
数仓开发理论(二)数仓构建分层概念
数仓建模的好处
- 好的数据仓库能够支持复杂数据分析和决策,能够提供高性能查询,能够做到数据的通用集成和保持数据的一致性,可以说得上是面向业务分析的数据库
- 数仓功能本质就是通过建模来达成对复杂业务的抽象,清晰准确完整的刻画业务场景,以便用户通过业务视角便捷的获取所需数据,完成对业务活动的度量
案例一 零售行业
- 背景:某大型零售企业希望通过数据分析提高销售业绩
- 实施:构建数据仓库,集成销售数据、客户数据和库存数据,采用星型模型设计
- 效果:通过OLAP分析,企业能够实时监控销售情况,了解各个产品线的销售趋势和客户行为,优化库存管理,制定精准的市场营销策略
案例二 银行业
- 背景:某银行希望提升风险管理能力和客户服务水平
- 实施:构建数据仓库,集成交易数据、客户数据和风险评估数据,采用雪花型模型设计
- 效果:通过数据仓库的多维分析和数据挖掘,银行能够识别高风险客户和交易,提升风控能力;同时,分析客户行为数据,提供个性化的金融服务,提升客户满意度
数仓分层概念
业务板块
- 首先需要明确公司构建数仓具体需要使用在哪些业务上,比如是用于电商系统,或者是投资系统,不同的业务系统需要构建唯一的数仓,不能N:1(即一个数据仓库支持多个业务系统)的构建数仓,以免数据混淆污染
数据域
- 从业务的角度,对数据进行总体的归类和划分,形成的有边界的数据范围
- 面向业务分析,将业务过程或者维度进行抽象的集合一个数据域代表一个特定的业务领域或主题领域,如销售、财务、人力资源、库存管理等,每个数据域包含特定的业务事实和与这些事实相关的维度
销售数据域
- 事实表:销售事实表(如销售交易、订单详情)
- 维度表:产品维度表、客户维度表、时间维度表、销售人员维度表、地区维度表
财务数据域
- 事实表:财务事实表(如收入、支出、利润)
- 维度表:账户维度表、时间维度表、部门维度表、费用类别维度表
人力资源数据域
- 事实表:员工事实表(如员工信息、考勤记录)
- 维度表:员工维度表、部门维度表、职位维度表、时间维度表
维度
- 维度为数据分析提供了不同的视角和分类方式,例如时间、地点、产品、客户等
特征
- 描述性:维度通常包含描述性的信息,例如产品名称、客户名称、时间日期等
- 分类和分组:维度允许数据按不同的类别和层次进行分类和分组,以支持多维分析
- 层次结构:维度通常具有层次结构,例如时间维度可以包括年、季度、月、日等层次
示例
- 时间维度:包含年、季度、月、日等信息
- 产品维度:包含产品ID、产品名称、类别、品牌等信息
- 客户维度:包含客户ID、客户名称、地址、客户类别等信息
--产品维度表
CREATE TABLE Dim_Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Product_Category VARCHAR(50),
Product_Brand VARCHAR(50)
);
维度建模
| 星型模型 | 雪花模型 | 星座模型 | |
|---|---|---|---|
| 概念 | 所有的维度表都和事实表相连,较为简单的模型,不存在渐变维度,所以数据有一定的冗余 | 雪花模型相当于将星型模式的大维表拆分成小维表,满足了规范化设计,但是难以维护,加大开发难度 | 很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到,在业务发展后期,绝大部分维度建模都采用的是星座模式 |
| 查询速度 | 快,不需要和外表关联进行查询和数据分析,因此效率相对较高 | 较慢,需要join的表⽐较多所以其性能并不⼀定⽐星型模型⾼ | 较快,适用于跨主题的复杂分析,可以支持多种业务过程的数据分析 |
| 冗余度 | 高,星型架构是⼀种⾮正规化的结构,多维数据集的每⼀个维度都直接与事实表相连接,不存在渐变维度,所以数据有⼀点的冗余。如在地域维度表中,存在国家A省B的城市C以及国家A省B的城市D两条记录,那么国家A和省B的信息分别存储了两次,即存在冗余 | 低,它对星型模型的维表进⼀步层次化,原有的各维表可能被扩展为⼩的事实表,形成⼀些局部的"层次"表,去重冗余。如将地域维表分解为国家,省份,城市等维表 | 较低,共享的维度表为多个事实表提供描述信息。由于维度表被多个事实表共享,相比于每个事实表各自拥有独立的维度表,数据冗余度较低 |
| 可读性 | 容易 | 差 | 容易 |
| 表数量 | 少 | 多 | 较少 |
星型模型

雪花模型

星座模型
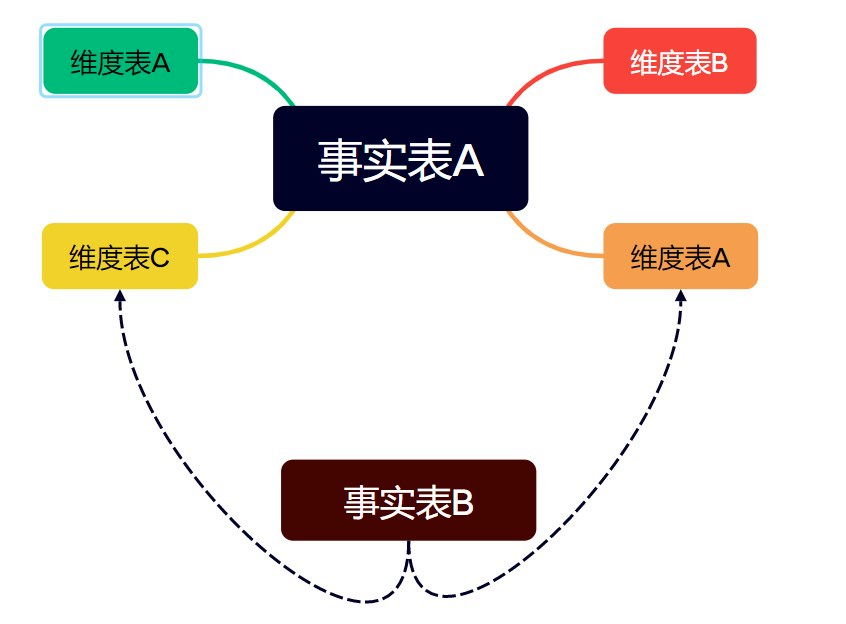
属性(维度属性)
- 维度所包含的表示维度的列称为维度属性
- 维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键
示例
| 产品维度表 | 说明 |
|---|---|
| 产品ID(Product_ID) | 唯一标识每个产品的主键 |
| 产品名称(Product_Name) | 产品的名称 |
| 产品类别(Product_Category) | 产品所属的类别 |
| 产品品牌(Product_Brand) | 产品的品牌 |
| 产品价格(Product_Price) | 产品的价格 |
业务过程
- 企业或组织中为完成特定目标而进行的一系列活动或任务的集合
销售过程
- 目标:完成产品销售,生成销售订单
- 活动:客户下单,订单处理,支付,发货,售后服务
- 数据仓库:销售事实表记录每笔销售交易,维度表包括产品维度、客户维度、时间维度等
--销售事实表
CREATE TABLE Fact_Sales (
Sale_ID INT PRIMARY KEY,
Product_ID INT,
Time_ID INT,
Sales_Amount DECIMAL(10, 2),
Sales_Quantity INT,
FOREIGN KEY (Product_ID) REFERENCES Dim_Product(Product_ID),
FOREIGN KEY (Time_ID) REFERENCES Dim_Time(Time_ID)
);
度量
- 度量(Measure)是用于量化业务过程的数值型数据,可以进行汇总和分析
- 度量通常存储在事实表中,并与维度表关联,以提供丰富的上下文信息
| 销售过程中的度量 | 说明 |
|---|---|
| 销售金额(Sales Amount) | 每笔销售的总金额,可以累加 |
| 销售数量(Sales Quantity) | 每笔销售的产品数量,可以累加 |
| 折扣金额(Discount Amount) | 每笔销售的折扣金额,可以累加 |
指标
- 指标分为原子指标和派生指标
- 原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词 ,体现明确的业务统计口径和计算逻辑
- 原子指标=业务过程+度量
- 派生指标=时间周期+修饰词+原子指标,派生指标可以理解为对原子指标业务统计范围的圈定
指标直接与业务活动相关,用于反应业务的关键绩效指标,比如:
| 派生指标 | 说明 |
|---|---|
| 销售收入 | 衡量某一时间段内的总销售额 |
| 客户获取成本(CAC) | 获取一个新客户的平均成本 |
| 净利润率 | 净利润占总收入的百分比 |
| 库存周转率 | 库存在特定时间内被出售和替换的次数 |
- 原子指标对应的为:单笔交易的金额、单词访问的时长、单个产品的库存数量
业务限定
统计的业务范围,筛选出符合业务规则的记录,类似于SQL中where后的条件,不包括时间区间
统计周期
统计的时间范围,例如最近一天,最近30天等,类似于SQL中where后的时间条件
统计粒度
- 统计粒度是统计分析的对象或视角,定义数据需要汇总的程度,可理解为聚合运算时的分组条件,类似于SQL中的group by的对象
时间粒度
- 按秒记录:非常细的时间粒度,适用于需要精确时间戳的数据分析,如服务器日志
- 按分钟记录:较细的时间粒度,适用于实时数据分析,如交易系统
- 按天记录:常见的时间粒度,适用于日常业务报表,如每日销售报告
- 按月记录:较粗的时间粒度,适用于长期趋势分析,如月度财务报告
SELECT
Time_ID,
SUM(Sales_Amount) AS Total_Sales_Amount,
SUM(Sales_Quantity) AS Total_Sales_Quantity
FROM
Fact_Sales
GROUP BY
Time_ID;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号