机器学习 - 算法 - 决策树原理 , 算法实现
决策树
概述
▒ 树模型
▨ 从根节点一步一步走到叶子节点 ( 决策 )
▨ 所有数据都会落在叶子节点, 既可以做分类也可以做回归
▒ 树的组成
▨ 根节点 - 第一个选择点
▨ 非叶子节点与分支 - 中间过程
▨ 叶子节点 - 最终的决策结果
▒ 节点
▨ 节点相当于在数据中进行切一刀 ( 切分两部分 - 左右子树 )
▨ 节点越多越好吗? -
▒ 决策树的训练和测试
▨ 训练阶段 - 从给定的训练集构造一棵树 ( 从根节开始选择特征, 如何进行特征切分 )
▨ 测试阶段 - 根据构造出来的树模型从上到下走一遍
▨ 难点 - 测试阶段较为容易, 而训练阶段并不简单
▒ 如何切分特征 ( 选择节点 )
▨ 问题 - 一个数据集中可能存在多个特征的时候, 选择那个节点特征作为根节点进行分支, 以及其他特征分支的选择顺序都是问题
▨ 目标 - 需要通过一种衡量标准, 来计算不同特征进行分支选择后的分类情况, 找出最好的那个当做根节点, 以此类推
决策树算法 - 信息增益
▒ 衡量标准 - 熵
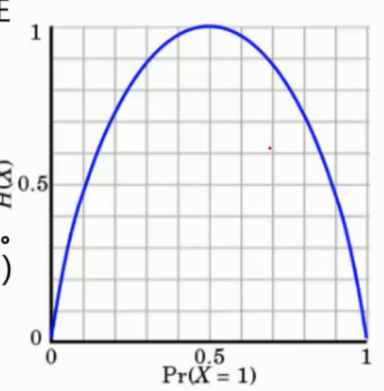
▨ 熵 - 表示随机变量的不确定性的度量 ( 简单来说就是混乱程度 )
当 p = 0 或者 p = 1 的时候, H(p) = 0, 随机变量完全没有不确定性
当 p = 0.5 时, H(p) = 1 此时,随机变量的不确定性最大
▨ 公式 - ![]()
▨ 栗子 - a = [1,1,1,2,1,2,1,1,1] , b = [1,5,6,7,5,1,6,9,8,4,5] a 的熵更底, 因为 a 的类别较少, 相对 b 就更稳定一些
▨ 信息增益 - 表示特征 X 使 Y 的不确定性减少的程度 (分类后的专一性, 希望分类后的结果同类在一起)
▒ 示例
▨ 数据 - 14 天打球情况
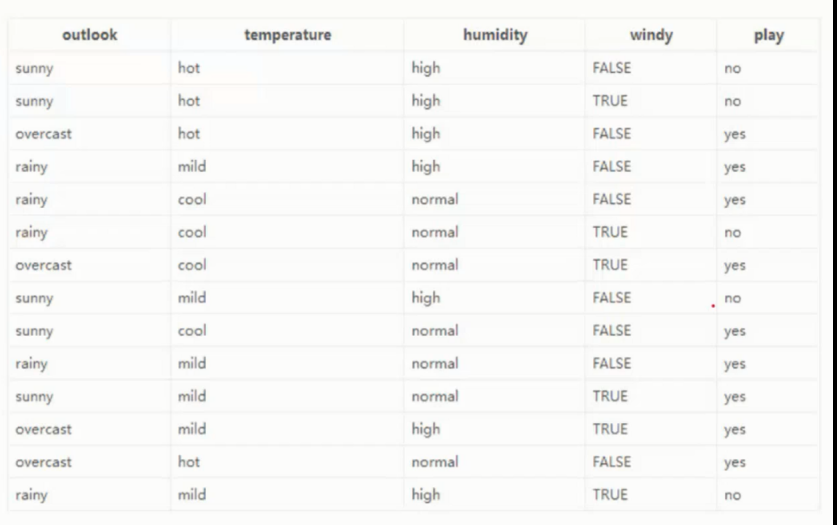
▨ 特征 - 4 种天气因素
▨目标 - 构建决策树
▨ 根节点选择
14天的记录中, 有 9 天打球, 5 天没打球, 熵为
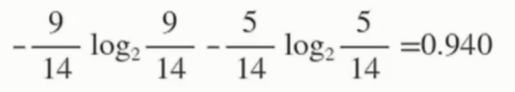
演示 - outlook 特征 - 天气
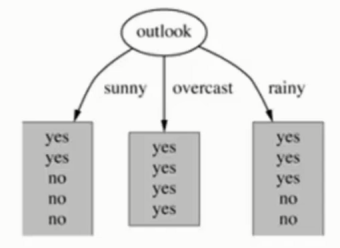
suuny 的概率是 5/14 , 熵 是 0.971
overcast 的概率是 4/14 , 熵 是 0
rainy 的概率是 5/14 , 熵 是 0.971
熵值计算 : 5/14*0.971 + 4/14*0 + 5/14*0.971 = 0.693
信息增益 : 系统的 熵值从原始的 0.940 下降到了 0.693 , 增益为 0.247
以此类推进行处理, 选出根节点然后再从剩余的特征中选择次根节点往下到仅剩最后一个特征,
▒ 总结
▨ 弊端
如 id 这样的唯一标识特征列, 会让熵值计算为 0 被视为最大信息增益 ,
但是 id 仅仅是编号标识对信息的模型无任何影响实则无效项
▨ 解决
信息增益率 - 解决信息增益问题, 考虑自身熵
GINI 系数 - ![]() ( 和熵的衡量标准类似, 计算方式不同 )
( 和熵的衡量标准类似, 计算方式不同 )
特殊处理
▒ 连续值处理
本质上就上 离散化
对序列遍历然后寻找离散点进行二分
▒ 剪枝策略
▨ 为毛
决策树拟合风险过大, 理论上可以完全分开数据, 让每个叶子节点都只有一个命中数据
训练集中的数据这样完美命中, 但是在测试集中可能会出现不适配等各种异常情况
▨ 策略
预剪枝 - 边简历决策树边进行剪枝操作 ( 更实用 )
后剪枝 - 当建立完决策树后进行剪枝操作
▨ 预剪枝
限制 深度, 叶子节点个数, 叶子节点样本数, 信息增益量等
▨ 后剪枝
通过一定的衡量标准 - 叶子越多, 损失 (C(T)) 越大
![]()
代码实现
▒ 模块引入
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd
▒ 数据集准备
▨ 下载
数据集通过 sklearn 模块内置的 房价预测数据集
from sklearn.datasets.california_housing import fetch_california_housing housing = fetch_california_housing() print(housing.DESCR)
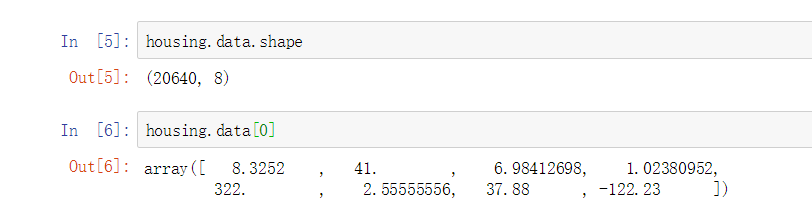
▨ 结构
▒ 模型生成
▨ 实例化模型
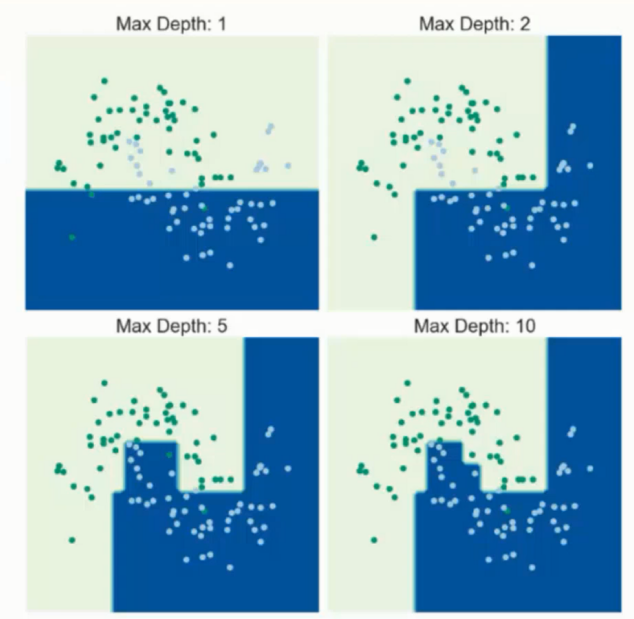
实例化树模型 , 指定最大深度, .fit 构造决策树, 传入参数分别表示 x 和 y 值
from sklearn import tree dtr = tree.DecisionTreeRegressor(max_depth = 2) dtr.fit(housing.data[:, [6, 7]], housing.target)
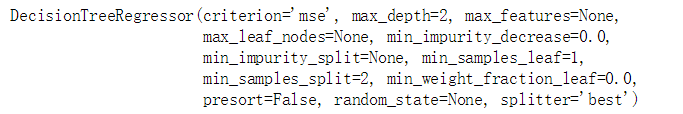
◈ criterion 评估标准 - gini / entropy
指定 gini 系数或者熵值作为评估标准
◈ splitter 特征选择 - best / random
前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候) 一般都默认是 best
◈ max_features 特征数 - None / log2 / sqrt / n (数字)
特征小于50的时候 (一般使用所有 - None , 即默认)
◈ max_depth 最大深度 - n (数字)
数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
◈ min_samples_split 最大叶子节点容量 - n (数字)
某节点的样本数少于此参数,则不继续再尝试选择最优特征来进行划分, 样本量不大时无需设置
更适用于大规模的数据集避免过拟合
◈ min_samples_leaf 最小叶子节点容量 - n (数字)
某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,样本量小无需此参数
◈ min_weight_fraction_leaf
限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0
如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就可引入样本权重
◈ max_leaf_nodes
通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
如果加了限制,算法会建立在最大叶子节点数内最优的决策树
特征不多时不考虑此参数,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
◈ class_weight
指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。
这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
◈ min_impurity_split
限制决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
◈ n_estimators:
要建立树的个数
▒ 可视化处理
▨ 下载可视化工具 graphviz 下载地址
▨ 配置环境变量, 可以手动指定, 也可以代码实现
import os os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
▨ 指定 配置参数, 其他几个参数就不需要改动了
dot_data = \ tree.export_graphviz( dtr, # 实例化的决策树 out_file = None, feature_names = housing.feature_names[6:8], # 要用到的特征 filled = True, impurity = False, rounded = True )
▨ 安装 dot 可视化工具模块 - pydotplus pip install pydotplus
▨ 可视化生成, 颜色可以随意改动, 其他不动就行了
import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) graph.get_nodes()[7].set_fillcolor("#FFF2DD") from IPython.display import Image Image(graph.create_png())
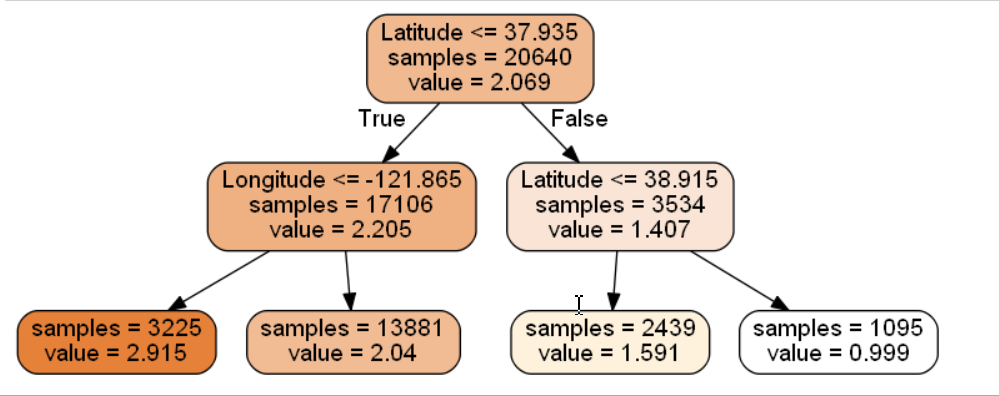
▨ 视情况可以进行保存等操作, 保存为 png 格式更加清晰一些
graph.write_png("dtr_white_background.png")
▒ 测试数据集, 参数选择
▨ 切分数据集
train_test_split 的参数传入 x , y 以及 test_size 表示测试集比例大小, random_state 指定一个值作为seed标识方便用于日后方便复现,
from sklearn.model_selection import train_test_split data_train, data_test, target_train, target_test = \ train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42) dtr = tree.DecisionTreeRegressor(random_state = 42) dtr.fit(data_train, target_train) dtr.score(data_test, target_test) # 0.637355881715626
▨ 选择参数
参数的选择是无法一上来就可以确定最优参数的, 而且参数比较多, 怎么选择组合就是个问题了
因此需要进行一定程度的组合, 本质上就是参数集之间的交叉组合的遍历比对, GridSearchCV 的原理就是于此进行的封装
传入参数, 算法 ( 算法实例 ) , 参数候选项 ( 可字典形式 ), 交叉验证次数 ( cv , 切分段数 )
from sklearn.ensemble import RandomForestRegressor rfr = RandomForestRegressor(random_state = 42) rfr.fit(data_train, target_train) rfr.score(data_test, target_test) # 0.7910601348350835
from sklearn.model_selection import GridSearchCV tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))} grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5) grid.fit(data_train, target_train) grid.cv_results_, grid.best_params_, grid.best_score_
比对结果, 测试得出 3, 100 为这组参数的最佳组合, 实际中会有更多的参数,这里仅仅选取了两组参数组进行比对
({'mean_fit_time': array([0.86073136, 4.28014984, 8.4557868 , 0.78763537, 3.94817624,
7.93624506, 0.75090647, 3.77697754, 7.65297484]),
'std_fit_time': array([0.05199331, 0.05060905, 0.08284658, 0.02222307, 0.04220675,
0.11099333, 0.0248957 , 0.05866979, 0.12467865]),
'mean_score_time': array([0.01007967, 0.05109978, 0.09502277, 0.00928087, 0.03622227,
0.07206926, 0.00758247, 0.03662882, 0.07186236]),
'std_score_time': array([0.00038016, 0.00981283, 0.011958 , 0.00261602, 0.00086917,
0.00067269, 0.00037106, 0.0076475 , 0.01476559]),
'param_min_samples_split': masked_array(data=[3, 3, 3, 6, 6, 6, 9, 9, 9],
mask=[False, False, False, False, False, False, False, False,
False],
fill_value='?',
dtype=object),
'param_n_estimators': masked_array(data=[10, 50, 100, 10, 50, 100, 10, 50, 100],
mask=[False, False, False, False, False, False, False, False,
False],
fill_value='?',
dtype=object),
'params': [{'min_samples_split': 3, 'n_estimators': 10},
{'min_samples_split': 3, 'n_estimators': 50},
{'min_samples_split': 3, 'n_estimators': 100},
{'min_samples_split': 6, 'n_estimators': 10},
{'min_samples_split': 6, 'n_estimators': 50},
{'min_samples_split': 6, 'n_estimators': 100},
{'min_samples_split': 9, 'n_estimators': 10},
{'min_samples_split': 9, 'n_estimators': 50},
{'min_samples_split': 9, 'n_estimators': 100}],
'split0_test_score': array([0.78845443, 0.81237387, 0.81156962, 0.79533209, 0.80854898,
0.80978258, 0.78914336, 0.80923727, 0.80858502]),
'split1_test_score': array([0.77014582, 0.79941449, 0.80094417, 0.78184821, 0.79978092,
0.79862554, 0.78052651, 0.7982624 , 0.79905119]),
'split2_test_score': array([0.78529369, 0.79965572, 0.80365713, 0.79374636, 0.80051057,
0.80568461, 0.78434117, 0.80059003, 0.80257161]),
'split3_test_score': array([0.79563203, 0.8098409 , 0.80998308, 0.79636012, 0.80891923,
0.8114358 , 0.79592629, 0.80754011, 0.81196788]),
'split4_test_score': array([0.781435 , 0.80752598, 0.8088186 , 0.78937079, 0.80655187,
0.80661464, 0.79724106, 0.80598448, 0.80706041]),
'mean_test_score': array([0.78419242, 0.80576255, 0.80699476, 0.79133173, 0.80486251,
0.80642881, 0.78943566, 0.80432312, 0.80584737]),
'std_test_score': array([0.00842779, 0.00531127, 0.00402334, 0.00530843, 0.00394113,
0.00442255, 0.00645683, 0.00419352, 0.00454625]),
'rank_test_score': array([9, 4, 1, 7, 5, 2, 8, 6, 3])},
{'min_samples_split': 3, 'n_estimators': 100},
0.8069947626655254)
本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/11534183.html
