机器学习 - 算法 - 贝叶斯算法概述 , 拼写检查器实现
贝叶斯公式原理概述
贝叶斯要解决的问题
正向概率

逆向概率

公式推导 - 男女裤子问题

概率

求解




即显示意义就是 欲求解 B 条件下 A 发生的概率,
可以转换成 用 A 条件下 B 发生的概率 和 A , B 各自发生的概率 进行计算
这样可以通过已知的条件组合为想要求解的概率
现实实例 - 拼写纠错


P(h) 表示某一词在总数据库的出现占比即词频 - 先验概率 , 拿到此数据, 是可以得知他的频率的
P(D|h) 表示在 h 的情况下, 转换成 D 成功的概率 - 即猜测生成观测到数据的可能性大小
这个的变量也是存在一定的衡量标准, 也是一个可以考量出来的数据
比如 计划输入 the 结果输成了 thr , 是因为 r 和 e 键盘位置很近, 所以输错可能性很大
比如 计划输入 the 结果输成了 then, 是因为 then 顺手就打出来了, 输错的可能性也很大
再比如 计划输入 the 却输成了 there 这就比较不现实, 存在很大的编辑距离偏差, 所以这种可能性的衡量就会很小
P(D) 表示用户输入一个任意单词是 D 的概率 - 这个变量之后对于每个 h 的来说都是一样的因此可以约分掉了

模型比较理论

最大似然
比如现在投掷硬币, 只投掷一次, 结果为 正面
于是我们根据现有的测试结果统计投掷结果 正面 100%
因此我们有理由预测下一次的结果是 100% 的正面, 这就是最大似然的想法
奥卡姆剃刀
而奥卡姆剃刀的想法是 先验概率对结果有较大的权重
这里有这样的呀一个实例
空间中存在多个点, 近似的构成了一个直线, 但是不是精准的直线
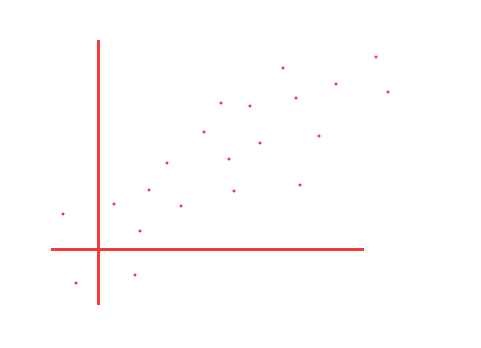
我们想对这些点进行拟合
可以直接使用直线
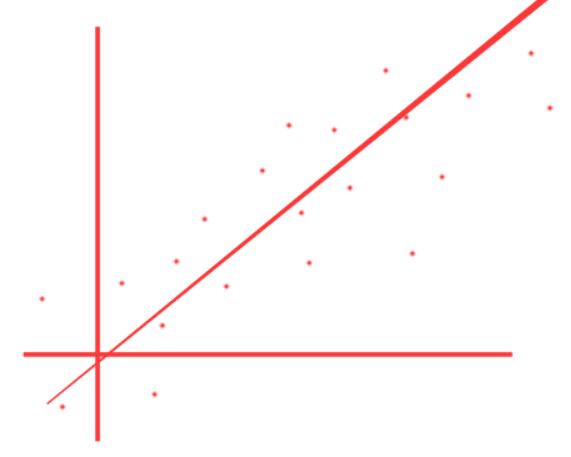
也可以使用二阶多项式

或者三阶多项式或者更高阶多项式
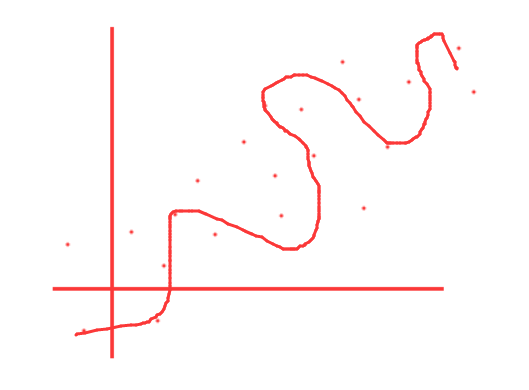
当然如果使用了 N-1 阶多项式必然可以完美拟合 N 个数据点
但是这样的话到底哪个更好呢 ?
奥卡姆剃刀的想法是按照先验数据中 - 在生活中我们基本上很少简单那么复杂的高阶多项式
而且越是高阶的多项式就越小可能性
因此在选择的时候回优先选择低阶多项式比过高阶多项式
实例 - 垃圾优先过滤

P(D) 在正常邮件和垃圾邮件的判断中都有, 相同变量没有什么影响, 忽略即可
先验概率

P(h+) , P(h-) 表示先验概率, 大白话来说就是 一万封邮件中是正常和垃圾的概率, 这个是已知或者可求的概率
条件概率

P(D|h+) , P(D|h-) 表示, 当前是 正常 / 垃圾 邮件下, 这个邮件里面含有这些词的概率
条件概率优化
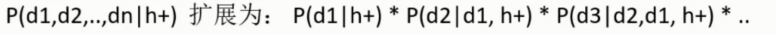
但是原始问题比较严苛, 不能将 D 完全作为考量, 因为按照这个判定是都含有情况下的判定, 实际情况不一定包含所有的词才算垃圾邮件
大致都有或者存在几个核心的都能算是垃圾邮件的, 因此对这个条件进行展开处理
展开的含义就是 在是正常 / 垃圾邮件的前提下, 包含 d1 的概率 * 在包含 d1 的情况下 又包含 d2 * 在包含 d1. d2 的情况下 又包含 d3 .....
很明显这个的拓展虽然合理但是瞬间麻烦了不少, 因此需要进行简化 - 朴素贝叶斯处理 (假设特征独立)
因此简化成了 P(d1|h+) * P(d2|h+) * P(d3|h+) ....
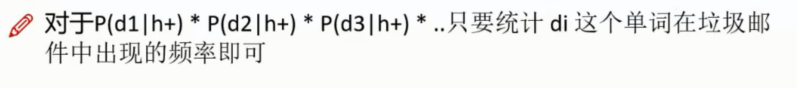
对于特定的 di 这个词出现在 正常 / 垃圾 邮件中的概率这个也是可以预先得到或者可求的 即 : 10000 个 正常 / 垃圾邮件出现 di 这个词的频率
最终
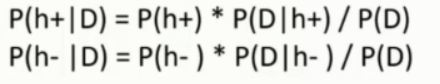
再回到这个最初的公式上, 可见所有的部分都是可以求出, 因此可以求解了
Ps:
这里使用了朴素贝叶斯消除了彼此特征的影响, 必然会是对最终结果造成一定的影响的
但是考虑到计算的程度以及对结果的影响, 也算是一定的妥协下最合理的选择而已
贝叶斯实例 - 拼写检查器
求解:argmaxc P(c|w) -> argmaxc P(w|c) P(c) / P(w)
P(c) 文章中出现一个正确拼写词 c 的概率, 也就是说, 在英语文章中, c 出现的概率有多大
P(w|c) 在用户想键入 c 的情况下敲成 w 的概率. 因为这个是代表用户会以多大的概率把 c 敲错成 w
argmaxc 用来枚举所有可能的 c 并且选取概率最大的
代码
语料库读取 先验概率计算
# 把语料中的单词全部抽取出来, 转成小写, 并且去除单词中间的特殊符号 def words(text):
return re.findall('[a-z]+', text.lower()) def train(features): model = collections.defaultdict(lambda: 1) for f in features: model[f] += 1 return model NWORDS = train(words(open('big.txt').read()))
要是遇到我们从来没有过见过的新词怎么办. 假如说一个词拼写完全正确, 但是语料库中没有包含这个词, 从而这个词也永远不会出现在训练集中. 于是, 我们就要返回出现这个词的概率是0. 这个情况不太妙, 因为概率为0这个代表了这个事件绝对不可能发生, 而在我们的概率模型中, 我们期望用一个很小的概率来代表这种情况. lambda: 1
NWORDS
计算出的先验概率


defaultdict(<function __main__.train.<locals>.<lambda>>, {'counterorders': 2, 'ureters': 3, 'displeasure': 9, 'omitted': 10, 'sparrow': 5, 'tubercle': 66, 'curse': 7, 'pauncefote': 2, 'updated': 5, 'gloomier': 4, 'foremost': 17, 'wabash': 2, 'anarchists': 4, 'intermediacy': 2, 'threadbare': 2, 'endeavouring': 9, 'freeholders': 11, 'irreproachably': 3, 'ignominious': 3, 'illuminated': 9, 'galitsyn': 2, 'struthers': 3, 'shuya': 2, 'futile': 16, 'each': 412, 'district': 38, 'acquiesced': 2, 'staircase': 14, 'shamelessly': 2, 'doubter': 2, 'plumage': 3, 'worming': 2, 'militiamen': 30, 'tombstones': 2, 'presupposable': 2, 'notable': 6, 'louise': 5, 'overtook': 17, 'abstraction': 8, 'displeased': 20, 'ranchmen': 2, 'instal': 2, 'kashmir': 3, 'nay': 4, 'wired': 5, 'pencil': 11, 'mustache': 46, 'breast': 87, 'dioxide': 9, 'disappointments': 4, 'impassive': 6, 'though': 651, 'floridas': 7, 'torban': 2, 'combine': 11, 'yawning': 7, 'homeless': 4, 'cinema': 2, 'subjects': 68, 'rib': 9, 'bin': 3, 'cylinders': 18, 'bijou': 2, 'acted': 38, 'accepted': 88, 'attainment': 11, 'mustered': 8, 'audacious': 2, 'respectable': 15, 'bilateral': 10, 'coraco': 2, 'stuffs': 2, 'reheat': 2, 'roberts': 3, 'trenton': 6, 'sharpening': 5, 'component': 6, 'pat': 4, 'animation': 32, 'coincidently': 5, 'cy': 2, 'smoker': 2, 'manes': 3, 'adelaide': 2, 'prayer': 43, 'industries': 65, 'advantageously': 5, 'dissolute': 3, 'tendon': 130, 'barton': 2, 'ablest': 2, 'episode': 12, 'barges': 3, 'sipping': 4, 'inoperative': 2, 'soap': 8, 'padlocks': 2, 'vagaries': 2, 'potemkins': 3, 'blackguard': 5, 'smashed': 11, 'bursitis': 17, 'goes': 61, 'prefix': 3, 'shops': 23, 'basketful': 2, 'stepfather': 22, 'veil': 17, 'adorers': 2, 'overhauled': 6, 'liquors': 3, 'bottoms': 3, 'plastun': 2, 'surest': 4, 'carlton': 5, 'friedland': 6, 'alice': 14, 'unhealthy': 15, 'cannula': 9, 'eleven': 22, 'persuasions': 3, 'cawolla': 2, 'elephants': 2, 'mechanicks': 2, 'kitten': 8, 'promotes': 2, 'venae': 2, 'matt': 2, 'private': 94, 'essential': 93, 'creating': 25, 'exclaiming': 5, 'extent': 100, 'oxidising': 2, 'dessicans': 3, 'uplands': 4, 'tops': 4, 'jerky': 6, 'irregularity': 6, 'recruitment': 3, 'fringes': 17, 'shopkeepers': 7, 'tendencies': 16, 'unconditionally': 3, 'brandy': 16, 'camberwell': 3, 'statue': 9, 'metatarsal': 9, 'measurement': 3, 'enclosures': 2, 'suspecting': 4, 'noses': 7, 'standard': 55, 'inspection': 19, 'enterprising': 6, 'freak': 4, 'liberating': 2, 'ordeal': 3, 'pancras': 2, 'luxury': 9, 'livery': 3, 'anconeus': 2, 'polypus': 4, 'leapt': 3, 'liberally': 2, 'finish': 50, 'previously': 56, 'mccarthy': 38, 'mallet': 6, 'bluestocking': 3, 'conveyance': 8, 'transformer': 2, 'compel': 10, 'blasphemies': 3, 'suggest': 25, 'shares': 4, 'dishonoured': 4, 'hen': 7, 'vols': 28, 'narcotisation': 2, 'speranski': 80, 'cherished': 15, 'overcoat': 27, 'malbrook': 2, 'nephroma': 2, 'habeus': 2, 'coward': 9, 'widower': 5, 'extremely': 52, 'resembling': 53, 'understood': 223, 'impetus': 10, 'actinomyces': 10, 'eosinophile': 4, 'pronounce': 10, 'arrangements': 30, 'inevitably': 33, 'hochgeboren': 2, 'crusted': 3, 'weeks': 118, 'slightest': 26, 'fords': 2, 'stimulatingly': 2, 'economically': 3, 'thrice': 9, 'peg': 5, 'adventurous': 4, 'mountainous': 3, 'potch': 2, 'adults': 27, 'kindled': 11, 'have': 3494, 'sedate': 3, 'democrats': 94, 'vaginitis': 2, 'foo': 2, 'headgear': 2, 'gape': 8, 'reassigned': 2, 'incompletely': 2, 'pharmacopoeial': 2, 'feelings': 79, 'phone': 3, 'anger': 60, 'improvisations': 2, 'dethrone': 2, 'toothed': 2, 'sweetish': 2, 'tack': 4, 'unwinding': 3, 'pediculosis': 2, 'overfed': 2, 'rabble': 8, 'opsonins': 4, 'ver': 3, 'postures': 3, 'entertainment': 8, 'unkind': 5, 'lightest': 3, 'undergone': 10, 'persons': 120, 'mention': 47, 'iodism': 2, 'sterne': 2, 'kolocha': 17, 'wecollect': 2, 'asked': 778, 'augury': 2, 'uhlans': 29, 'fist': 9, 'winner': 3, 'praise': 17, 'legislative': 32, 'greediness': 3, 'resembled': 9, 'expense': 34, 'despotic': 2, 'storage': 4, 'league': 54, 'granular': 8, 'differed': 11, 'enlistment': 2, 'authorizing': 17, 'remembers': 7, 'outlays': 4, 'malignant': 89, 'allowed': 87, 'rang': 30, 'wing': 33, 'sped': 2, 'map': 39, 'might': 537, 'disrupting': 2, 'pyrexia': 7, 'besprinkled': 3, 'reddaway': 3, 'intrusions': 2, 'respectively': 11, 'ilagin': 26, 'portray': 2, 'shenkii': 2, 'drilled': 5, 'devilish': 4, 'abate': 6, 'trophic': 21, 'soil': 94, 'smelters': 3, 'people': 900, 'minerals': 9, 'site': 33, 'ceremony': 18, 'rostov': 777, 'occupation': 53, 'whale': 4, 'definitely': 36, 'steam': 31, 'turbinate': 2, 'recollection': 24, 'sports': 3, 'apportioned': 12, 'ripon': 2, 'representations': 4, 'calcanean': 3, 'demonetized': 2, 'cloaks': 10, 'river': 113, 'industrial': 99, 'foreman': 6, 'girt': 4, 'close': 220, 'warne': 2, 'blubberers': 2, 'disruption': 5, 'diligently': 4, 'blamelessly': 2, 'cornwall': 3, 'edinburgh': 26, 'denouncing': 5, 'sasha': 3, 'zeal': 26, 'shouted': 255, 'powerlessness': 2, 'helpless': 23, 'cheapest': 3, 'homely': 9, 'pyosalpynx': 2, 'poorhouse': 2, 'adhesive': 4, 'lumber': 15, 'cawing': 3, 'splashed': 7, 'interphalangeal': 3, 'maintenance': 11, 'pervade': 2, 'beads': 5, 'scarcity': 5, 'anticipate': 5, 'orthodox': 10, 'sponge': 8, 'infer': 4, 'inverted': 4, 'bleak': 5, 'main': 110, 'doddering': 2, 'ligation': 53, 'shiloh': 3, 'haitian': 2, 'hindrance': 12, 'amputate': 5, 'obstructed': 11, 'extensively': 9, 'raised': 213, 'visualized': 2, 'showed': 150, 'awaits': 8, 'specified': 10, 'gush': 2, 'partially': 11, 'calibres': 2, 'kettles': 2, 'easy': 123, 'confirming': 4, 'hordes': 4, 'saved': 52, 'sneered': 3, 'peevishly': 2, 'unexpectedly': 58, 'handedness': 2, 'gigantic': 24, 'bouts': 3, 'hoosier': 2, 'plural': 4, 'disuse': 6, 'flora': 10, 'wriggles': 2, 'reproving': 2, 'unrepaired': 2, 'repose': 8, 'baltic': 2, 'whistle': 29, 'barbarous': 3, 'warp': 3, 'vozdvizhenka': 8, 'intubation': 7, 'dreaminess': 2, 'creek': 4, 'suffrage': 116, 'gay': 36, 'bagovut': 3, 'dropping': 19, 'poultry': 3, 'sentiments': 15, 'bivouacs': 4, 'pobox': 5, 'fuller': 13, 'bombard': 2, 'vanishes': 4, 'independent': 74, 'card': 31, 'sheen': 2, 'descends': 3, 'cerebritis': 2, 'sparrows': 2, 'stab': 9, 'coverlet': 2, 'footmarks': 4, 'homicidal': 3, 'frustration': 2, 'sicca': 4, 'slowly': 134, 'stifling': 3, 'poetry': 11, 'inadvertent': 2, 'faints': 2, 'tudor': 2, 'hancocks': 2, 'postulated': 2, 'delegate': 10, 'ratify': 8, 'rag': 7, 'yankovo': 4, 'staked': 6, 'leprosy': 5, 'cheyenne': 2, 'verbally': 2, 're': 190, 'pedunculated': 14, 'splendidly': 12, 'troubled': 18, 'healed': 17, 'tuning': 2, 'farmer': 28, 'bourbon': 3, 'differently': 26, 'descry': 2, 'filter': 5, 'sob': 20, 'newfoundland': 2, 'flattered': 18, 'lotions': 9, 'refinements': 6, 'overtake': 13, 'offerings': 3, 'kent': 6, 'pimple': 2, 'carousals': 4, 'intrigue': 12, 'salut': 2, 'pliant': 2, 'zum': 2, 'saw': 600, 'load': 9, 'engineers': 5, 'imports': 12, 'indifference': 27, 'are': 3631, 'wringing': 3, 'kidney': 22, 'nun': 4, 'wool': 43, 'utero': 2, 'tag': 3, 'hamlet': 2, 'attain': 51, 'ingested': 2, 'longitudinal': 6, 'detestable': 4, 'inspector': 32, 'hernia': 14, 'circulates': 2, 'adieu': 7, 'annulment': 4, 'tumour': 224, 'elect': 13, 'sidorov': 5, 'eats': 9, 'bond': 27, 'messages': 7, 'surgeon': 44, 'dissecting': 6, 'clarifying': 2, 'stout': 63, 'wrung': 18, 'sincere': 23, 'reverie': 8, 'stampede': 3, 'vindicate': 2, 'cartload': 2, 'semiopen': 2, 'gainful': 2, 'noting': 11, 'marsh': 4, 'interfering': 20, 'sevres': 3, 'charmee': 2, 'cherish': 7, 'beseech': 4, 'transylvania': 4, 'new': 1212, 'weason': 2, 'frontiersmen': 6, 'feverish': 25, 'establish': 46, 'grassy': 2, 'assent': 10, 'muscularly': 4, 'rire': 2, 'mcmaster': 11, 'pineapples': 3, 'maritime': 6, 'debauchery': 6, 'disliked': 21, 'relationships': 3, 'swarmed': 5, 'surpassed': 4, 'discernible': 4, 'thyreoid': 22, 'paddle': 4, 'zoology': 4, 'tenn': 4, 'wood': 89, 'persuasiveness': 3, 'bashful': 3, 'uterine': 12, 'convention': 152, 'unshapely': 2, 'homes': 36, 'bicipital': 3, 'admirable': 15, 'nightshirt': 2, 'fibrin': 17, 'bartenstein': 3, 'guess': 18, 'circlet': 2, 'adventitious': 9, 'indemnify': 6, 'typewriting': 5, 'expunging': 2, 'quand': 6, 'exactions': 2, 'receiving': 55, 'incur': 3, 'giants': 3, 'tearing': 23, 'probing': 4, 'devise': 10, 'hearth': 2, 'placental': 2, 'hammering': 6, 'defeating': 3, 'womanly': 8, 'jewellery': 3, 'kuragins': 4, 'target': 6, 'stevedore': 2, 'safest': 3, 'sounder': 3, 'likes': 9, 'appointments': 12, 'speech': 83, 'quaker': 3, 'antonov': 2, 'proofs': 15, 'boasting': 6, 'wegiment': 3, 'disciplined': 4, 'occupancy': 2, 'flare': 2, 'copenhagen': 3, 'zenger': 4, 'battalions': 27, 'truth': 116, 'research': 37, 'recurvatum': 2, 'notion': 17, 'dishonour': 2, 'glittered': 17, 'kittenish': 2, 'handed': 81, 'acquiescence': 2, 'waggled': 2, 'forged': 5, 'unjust': 11, 'callous': 13, 'mantles': 2, 'election': 120, 'drummed': 2, 'salve': 2, 'agrees': 3, 'discharging': 5, 'cannons': 2, 'impure': 3, 'probable': 28, 'administration': 118, 'considerable': 174, 'forwards': 19, 'waterloo': 10, 'flail': 5, 'claiming': 7, 'phalanges': 12, 'bondage': 16, 'pelageya': 17, 'bigger': 8, 'southern': 197, 'perch': 5, 'enriched': 4, 'metaphysis': 3, 'protection': 64, 'factotum': 2, 'cavalryman': 6, 'radiated': 6, 'cheerfully': 14, 'solid': 42, 'vines': 2, 'scarves': 4, 'quick': 82, 'notabilities': 4, 'him': 5231, 'sixteenth': 12, 'ignoring': 2, 'deserters': 2, 'protege': 5, 'indulgence': 10, 'supreme': 75, 'closes': 7, 'shilling': 5, 'footing': 16, 'mission': 35, 'madame': 44, 'dissatisfied': 35, 'signatures': 4, 'helps': 6, 'garlic': 2, 'wart': 6, 'won': 202, 'overlooked': 14, 'lanfrey': 2, 'dulness': 2, 'unnatural': 38, 'supplier': 3, 'harassed': 4, 'hare': 37, 'slide': 5, 'necessitates': 6, 'conceived': 8, 'mode': 19, 'chant': 2, 'packing': 35, 'tentacles': 2, 'liberality': 2, 'phantasm': 2, 'gloat': 3, 'promptitude': 2, 'merchants': 55, 'whatnots': 2, 'spirited': 13, 'rupia': 5, 'succumbs': 2, 'fondest': 3, 'rusty': 5, 'strapped': 2, 'looking': 490, 'numerical': 6, 'jaws': 19, 'mann': 2, 'smelter': 2, 'becher': 4, 'comprehensive': 5, 'vessel': 138, 'code': 14, 'twopence': 3, 'semilunar': 9, 'elected': 45, 'tone': 167, 'epithelium': 56, 'steve': 2, 'pinckney': 4, 'knapsack': 8, 'kneeling': 9, 'strand': 6, 'solitude': 19, 'gentlemanly': 2, 'thoughts': 126, 'castanet': 2, 'bushy': 10, 'descried': 4, 'aponeurotic': 2, 'surrenders': 2, 'ordered': 149, 'emancipation': 24, 'alley': 6, 'blazers': 3, 'servants': 89, 'rests': 18, 'tooth': 28, 'risks': 15, 'yoke': 6, 'inflammation': 94, 'blonde': 10, 'album': 6, 'duc': 12, 'thorns': 5, 'planter': 19, 'log': 21, 'swarm': 8, 'trocar': 4, 'injured': 56, 'liquor': 14, 'perforations': 7, 'censuring': 2, 'contracture': 29, 'informer': 2, 'switzerland': 9, 'ponies': 2, 'glass': 117, 'burdensome': 5, 'security': 22, 'bitch': 13, 'bacillary': 5, 'transmuted': 2, 'atrocious': 3, 'elects': 2, 'but': 5654, 'muir': 3, 'nikita': 5, 'muddled': 4, 'lifts': 3, 'impresses': 2, 'slim': 14, 'maksim': 2, 'garrulously': 2, 'utterances': 2, 'stammered': 6, 'midsummer': 2, 'trousseau': 5, 'hogs': 3, 'metacarpals': 3, 'blindfold': 5, 'nonmoral': 2, 'moonlight': 19, 'waddling': 6, 'pointing': 89, 'differentiating': 4, 'silly': 14, 'ingest': 2, 'imply': 13, 'enlarges': 3, 'cart': 57, 'differ': 16, 'inflamed': 54, 'bolding': 2, 'shave': 4, 'adroitly': 4, 'served': 64, 'straining': 19, 'fall': 125, 'autocrats': 3, 'unreasonably': 2, 'salter': 2, 'ramshackle': 2, 'eminent': 13, 'molle': 2, 'pained': 8, 'loyal': 21, 'chalk': 14, 'willard': 3, 'idleness': 13, 'canceled': 4, 'inoculation': 23, 'sounding': 7, 'loopholes': 2, 'initial': 20, 'vicar': 3, 'oklahoma': 16, 'precautions': 15, 'commensurable': 2, 'batch': 2, 'push': 20, 'sublimed': 2, 'warned': 19, 'meuse': 4, 'snoring': 7, 'manner': 136, 'this': 4064, 'household': 56, 'millionaires': 6, 'duodenum': 3, 'dixon': 2, 'liberated': 11, 'arrangement': 36, 'soulless': 2, 'reserved': 16, 'essen': 2, 'whirlpool': 2, 'duport': 9, 'hellish': 4, 'engaged': 88, 'apropos': 2, 'retuned': 2, 'cancellation': 2, 'crack': 21, 'morrant': 2, 'pleasurable': 2, 'sunk': 28, 'indorsed': 7, 'wanted': 214, 'integration': 3, 'translations': 2, 'framework': 24, 'skill': 35, 'upper': 131, 'mufti': 2, 'softened': 29, 'callosity': 5, 'thrombosis': 40, 'septum': 4, 'sont': 3, 'sheaf': 2, 'redistribution': 6, 'clymer': 2, 'fatal': 64, 'laid': 187, 'nares': 2, 'archway': 2, 'deterred': 2, 'oscillates': 2, 'ineffective': 2, 'vacant': 11, 'confide': 7, 'nominal': 9, 'hiram': 2, 'resected': 12, 'unwanted': 2, 'pattern': 8, 'cicatricial': 42, 'bowl': 7, 'nor': 281, 'wobbly': 3, 'sarcomas': 9, 'solder': 2, 'laceration': 10, 'illustrating': 6, 'psammoma': 3, 'stuck': 21, 'perversion': 2, 'jewels': 6, 'country': 424, 'enforce': 30, 'battlefields': 2, 'speechless': 2, 'ruin': 49, 'grassland': 2, 'mistrusting': 2, 'bench': 27, 'scurrying': 2, 'rhetor': 25, 'morton': 2, 'suggestiveness': 2, 'remorseless': 2, 'divert': 7, 'melyukovs': 8, 'obviates': 2, 'cooperative': 10, 'started': 97, 'employe': 3, 'perfidiousness': 2, 'replied': 321, 'imagined': 49, 'marvel': 2, 'pitiable': 8, 'genteel': 2, 'unlocked': 9, 'independence': 152, 'appealed': 14, 'flexible': 6, 'xxiv': 9, 'authority': 101, 'frilled': 2, 'thoroughbred': 6, 'accuser': 2, 'hesitating': 17, 'pork': 4, 'voltaires': 2, 'bengal': 3, 'tends': 49, 'wastage': 2, 'shrill': 14, 'profunda': 4, 'thanksgiving': 7, 'enclose': 2, 'seedy': 3, 'furs': 11, 'splash': 5, 'supplementary': 4, 'sedately': 3, 'certainly': 120, 'puppet': 4, 'injustice': 14, 'lanolin': 4, 'thicknesses': 2, 'excuses': 7, 'faces': 163, 'fourteenth': 28, 'trimming': 2, 'prick': 6, 'economic': 121, 'stands': 20, 'programming': 2, 'princes': 12, 'lottery': 2, 'exsiccated': 2, 'parceled': 2, 'musculo': 9, 'standstill': 3, 'consolation': 19, 'uncle': 136, 'federalism': 2, 'intravenous': 4, 'assumption': 32, 'doors': 48, 'lisa': 2, 'disregard': 7, 'appendix': 12, 'myoma': 9, 'cost': 66, 'parrot': 6, 'manoeuvre': 2, 'achtung': 2, 'acorn': 3, 'aggrieved': 4, 'cutlery': 2, 'glorious': 12, 'rotten': 9, 'denoted': 2, 'muster': 4, 'hug': 2, 'eccentricity': 3, 'susquehanna': 4, 'partake': 4, 'nicely': 10, 'thing': 304, 'wages': 51, 'dislike': 10, 'beams': 10, 'spree': 3, 'antagonizing': 2, 'advises': 4, 'snuffling': 2, 'rods': 6, 'borisov': 2, 'mayor': 16, 'mathematics': 12, 'invent': 11, 'teaching': 19, 'girdle': 4, 'averting': 4, 'elijah': 2, 'platelets': 2, 'uvula': 2, 'mumbling': 5, 'retreat': 95, 'fwashing': 2, 'bar': 26, 'scudding': 2, 'nowadays': 19, 'loftiness': 3, 'ceded': 9, 'delirium': 35, 'wiring': 3, 'centre': 51, 'frightfully': 2, 'wag': 6, 'sockets': 2, 'fluctuates': 2, 'concealment': 4, 'intima': 11, 'burnt': 9, 'tiding': 3, 'osteomas': 4, 'tug': 5, 'vis': 2, 'fabrication': 2, 'powers': 150, 'sweeps': 2, 'supervene': 7, 'meal': 16, 'briskly': 20, 'reinforce': 3, 'devriez': 2, 'youngster': 5, 'coast': 41, 'sameness': 2, 'about': 1498, 'whither': 9, 'tolstoy': 14, 'certain': 362, 'paunch': 2, 'laurel': 4, 'stamping': 4, 'incorporate': 4, ...})
编辑距离
两个词之间的编辑距离定义为使用了几次插入(在词中插入一个单字母), 删除(删除一个单字母), 交换(交换相邻两个字母), 替换(把一个字母换成另一个)的操作从一个词变到另一个词.
#返回所有与单词 w 编辑距离为 1 的集合 def edits1(word): n = len(word) return set([word[0:i]+word[i+1:] for i in range(n)] + # deletion [word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # transposition [word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # alteration [word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # insertion
与 something 编辑距离为2的单词居然达到了 114,324 个
优化:在这些编辑距离小于2的词中间, 只把那些正确的词作为候选词,只能返回 3 个单词: ‘smoothing’, ‘something’ 和 ‘soothing’
#返回所有与单词 w 编辑距离为 2 的集合 #在这些编辑距离小于2的词中间, 只把那些正确的词作为候选词 def edits2(word): return set(e2 for e1 in edits1(word) for e2 in edits1(e1))
正常来说把一个元音拼成另一个的概率要大于辅音 (因为人常常把 hello 打成 hallo 这样); 把单词的第一个字母拼错的概率会相对小, 等等.但是为了简单起见, 选择了一个简单的方法: 编辑距离为1的正确单词比编辑距离为2的优先级高, 而编辑距离为0的正确单词优先级比编辑距离为1的高.
def known(words): return set(w for w in words if w in NWORDS) #如果known(set)非空, candidate 就会选取这个集合, 而不继续计算后面的 def correct(word): candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word] return max(candidates, key=lambda w: NWORDS[w])
全部代码
import re, collections def words(text): return re.findall('[a-z]+', text.lower()) def train(features): model = collections.defaultdict(lambda: 1) for f in features: model[f] += 1 return model NWORDS = train(words(open('big.txt').read())) alphabet = 'abcdefghijklmnopqrstuvwxyz' def edits1(word): n = len(word) return set([word[0:i]+word[i+1:] for i in range(n)] + # deletion [word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # transposition [word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # alteration [word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # insertion def known_edits2(word): return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS) def known(words): return set(w for w in words if w in NWORDS) def correct(word): candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word] return max(candidates, key=lambda w: NWORDS[w])
简单测试
#appl #appla #learw #tess #morw correct('knon')
'know'
本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/11813893.html

