

ELK系列二(logstash日志调试)
对于logstash和filebeat来说,均有采集log的功能,elk如果采集的日志无需处理,可以使用lfilebeat采集日志直接输出至elasticsearch(非常不建议这么做,如此收集的日志输出的名称均为fieebeat+time,消息很多时候都放在了同一个标签message下)
我们使用的日志采集为elk+filebeat,如果你项提升速度可以使用filebeat采集输出至redis或者其他中间件来缓解logstash的压力,logstash格式话日志大量的话非常消耗cpu资源,如果你可以和开发人员协商直接输出json话的格式就可以舍弃掉logstash中 filter/grok 配置,对于nginx之类应用日志来说,
1,elasticesearch日志采集后均会输出为json话的日志格式输出至kibana,如果未经处理你会看见这样的日志:
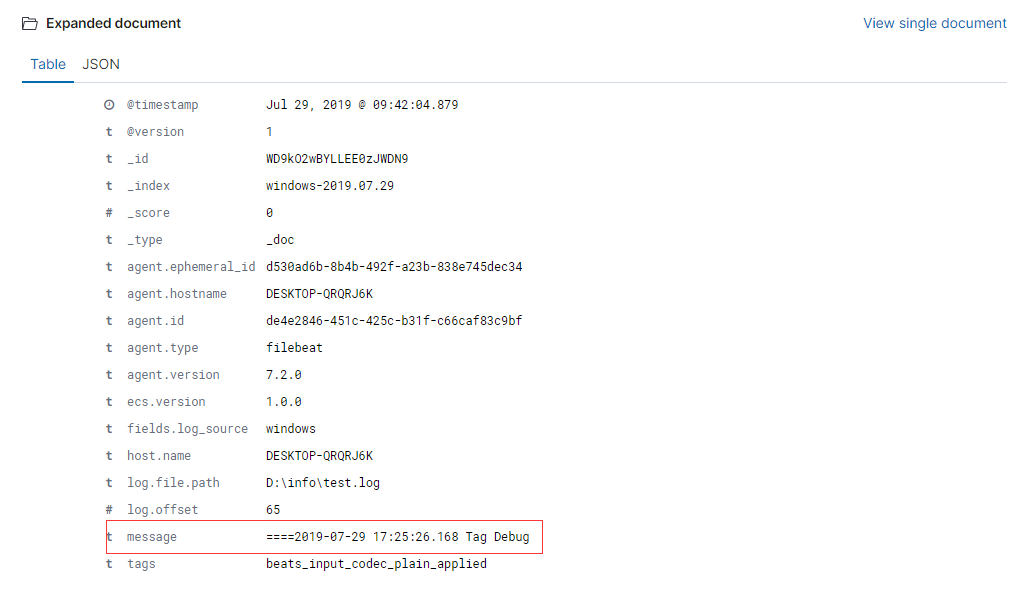
顺便贴上日志样式:

这里日志采集的filebeat放在了本机的windows下,采集到Logstash后未作任何处理便输出到了ES,所有的日志消息全部生成到了message下,而且采集的时间和日志输出的时间都是不一样的,这显然无法使用:
为此logstash提供了一系列的插件来处理这些日志格式:
http://doc.yonyoucloud.com/doc/logstash-best-practice-cn/input/file.html详细可以参见这篇文章。
2,那么下面我们就一步步的来调试这部分log:
2.1,首先我们应该多行合并,logstash提供了一个叫multiline的插件,
查询logstash安装的插件:
/usr/share/logstash/bin/logstash-plugin list

如果没有安装则需要安装:
/usr/share/logstash/bin/logstash-plugin install logstash-filter-multiline
2.2,合并日志:
input{ beats{ port => "5046" } } filter{ multiline { pattern => "^\====" negate => true what => "previous" } } output{ elasticsearch{ hosts => ["127.0.0.1:9200"] index => "windows-%{+YYYY.MM.dd}" } }
2.3,再看前端显示的日志:

2.4,grok日志格式化:
ELK已经设置好了很多匹配格式,很多时候直接拿来用就行 https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
调试可能需要调试很久,好在kibana提供了调式工具,

这里我调试好了日志格式
multiline固然合并了换行,但是在ES里输出的时候仍旧为两行的日志,所以这里我自定义了个TEST的匹配模式匹配了换行符,那么我们把它写在配置文件中:
input{ beats{ port => "5046" } } filter{ multiline { pattern => "^\====" negate => true what => "previous" } grok { patterns_dir => "/etc/logstash/patterns/logstash.patterns" match => {"message" => "%{DATE_EU:date} %{TIME:time} %{USER:TakingID} %{USER:Loglevel}%{TEST:imformation}"} remove_field =>["message"] } } output{ elasticsearch{ hosts => ["127.0.0.1:9200"]
这里用remove_filed删除了message字段;否则数据实质上就相当于是重复存储了两份
3,关于日志删除
日志放在es里是要做定时删除的,除了要清理客户端的日志外,还要清理es存储 的日志:
查询 curl 'localhost:9200/_cat/indices?v'

删除 curl -XDELETE 'localhost:9200/windows-2019.07.26'
删除后在查询:

4,到这里ELK基本能满足日常使用了,后面在详细说说logstash多入多出

