_header("itcast", "python") def get(self): print "执行了get()" stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("itcast", "i love python") # 注意此处重写了header中的itcast字段 def post(self): print "执行了post()" stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json)
set_status(status_code, reason=None)
为响应设置状态码。
参数说明:
- status_code int类型,状态码,
- reason string类型,描述状态码的词组,
redirect(url)
告知浏览器跳转到url
代码示例
class IndexHandler(RequestHandler): """对应/""" def get(self): self.write("主页") class LoginHandler(RequestHandler): """对应/login""" def get(self): self.write('<form method="post"><input type="submit" value="登陆"></form>') def post(self): self.redirect("/")
send_error(status_code=500, **kwargs)
抛出HTTP错误状态码 status_code ,默认为500, kwargs 为可变命名参数
使用 send_error 抛出错误后, tornado会调用 write_error() 方法进行处理
并返回给浏览器处理后的错误页面
class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误")
注意:默认的 write_error() 方法不会处理 send_error() 抛出的kwargs参数
即上面的代码中 content="出现404错误" 是没有意义的
write_error(status_code, **kwargs)
用来处理 send_error() 抛出的错误信息并返回给浏览器错误信息页面
可以重写此方法来定制自己的错误显示页面
class IndexHandler(RequestHandler): def get(self): err_code = self.get_argument("code", None) # 注意返回的是unicode字符串,下同 err_title = self.get_argument("title", "") err_content = self.get_argument("content", "") if err_code: self.send_error(err_code, title=err_title, content=err_content) else: self.write("主页") def write_error(self, status_code, **kwargs): self.write(u"<h1>出错了,程序员GG正在赶过来!</h1>") self.write(u"<p>错误名:%s</p>" % kwargs["title"]) self.write(u"<p>错误详情:%s</p>" % kwargs["content"])
接口与调用顺序
initialize()
对应每个请求的处理类 Handler 在构造一个实例后, 首先执行i此方法
路由映射中的第三个字典型参数会作为该方法的命名参数传递,如:
class ProfileHandler(RequestHandler): def initialize(self, database): self.database = database def get(self): ... app = Application([ (r'/user/(.*)', ProfileHandler, dict(database=database)), ])
此方法通常用来初始化参数(对象属性),很少使用
prepare()
预处理,即在执行对应请求方式的HTTP方法(如 get、pos t等)前先执行
ps: 不论以何种HTTP方式请求,都会执行此方法
代码示例
import json class IndexHandler(RequestHandler): def prepare(self): if self.request.headers.get("Content-Type").startswith("application/json"): self.json_dict = json.loads(self.request.body) else: self.json_dict = None def post(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value)) def put(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value))
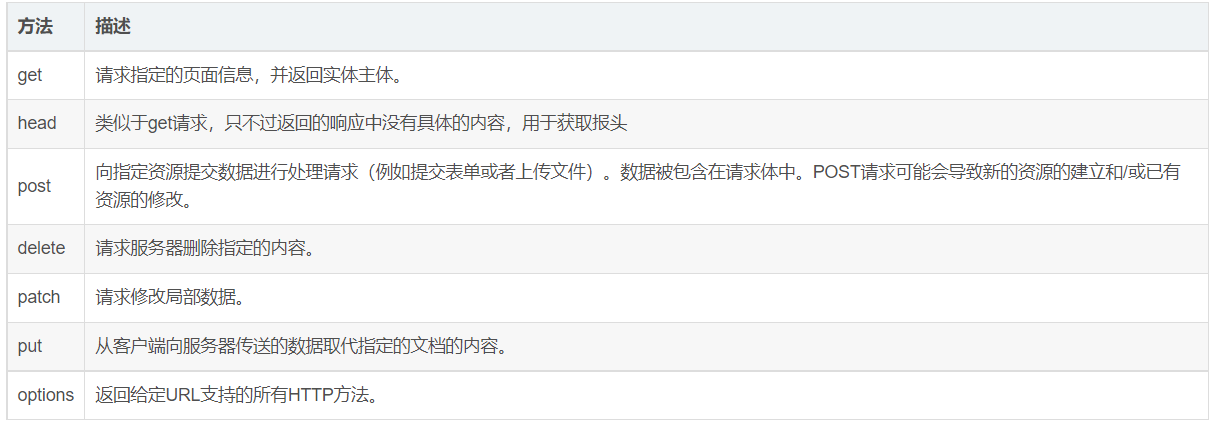
HTTP方法
on_finish()
在请求处理结束后调用,即在调用HTTP方法后调用。通常该方法用来进行资源清理释放或处理日志等
注意:请尽量不要在此方法中进行响应输出
set_default_headers()
write_error()
调用顺序
测试代码
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options from tornado.web import RequestHandler class IndexHandler(RequestHandler): def initialize(self): print("调用了initialize()") def prepare(self): print("调用了prepare()") def set_default_headers(self): print("调用了set_default_headers()") def write_error(self, status_code, **kwargs): print("调用了write_error()") def get(self): print("调用了get()") def post(self): print("调用了post()") self.send_error(200) # 注意此出抛出了错误 def on_finish(self): print("调用了on_finish()") if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), ], debug=True) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(8000) tornado.ioloop.IOLoop.current().start()
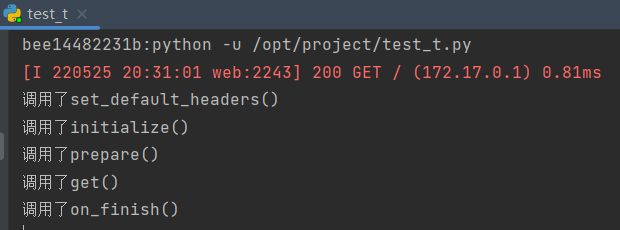
在正常情况未抛出错误时
调用顺序为:
在有错误抛出时
调用顺序为:
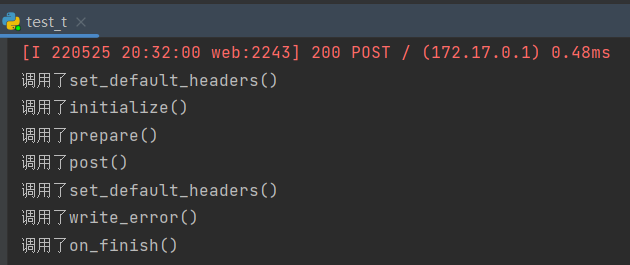
可看到 set_default_headers initialize prepare 这仨是雷打不动的最先执行
而 on_finish 必定最后执行, set_default_headers 在出错的情况下回在 业务函数和 write_error 间在执行一次
Cookie 安全
Cookie是存储在客户端浏览器中的,很容易被篡改
Tornado提供了一种对Cookie进行简易加密签名的方法来防止Cookie被恶意篡改
使用安全Cookie需要为应用配置一个用来给Cookie进行混淆的秘钥cookie_secret
将其传递给Application的构造函数使其生效
写入配置
app = tornado.web.Application( [(r"/", IndexHandler),], cookie_secret = "2hcicVu+TqShDpfsjMWQLZ0Mkq5NPEWSk9fi0zsSt3A=" )
使用 cookie
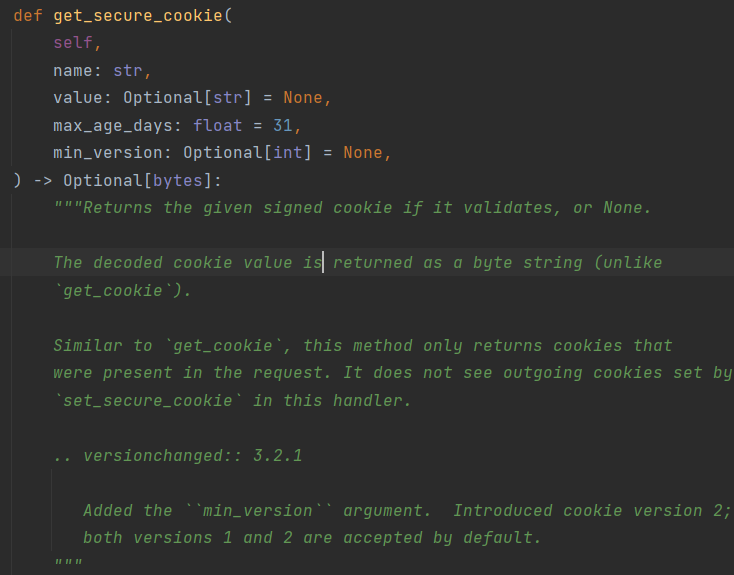
get_secure_cookie(name, value=None, max_age_days=31)
获取 cookie
name 要获取的 cookie 名
value 获取不到的默认值, 默认位 None
max_age_day 过滤安全 cookie 的时间戳
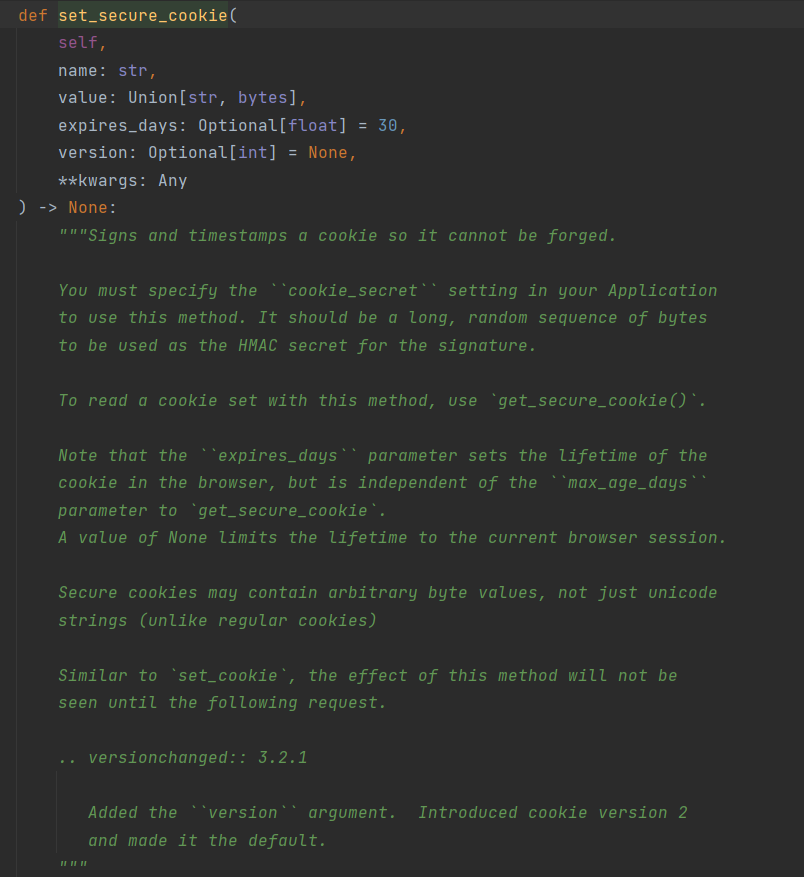
set_secure_cookie(name, value, expires_days=30)
name 要获取的 cookie 名
value 获取不到的默认值, 默认位 None
expires_days 设置浏览器中cookie的有效期
测试代码
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.web import RequestHandler class IndexHandler(RequestHandler): def get(self): cookie = self.get_secure_cookie("count") count = int(cookie) + 1 if cookie else 1 self.set_secure_cookie("count", str(count)) self.write( '<html><head><title>Cookie计数器</title></head>' '<body><h1>您已访问本页%d次。</h1>' % count + '</body></html>' ) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), ], debug=True, cookie_secret="2hcicVu+TqShDpfsjMWQLZ0Mkq5NPEWSk9fi0zsSt3A=") http_server = tornado.httpserver.HTTPServer(app) http_server.listen(8000) tornado.ioloop.IOLoop.current().start()
对比明文的保存。 这种机制的保存可以一定程度的具备安全性, 破解难度较高一些

如下是保存的 cookie 的具体内容
%222%7C1%3A0%7C10%3A1653532913%7C6%3A_count%7C4%3AMQ%3D%3D%7Cd22d828acb45404d252e2e9df76d56cf12e87ecc4d9c371e3a41c00a6d9b0f3b%22
其中的组成部分如下

用户验证
authenticated 装饰器
此装饰器装饰后的视图需要用户登录后才可以访问
class ProfileHandler(RequestHandler): @tornado.web.authenticated def get(self): self.write("这是我的个人主页。")
此装饰器是对于用户逻辑的验证则是通过 get_current_user 函数来实现
此函数若返回 True 或者 任何有意义的数据则表示验证通过
若返回 None 或者 False 则返回到 login_url ( 因此需要设定 login_url )
演示代码
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.web import RequestHandler class LoginHandler(RequestHandler): def get(self): self.write("login ~~~~。") class ProfileHandler(RequestHandler): def get_current_user(self): """在此完成用户的认证逻辑""" return True @tornado.web.authenticated def get(self): self.write("这是我的个人主页。") if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", ProfileHandler), (r"/login", LoginHandler), ], debug=True, login_url="/login", ) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(8000) tornado.ioloop.IOLoop.current().start()
听过调整 get_current_user 的返回值, 即可以实现登录态的判定, 以实现测试效果
异步处理
本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/16310371.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2019-05-25 Python - 排序( 插入, 冒泡, 快速, 二分 )