

Hadoop(十八)MapReduce Shuffle机制
MapReduce工作流程
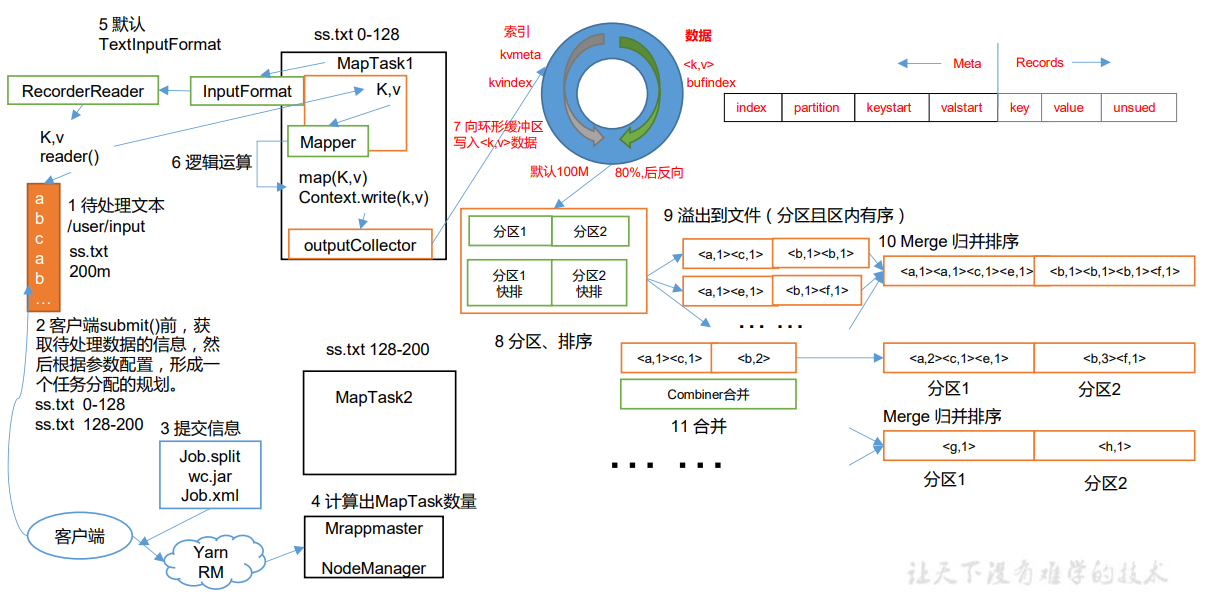
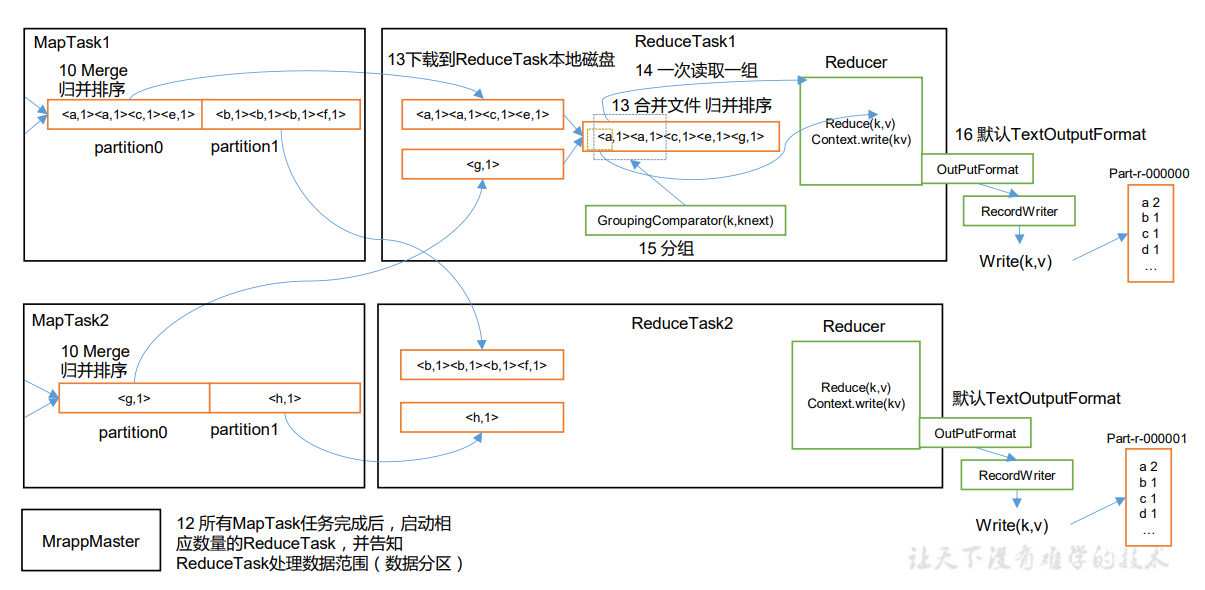
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
- MapTask收集map()方法输出的kv对,放到内存缓冲区中
- 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
- ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
- ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
- 合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意
- Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
- 缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M
Shuffle机制
- Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
一、Partition分区
- 将统计结果按照条件输出到不同文件中
- 默认分区是根据key的hashCode对ReduceTasks个数取模得到的,用户没法控制哪个key存储到哪个分区
自定义Partitoner步骤
- 自定义类继承Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
- 在Job驱动中,设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class);
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
job.setNumReduceTasks(5);
分区总结
- 如果ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
- 如果1 < ReduceTask的数量 < getPartition的结果数,则有一部分分区数据无处安放,会Exception;
- 如果ReduceTask的数量 = 1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
- 分区号必须从0开始,逐一累加
二、WritableComparable排序
- MapTask和ReduceTask均会对数据按照key进行排序,该操作属于Hadoop的默认行为,任何应用程序中的数据均会被排序,而不管逻辑上是
否需要 - 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序
- 对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序
- 对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序
排序分类
- 部分排序:MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部有序
- 全排序:最终输出结果只有一个文件,且文件内部有序,实现方式是只设置一个ReduceTask,但该方法在处理大型文件时效率极低
- 辅助排序:在Reduce端对key进行分组
- 二次排序:在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
三、Combiner合并
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置,Combiner是在每一个MapTask所在的节点运行;Reducer是接收全局所有Mapper的输出结果
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来
Mapper
3 5 7 ->(3+5+7)/3=5
2 6 ->(2+6)/2=4
Reducer
(3+5+7+2+6)/5=23/5 不等于 (5+4)/2=9/2
分类:
Hadoop


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具