


网络拥塞控制算法总结-PolyCC
字节跳动在SIGCOMM'23以Poster形式提交了一篇论文《PolyCC: Poly-Algorithmic Congestion Control》,试图将各种拥塞控制算法整合到一个统一的框架里。其理由是近40年来各种渠道发布的各种拥塞控制算法,没有一种算法能解决所有网络场景(不同的应用,不同的流量模型等)。
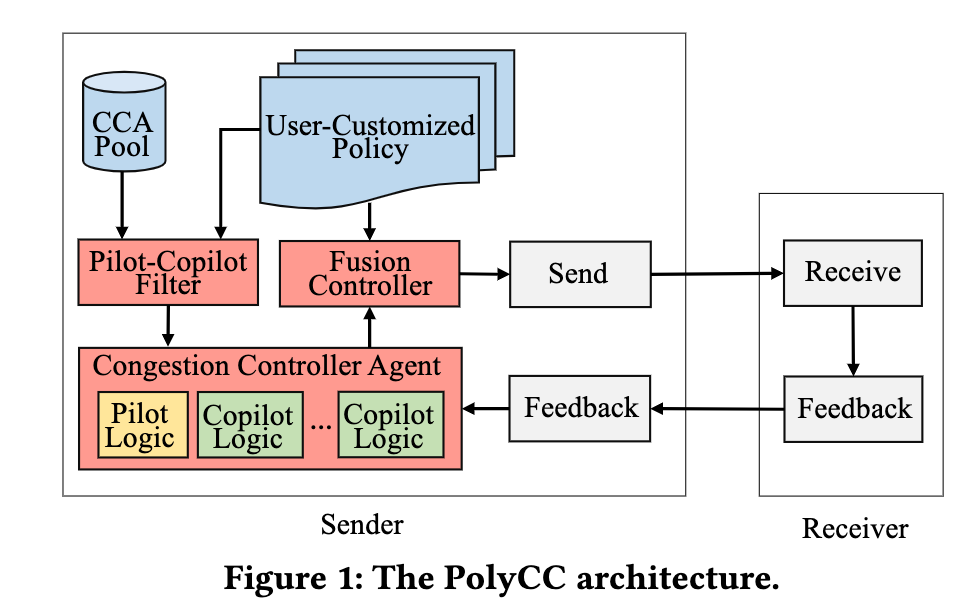
如上图,PolyCC定义了:
CCA Pool:即拥塞控制算法(Congestion Control Algorithm)池,包括了一系列备选的拥塞控制算法实现。
Pilot-Copilot Filter:根据某种策略,从CCA中选举出一个主算法(Pilot)和多个辅助算法(Copilot)。
Congestion Controller Agent:负责运行Pilot-Copilot Filter选举出的所有算法。“运行”应该包括产生用于感知拥塞控制的探测信号以及处理探测信号的反馈。
Fusion Controller:用于将主算法和各种辅助算法的计算结果(主要是cwnd和pacing rate)进行整合。
User-Customiszed Policy:一个用户可定制的决策机制,用于决策选举哪些算法作为主算法和辅助算法,以及Fusion Controller具体如何融合各种拥塞控制算法的计算结果。
文章提出两个场景来对PolyCC进行验证:
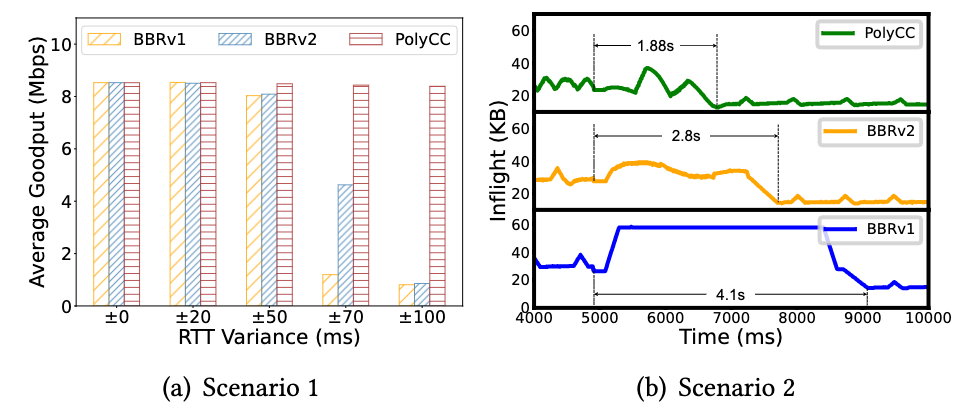
1、对吞吐的改进(Goodput improvement)
在RTT抖动比较大的场景中,文章认为BBR类拥塞控制算法会表现较差,但Cubic类算法会表现更好。但是文章设置PolyCC使用BBR作为主算法,Cubic作为辅助算法,融合算法为:cwnd=max{𝑐𝑤𝑛𝑑𝑏𝑏𝑟 , 𝑐𝑤𝑛𝑑𝑐𝑢𝑏𝑖𝑐 }(即拥塞窗口使用两种算法中较大者),并与单纯使用BBR1和BBR2的做对比,结果发现在RTT轻微抖动(±20ms)的场景下,PolyCC性能与BBR类似,但在RTT严重抖动(±70或±100)的场景下,PolyCC要比BBR1.82到10.35倍。
2、对收敛时间的改进(Convergence improvement)
文章在带宽突然减半的场景下做了实验。BBR需要2~4秒的时间才能收敛,而Copa会在1秒内完成收敛。PolyCC使用BBR作为主算法,Copa作为辅助算法,融合算法为:r=min{𝑟𝑏𝑏𝑟 , 𝑟𝑐𝑜𝑝𝑎 }(即整形速率使用两种算法中较小者)。设计实验在第5秒时带宽从20mbps减小为10mbs,结果表明PolyCC的收敛时间比BBR1减小54.1%,比BBR2减小32.8%。
妄评:
- PolyCC试图结合多种算法来解决网络环境多样化带来的拥塞控制无法胜任的问题,但是究竟如何选择拥塞控制,文章并未给出明确的说明,看起来算法选择不是那么容易的。文章中的时延也有点不是很自洽:对于某个场景,A算法的效果更好,B算法的效果更差,这种情况下PolyCC为什么选择效果差的算法作为主算法,而效果好的算法作为辅助?而且实验总是拿BBR作为比较对象,而不是单独验证A或者B算法。
- PolyCC更同时使能多种拥塞控制算法,带来的运算量更大,虽然文章指出可以同时选择多种算法作为辅助,但是实验总是选择一种辅助算法,估计作者也是考虑到性能问题。毕竟如果运算量过大,必然会导致算法决策时间变长,效果会打折扣。
- 从文章中的实验来看,使用QUIC作为发流工具,而不是目前数据中心的高吞吐低延迟网络场景,推测本文并不瞄准数据中心网络场景。由于数据中心网络高吞吐低延迟的需求,大量使用RDMA等硬件协议卸载方案,而PolyCC由于计算量和复杂度原因,显然对于硬件卸载不够友好。

