4.2 进程
进程
相关概念
进程

同步/异步

阻塞/非阻塞

并发/并行

顺序执行:你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
并发:你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
并行:你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行
进程状态与调度
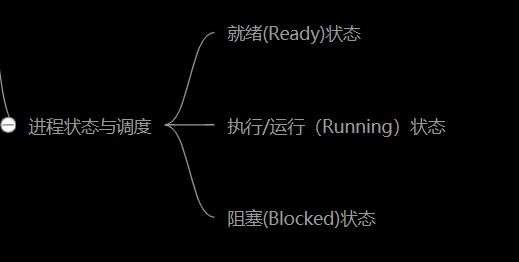
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。

多进程

创建进程

示例


from multiprocessing import Process import time def task(name): print('{} is running!'.format(name)) time.sleep(3) print('{} is done!'.format(name)) # Windows开子进程要写在__name__==__main__下 # 因为开子进程会重新加载父进程的内容 if __name__ == '__main__': # 创建一个Python中的进程对象 p = Process(target=task, args=('t1', )) # p = Process(target=task, kwargs={'name': 't1'}) p.start() # 调用操作系统接口启动一个进程执行命令 print('--- 主进程 ----')
多进程示例
from multiprocessing import Process import time def task(name): print('{} is running!'.format(name)) time.sleep(3) print('{} is done!'.format(name)) if __name__ == '__main__': for i in range(10): p = Process(target=task, args=(i, )) p.start() print('--- 主进程 ----')
继承方式创建多进程
import os from multiprocessing import Process class MyProcess(Process): def __init__(self,name): super().__init__() self.name=name def run(self): print(os.getpid()) print('%s 正在和女主播聊天' %self.name) p1=MyProcess('wupeiqi') p2=MyProcess('yuanhao') p3=MyProcess('nezha') p1.start() #start会自动调用run p2.start() # p2.run() p3.start() p1.join() p2.join() p3.join() print('主线程')
相关属性
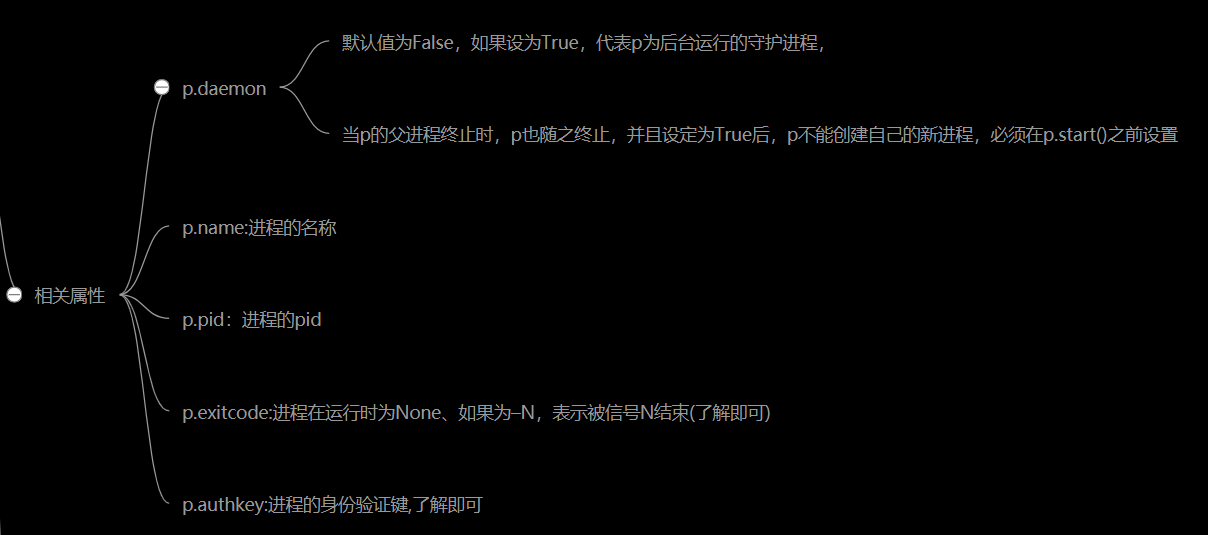
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,
daemon 守护进程示例
from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") if __name__ == '__main__': p1=Process(target=foo) p2=Process(target=bar) p1.daemon=True p1.start() p2.start() time.sleep(0.1) print("main-------") """ # 主进程结束了,守护进程随着结束,导致p1 的 end123 无法打印出来 123 456 main------- end456 """
相关方法

p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
join 的示例
from multiprocessing import Process import time def task(n): print('这是子进程:{}'.format(n)) time.sleep(n) print('子进程:{}结束了!'.format(n)) if __name__ == '__main__': start_time = time.time() p1 = Process(target=task, args=(1,)) p2 = Process(target=task, args=(2,)) p3 = Process(target=task, args=(3,)) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join() print('我是主进程') print('共耗时:{}'.format(time.time()-start_time)) """ # 未加 join 主进程不等待其他子进程程序结束便自己先行结束 我是主进程 共耗时:0.021976947784423828 这是子进程:1 这是子进程:2 这是子进程:3 子进程:1结束了! 子进程:2结束了! 子进程:3结束了! """ """ # 加 join 主进程等待其他子进程程序结束后再结束 这是子进程:1 这是子进程:2 这是子进程:3 子进程:1结束了! 子进程:2结束了! 子进程:3结束了! 我是主进程 共耗时:3.130025625228882 """
进程互斥锁
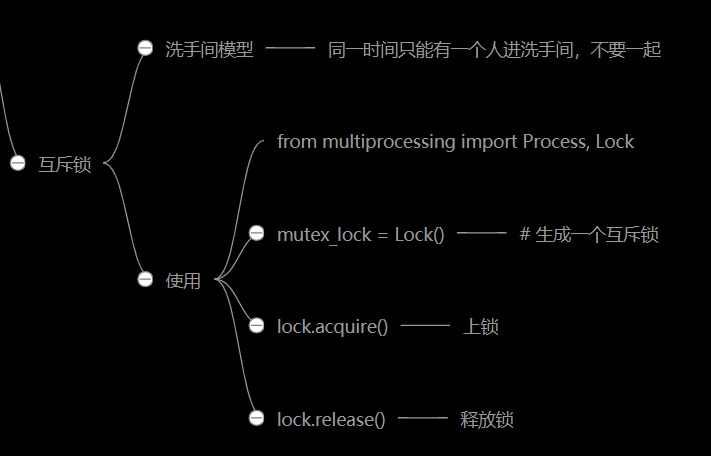
洗手间模型演示无锁导致的问题
from multiprocessing import Process import time import random def task1(): print('这是 task1 任务'.center(30, '-')) print('task1 进了洗手间') time.sleep(random.randint(1, 3)) print('task1 办事呢...') time.sleep(random.randint(1, 3)) print('task1 走出了洗手间') def task2(): print('这是 task2 任务'.center(30, '-')) print('task2 进了洗手间') time.sleep(random.randint(1, 3)) print('task2 办事呢...') time.sleep(random.randint(1, 3)) print('task2 走出了洗手间') def task3(): print('这是 task3 任务'.center(30, '-')) print('task3 进了洗手间') time.sleep(random.randint(1, 3)) print('task3 办事呢...') time.sleep(random.randint(1, 3)) print('task3 走出了洗手间') if __name__ == '__main__': p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p1.start() p2.start() p3.start() """ # 洗手间只能进一个人,尼玛你们..... ---------这是 task1 任务---------- task1 进了洗手间 ---------这是 task2 任务---------- task2 进了洗手间 ---------这是 task3 任务---------- task3 进了洗手间 task2 办事呢... task1 办事呢... task3 办事呢... task1 走出了洗手间 task2 走出了洗手间 task3 走出了洗手间 """
加锁解决示例
from multiprocessing import Process, Lock import time import random # 生成一个互斥锁 mutex_lock = Lock() def task1(lock): # 锁门 lock.acquire() print('这是 task1 任务'.center(30, '-')) print('task1 进了洗手间') time.sleep(random.randint(1, 3)) print('task1 办事呢...') time.sleep(random.randint(1, 3)) print('task1 走出了洗手间') # 释放锁 lock.release() def task2(lock): # 锁门 lock.acquire() print('这是 task2 任务'.center(30, '-')) print('task2 进了洗手间') time.sleep(random.randint(1, 3)) print('task2 办事呢...') time.sleep(random.randint(1, 3)) print('task2 走出了洗手间') # 释放锁 lock.release() def task3(lock): # 锁门 lock.acquire() print('这是 task3 任务'.center(30, '-')) print('task3 进了洗手间') time.sleep(random.randint(1, 3)) print('task3 办事呢...') time.sleep(random.randint(1, 3)) print('task3 走出了洗手间') # 释放锁 lock.release() if __name__ == '__main__': p1 = Process(target=task1, args=(mutex_lock, )) p2 = Process(target=task2, args=(mutex_lock, )) p3 = Process(target=task3, args=(mutex_lock, )) # 释放新建进程的信号,具体谁先启动无法确定 p1.start() p2.start() p3.start() """ ---------这是 task2 任务---------- task2 进了洗手间 task2 办事呢... task2 走出了洗手间 ---------这是 task1 任务---------- task1 进了洗手间 task1 办事呢... task1 走出了洗手间 ---------这是 task3 任务---------- task3 进了洗手间 task3 办事呢... task3 走出了洗手间 """
加锁的弊端

进程池
创建进程池

相关方法

p.apply(func [, args [, kwargs]])
在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 需要强调的是:此操作并不会在所有池工作进程中并执行func函数。 如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async() p.apply_async(func [, args [, kwargs[callback,]]])
在一个池工作进程中执行func(*args,**kwargs),然后返回结果
callback是可调用对象,接收输入参数。当func的结果变为可用时, 将传递给callback callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。 p.close() 关闭进程池,防止进一步操作 禁止往进程池内在添加任务(需要注意的是一定要写在close()的上方) p.join() 等待所有工作进程退出。 此方法只能在close()或teminate()之后调用
相关实例
穿行进程池实例
from multiprocessing import Pool import os,time def task(n): print('[%s] is running'%os.getpid()) time.sleep(2) print('[%s] is done'%os.getpid()) return n**2 if __name__ == '__main__': # print(os.cpu_count()) #查看cpu个数 p = Pool(4) #最大四个进程 for i in range(1,7):#开7个任务 res = p.apply(task,args=(i,)) #同步的,等着一个运行完才执行另一个 print('本次任务的结束:%s'%res) p.close()#禁止往进程池内在添加任务 p.join() #在等进程池 print('主') apply同步进程池(阻塞)(串行)
并行进程池实例
from multiprocessing import Pool import os,time def walk(n): print('task[%s] running...'%os.getpid()) time.sleep(3) return n**2 if __name__ == '__main__': p = Pool(4) res_obj_l = [] for i in range(10): res = p.apply_async(walk,args=(i,)) # print(res) #打印出来的是对象 res_obj_l.append(res) #那么现在拿到的是一个列表,怎么得到值呢?我们用个.get方法 p.close() #禁止往进程池里添加任务 p.join() # print(res_obj_l) print([obj.get() for obj in res_obj_l]) #这样就得到了
回调函数什么时候用?(回调函数在爬虫中最常用)
造数据的非常耗时 处理数据的时候不耗时带有回调函数的实例
from multiprocessing import Pool import requests import os import time def get_page(url): print('<%s> is getting [%s]' %(os.getpid(),url)) response = requests.get(url) #得到地址 time.sleep(2) print('<%s> is done [%s]'%(os.getpid(),url)) return {'url':url,'text':response.text} def parse_page(res): '''解析函数''' print('<%s> parse [%s]'%(os.getpid(),res['url'])) with open('db.txt','a') as f: parse_res = 'url:%s size:%s\n' %(res['url'],len(res['text'])) f.write(parse_res) if __name__ == '__main__': p = Pool(4) urls = [ 'https://www.baidu.com', 'http://www.openstack.org', 'https://www.python.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] for url in urls: obj = p.apply_async(get_page,args=(url,),callback=parse_page) p.close() p.join() print('主',os.getpid()) #都不用.get()方法了 回调函数(下载网页的小例子)
无需回调函数的实例
from multiprocessing import Pool import requests import os def get_page(url): print('<%os> get [%s]' %(os.getpid(),url)) response = requests.get(url) #得到地址 response响应 return {'url':url,'text':response.text} if __name__ == '__main__': p = Pool(4) urls = [ 'https://www.baidu.com', 'http://www.openstack.org', 'https://www.python.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] obj_l= [] for url in urls: obj = p.apply_async(get_page,args=(url,)) obj_l.append(obj) p.close() p.join() print([obj.get() for obj in obj_l]) 下载网页小例子(无需回调函数)
本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/10340239.html

