


缓存问题。
1. 怎么保证缓存和数据库严格一致性。
读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况。
2.如何应对缓存穿透(查询一个不存在的数据-提前无防护)。
(1)在缓存之前加一层BloomFilter(线程不安全)(google.guava包),对一定不存在的key进行过滤。
优点:1. 仅仅保留数据指纹,空间利用率高。2.查询效率高O(n) 3.信息安全性高。
缺点:1. 存在一定误判,只能过滤一定不存在的数据。2.数据删除困难。(数据库中的数据一般都是逻辑删。)一般不作删除操作(粗暴可以计数,效率低),但可以从新加载数据到布隆过滤器。
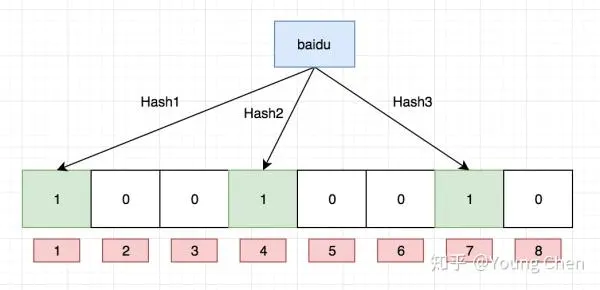
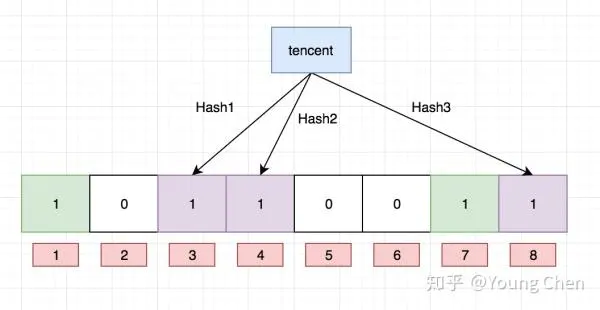
为什么要使用多个hash函数?减少因哈希冲突,造成的过滤失效。
(2)对于不存在的记录,要缓存空值,并设置过期时间。
3.如何应对缓存击穿。(查询已失效的key-防护失效)
多线程同时查询数据库中的同一条数据,我们可以在第一个查询数据的请求上使用互斥锁(单机锁或分布式锁)来锁住它。待第一个线程查询到了数据,然后做了缓存,后面的线程进来发现已经有了缓存,就直接走缓存。
4.如何应对缓存雪崩。(某一时刻发生大规模缓存失效或缓存直接挂了)
1. 设置不同的缓存失效时间。2.使用缓存集群(一主多从),保障高可用缓存。一个缓存实例挂掉后,能够自动做故障转移。(3)缓存水平切分。

