


SPI机制
一、什么是SPI机制
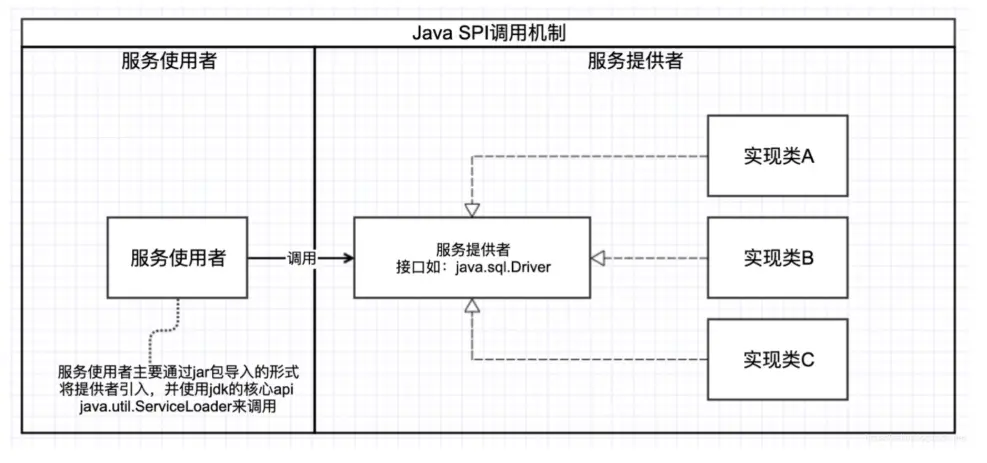
(1)SPI是Service Provider Interface 的简称,即服务提供者接口的意思。
(2)SPI说白了就是一种扩展机制,SPI的目的是通过读取规定配置信息,通过反射的方式创建接口实现类。
(3)有了SPI机制,就为框架的灵活扩展提供了可能,而不必将框架的一些实现类写死在代码里面。
SPI接口一般有两种情况,一种是JDK中声明的SPI接口,一种是框架使用的SPI例如dubbo。这两种情况使用的加载器是不同的。
JDK声明的SPI接口:SPI的实现类一般是由应用加载器Application ClassLoader加载的,而JDK提供的SPI接口是Bootstrap ClassLoader加载:也就导致SPI接口无法找到对应的实现类。根本原因:并不是同一个类加载器进行加载的。为了解决这种情况,JVM设计出线程上下文加载器,来打破双亲委派模型。即父类使用子类的类加载器来进行类加载。从而保证父子类由一个类加载器进行加载,
框架的SPI接口:无论是父类还是子类,均使用的是Application ClassLoader加载,不会打破双亲委派模型,子类将委托父类的类加载器完成类的加载,从而保证了父子类由一个类加载器进行加载。
二、SPI机制的主要目的与缺陷
SPI机制引入原因:
场景:如何寻找一个接口的所有实现类
- Spring环境:可以依赖注入一个集合,那么会扫描Spring容器中该接口的所有时间类。
- 侵入代码:可以维护一个枚举类或者一个map来存储接口所有的实现类。
但是对于框架来说,即不能和Spring强耦合,也无法侵入代码未卜先知声明所有的子类。所以就有了SPI:Service Provider Interface,是一种服务发现机制。
SPI目的:在框架中找到某个接口的实现所有实现类,存储到List中。或者更新颖的玩法,在子类上声明注解,通过SPI找到所有实现类,然后得到实现类上的注解参数,将其组合为一个Map。当不同的请求到达时,可以动态的选择不同的子类来进行处理。
SPI机制缺陷:
1.不能按需加载,需要遍历所有的实现,并实例化,然后在循环中才能找到我们需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。
3.多个并发多线程使用 ServiceLoader 类的实例是不安全的。
三、SPI与API的区别
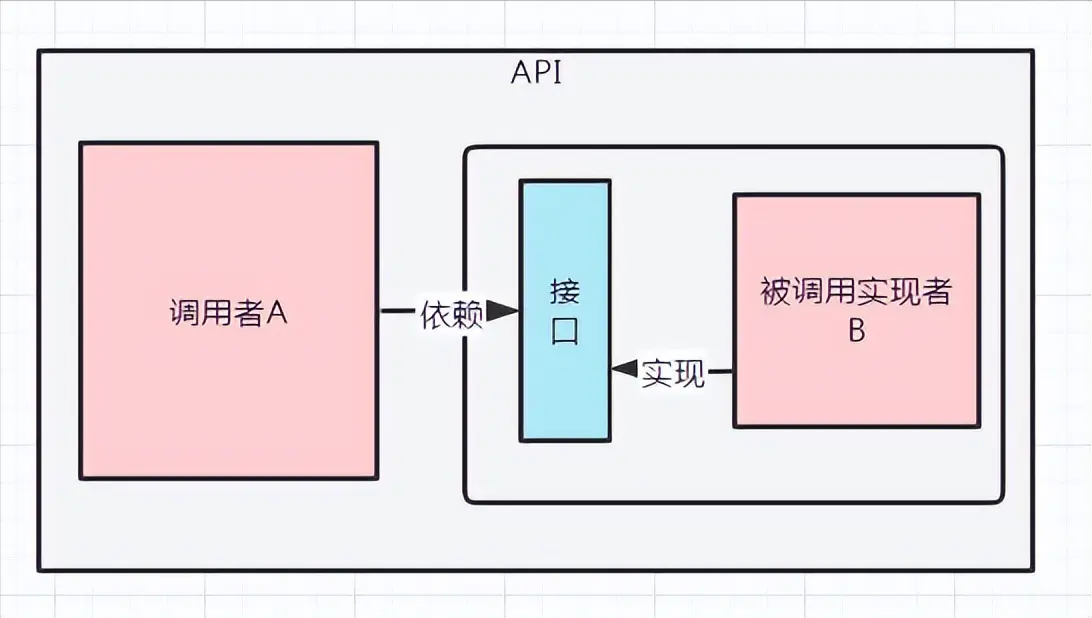
API图解:
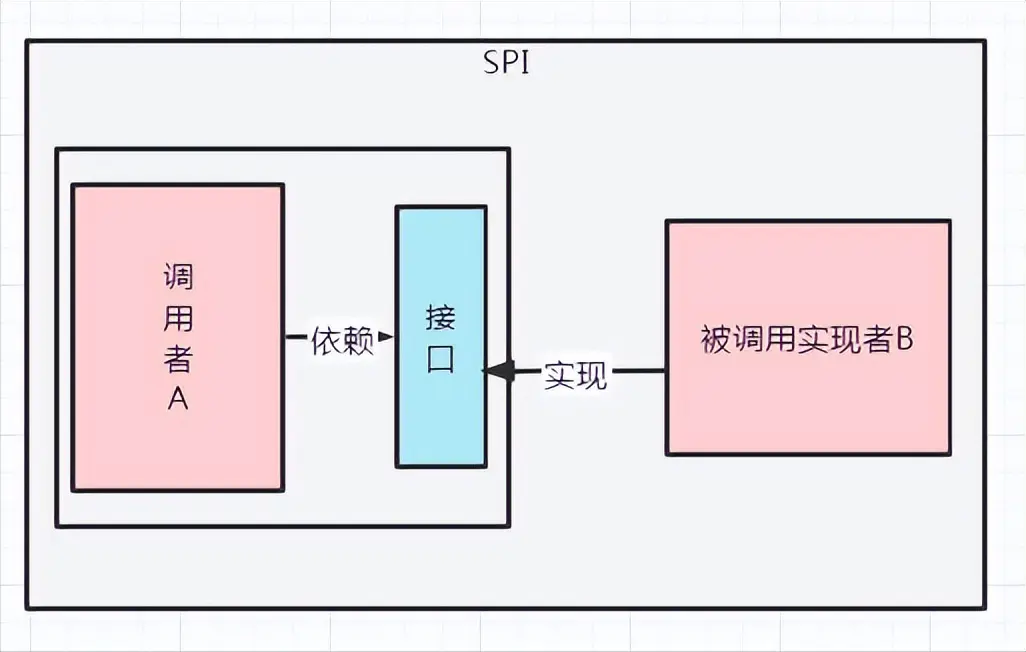
SPI图解:
API依赖的接口位于实现者的包中,概念上更接近于实现方,组织上存在于实现者的包中,实现和接口同时存在在实现者的包中
SPI依赖的接口在调用方的包中,概念上更接近于调用方,组织上位于调用者的包中,实现逻辑在单独的包中,实现可插拔。
四、业务项目中有机会使用SPI吗
在Spring一统天下,只针对业务系统来说,Spring的bean单例池+依赖注入集合对象的方式可以找到某个接口的在Spring容器中的所有实现子类。故SPI这种服务发现的方式其实用到的机会不是很多。
但是脱离Spring的一些框架,使用SPI方法找到接口对应的所有子类的方式是比较常见的。例如dubbo、sentinel、seata等框架。了解SPI的对阅读源码或者自己造轮子是非常有帮助的。
五、Java的SPI如何使用
先定义一个Developer接口
// Developer.java public interface Developer { void product(); }
再定义两个Developer接口的两个实现类

// DeveloperOne.java public class DeveloperOne implements Developer { @Override public void product() { System.out.println("Hi, I am DeveloperOne."); } } ******************************************* // DeveloperTwo.java public class DeveloperTwo implements Developer { @Override public void product() { System.out.println("Hi, I am DeveloperTwo."); } }
然后再在项目resources目录下新建一个META-INF/services文件夹,然后再新建一个以Developer接口的全限定名命名的文件,文件内容为:
// com.test.Developer文件 com.ymbj.spi.DeveloperOne com.ymbj.spi.DeveloperTwo
最后我们再新建一个测试类JdkSPITest:
// SPITest.java public class SPITest { @Test public void testSayHi() throws Exception { ServiceLoader<Developer> serviceLoader = ServiceLoader.load(Developer.class); serviceLoader.forEach(Developer::product); } }
六、SPI机制案例
(1)SPI机制在JDBC DriverManager中的应用
在mysql中的实现
在mysql的jar包mysql-connector-java-6.0.6.jar中,可以找到META-INF/services目录,该目录下会有一个名字为java.sql.Driver的文件,文件内容是com.mysql.cj.jdbc.Driver,这里面的内容就是针对Java中定义的接口的实现。
在postgresql中的实现
同样在postgresql的jar包postgresql-42.0.0.jar中,也可以找到同样的配置文件,文件内容是org.postgresql.Driver,这是postgresql对Java的java.sql.Driver的实现。
JDBC的SPI机制
首先来个简单的代码示例:
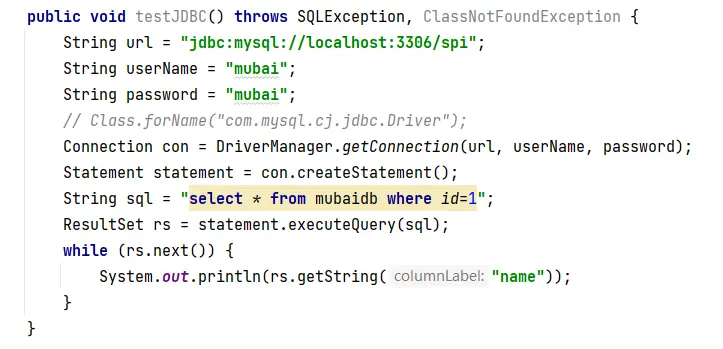
程序在加载DriverManager类时,会将MySQL的Driver对象注册进DriverManager中,这是SPI思想的一个典型的实现。应用程序中无需指定类似"com.mysql.cj.jdbc.Driver"这种全类名,尽可能地将第三方驱动从应用程序中解耦出来。
源码分析:
DriverManager是管理Jdbc驱动的基础服务类,位于Java.sql包中,由boot类加载器来进行加载。加载该类时,会先执行如下代码块:
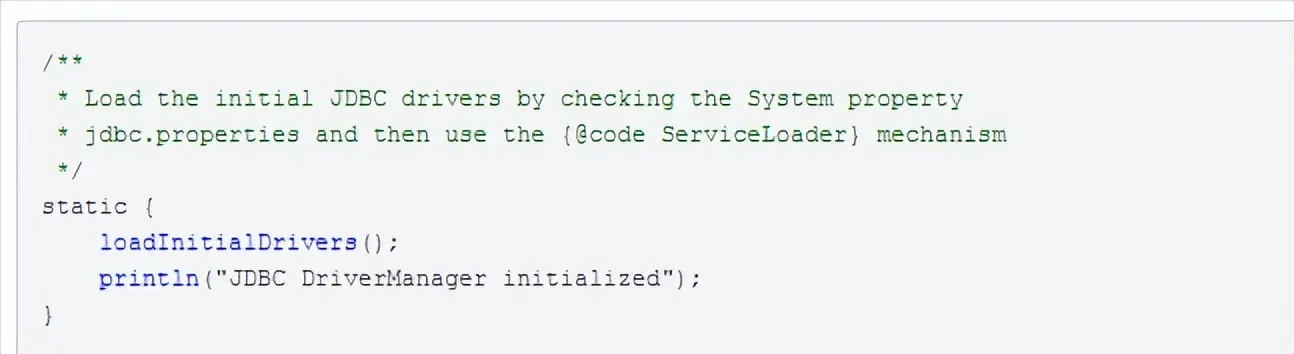
上面静态代码块会执行loadInitialDrivers()方法,用于加载各个数据库的驱动。代码如下:

- ServiceLoader.load(Driver.class)此方法会实例化一个ServiceLoader对象,并且注入线程上下文类加载器和Driver.class;
- loadedDrivers.iterator():此方法获得ServiceLoader对象的迭代器;
- driversIterator.hasNext():此方法用于查找Driver类;
- driversIterator.next():在实现的“next()”方法中进行类加载,使用上面的线程上下文类加载器。
ServiceLoader.load(Driver.class);代码及相关调用方法如下:

经过上述过程,使用成员变量private final ClassLoader loader;引用传入的类加载器,使用service接收Driver.class。同时,上述过程中实例化了一个LazyIterator对象,并用成员变量lookupIterator来引用。
执行ServiceLoader的“hasNext()”方法时最终会调用lookupIterator迭代器的“hasNext()”方法(此处暂且省略调用过程),如下:
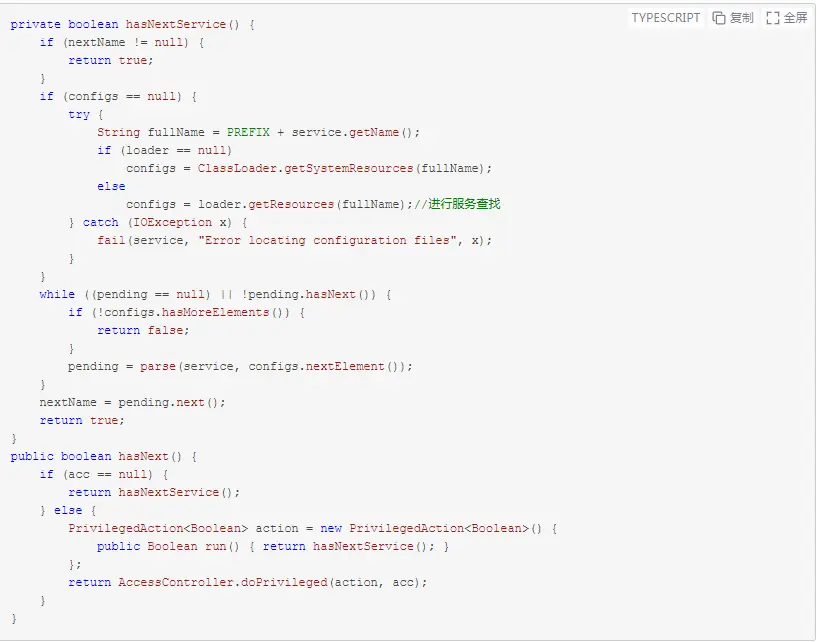
上述过程通过configs = loader.getResources(fullName)来查找并实现Driver接口的类。
同样,ServiceLoader的迭代器的“next()”方法最终会调用lookupIterator迭代器的“next()”方法,如下:
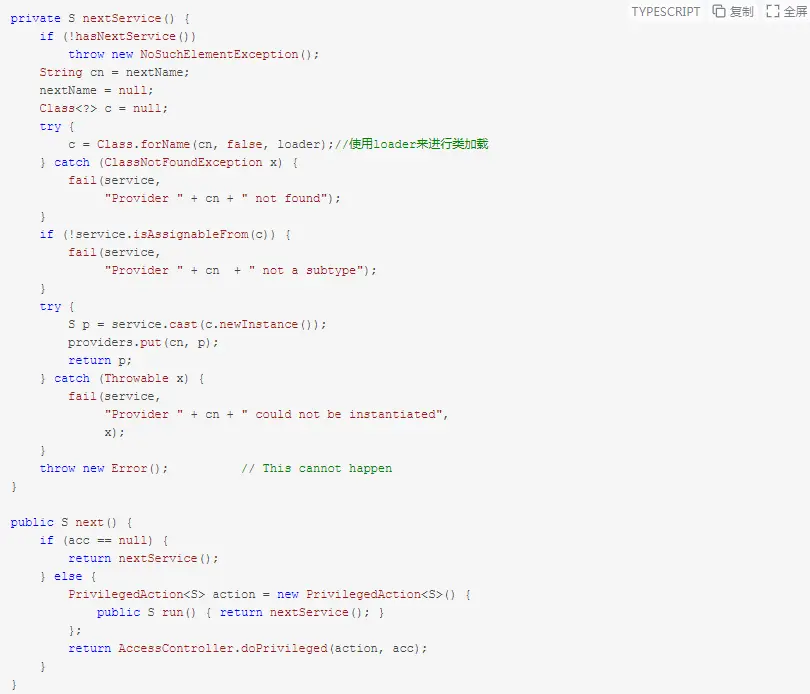
可以看到,next()会最终调用到nextService()方法,并在此方法中通过c = Class.forName(cn, false, loader);执行类加载。此处的loader也是由ServiceLoader中的loader传入的,即为前文提到的线程上下文类加载器。
经历了上述ServiceLoader类中的一系列操作之后(包括服务发现和类加载),位于mysql驱动包中的Driver类会被初始化。该类如下所示
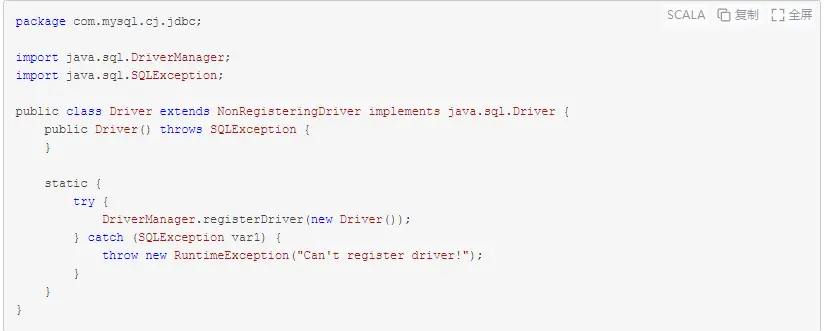
上述Driver类加载时,会执行静态代码块,即执行DriverManager.registerDriver(new Driver());方法向DriverManager中注册一个Driver实例。
我们再回到DriverManager类中,看看registerDriver方法
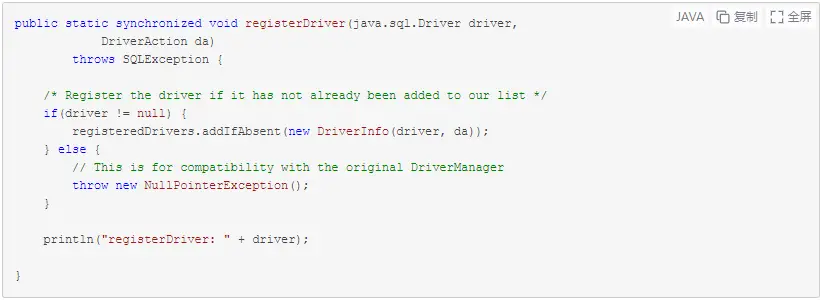
会将该MySQL驱动添加到成员变量registeredDrivers中,该成员变量存放已注册的jdbc驱动列表,如下:
这样一来,服务发现、类加载、驱动注册便到此结束。接下来,应用程序执行数据库连接操作时,会调用“getConnection”方法,遍历registeredDrivers,获取驱动,建立数据库连接。
oracle和mysql两种驱动的url有不同的前缀,"jdbc:mysql:"和"jdbc:oracle:thin",在获取连接的时候,会对这个前缀进行检查,参见mysql驱动的 parseURL方法。
DriverManager.getConnection方法中,遍历已经注册的驱动,挨个调用connec方法获取连接而connect方法进行一系列的检查,其中包括调用parseURL来检查是否符合当前驱动的前缀。
如果检查发现不符合响应的规则,则继续轮换下一个驱动继续尝试连接。
isDriverAllowed方法用于确保,注册的驱动类对调用类是可见的,因为注册驱动的类的类加载器和调用驱动的类的类加载器可能并非同一个,有可能互不可见。
(2)SpringBoot的SPI机制:我们可以在spring.factories中加上我们自定义的自动配置类,事件监听器或初始化器等;
(3)Dubbo的SPI机制:Dubbo更是把SPI机制应用的淋漓尽致,Dubbo基本上自身的每个功能点都提供了扩展点,比如提供了集群扩展,路由扩展和负载均衡扩展等差不多接近30个扩展点。如果Dubbo的某个内置实现不符合我们的需求,那么我们只要利用其SPI机制将我们的实现替换掉Dubbo的实现即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2015-04-22 STL标准容器特征