
推荐系统常见面试题2
原文链接:https://blog.csdn.net/weixin_38664232/article/details/89975716
15、Bias和Variance的区别
Bias度量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力。
Variance度量了同样大小的训练集的变动所导致的学习性能变化,即刻画了数据扰动所造成的影响。
16、对于支持向量机,高斯核一般比线性核有更好的精度,但实际应用中为什么一般用线性核而不用高斯核?
如果训练的样本的量很大,训练得到的模型中支持向量的数量太多,在每次做预测时,高斯核需要计算带预测样本与每个支持向量的内积,然后做核函数变换,这回非常耗时;而线性核只需要计算
17、高斯混合模型中,为什么各个高斯分量的权重和要保证为1?
为了保证这个函数是一个概率密度函数,即积分值为1。
18、为什么很多时候用正太分布来对随机变量建模?
现实世界中很多变量都服从或近似服从正太分布。中心极限定理指出,抽样得到的多个独立同分布的随机变量样本,当样本数趋向于正无穷时,它们的和服从正太分布。
19、协同过滤算法如何实现,用户特征向量用哪些用户属性表示,如何挖掘更多的用户信息?

20、说出计算用户之间相似度的三种方式?
Jaccard相似度
杰卡德相似度(Jaccard similarity coefficient),也称为杰卡德指数(Jaccard similarity),是用来衡量两个集合相似度的一种指标。Jaccard相似指数被定义为两个集合交集的元素个数除以并集的元素个数。

余弦相似度
将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并求得夹角之间的余弦值,此余弦值就可以用来表征,这两个向量之间的相似性。夹角越小,余弦值越接近于1,则越相似。
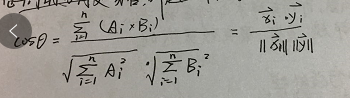
Pearson系数(皮尔森系数)
皮尔逊系数也称为积差相关(或积矩相关),是英国统计学家皮尔逊提出的一种计算直线相关的方法。取值范围[-1.1]。
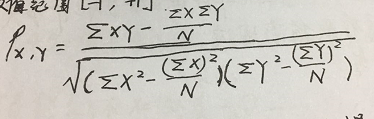
21、说出你的推荐算法的效果,如何提升推荐准确率,如何知道推荐结果是否正确?

22、数据预处理中,预处理哪些数据?如何预处理?
协同过滤的数据源主要是收集用户数据,如用户的行为,而预处理的工作是数据归一化、降维和去噪等。
归一化
在使用用户行为时,针对不同的操作,可能需要加权。有些特征量级可能非常大,需要对数据做归一化,将其限制在一个相同的取值范围内。
度量数据的相似度
观察哪些特征之间相关性比较高,后期可以考虑做特征组合。
正负样本不均衡
采用下采样,减少负样本数目。
降维
缓解数据稀疏性问题。
去噪
采用去噪,减少异常操作(误操作/离群点)对推荐系统结果的影响。
23、训练决策树时的参数是什么?
- criterion 分裂标准 分类---“gini”;回归---“mse” entropy:分裂节点时的评价指标是信息增益
- max_depth:树的最大深度。如果为None,则深度不限,直到所有的叶子节点都是纯净的,即叶子节点中所有的样本点都属于一个类别。或者每个叶子节点样本数目小于min_sample_split
- min_sample_split:分裂一个叶子节点所需要的最小样本数
- min_sample_leaf:每个叶子节点包含的最小样本数
- min_weight_fraction_leaf:叶子节点中样本的最小权重
- max_feature:分类时考虑的最多特征数
- random_state:随机数生成器的种子
- max_leaf_nodes:最大叶子节点数量
- min_impurity_split:树生长过程中过早停止的阈值。
- presort:是否需要提前排序数据
24、在决策树的节点处分割的标准是什么?
DecisionTreeClassifier()----criterion:'gini' or 'entropy'(default =gini),前者是基尼系数,后者是信息熵(信息增益)
DecisionTreeRgrossor()----criterion:'mse' 均方误差
25、随机森林的优点?
1.生成方式
随机生成的具有多棵决策树的分类器。输出结果由多棵树的输出结果加权或者取平均而成。
2.随机性体现在两个方面
- 训练数据采用bootstrap方式,从数据集中取出一个样本数为N的训练集
- 在每个节点上,随机选择所有特征的一个子集
3.优点
- 在很多数据集上表现良好
- 能够处理高纬度的数据,且不用做特征选择(特征子集是随机选择的)
- 训练速度快,容易做成并行化方法(训练时,树与树之间相互独立)
- 训练过程中,能检测到特征间的相互影响
26、介绍下boosting算法
boosting思路:通过训练多个若学习器,最后整合为一个强学习器的过程
从两个方面考虑:
- 增大训练集中,分错样本的权重,减小分对样本的权重
- 增大分错率低的学习器的权重,减小分错率高的学习器的权重。
27、SVM中用到了哪些核?SVM中的优化技术有哪些?

28、GBM和随机森林都是基于树的算法,它们有什么区别?
- RF采用bagging技术做出预测;GBM采用boosting技术做出预测
- bagging技术,数据集采用bootstrap随机采样的方法被划分为n个样本,对多棵树的结果进行加权或者取平均;boosting在第一轮预测之后,增加分类出错的样本权重,减小错误率高的基学习器(树)的权重,持续进行,一直到达停止标准。
- RF采用减小方差提高模型精度,生成树之间没有相关性;GBM在提高精度的同时降低了偏差和方差,某一个基学习器是以上一个基学习器的结果为基础,基学习器之间具有相关性。

