

HashTable 及应用
HashTable-散列表/哈希表,是根据关键字(key)而直接访问在内存存储位置的数据结构。 它通过一个关键值的函数将所需的数据映射到表中的位置来访问数据,这个映射函数叫做散列函数,存放记录的数组叫做散列表。
构造哈希表的几种方法
1. 直接定址法--取关键字的某个线性函数为散列地址,Hash(Key)= Key 或 Hash(Key)= A*Key + B,A、B为常数。
2. 除留余数法--取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址。Hash(Key)= Key % P。
3. 平方取中法
4. 折叠法
5. 随机数法
6. 数学分析法
哈希冲突/哈希碰撞
不同的Key值经过哈希函数Hash(Key)处理以后可能产生相同的值哈希地址,我们称这种情况为哈希冲突。任意的散列函数都不能避免产 生冲突。

处理哈希冲突的闭散列方法:
1. 线性探测
2. 二次探测
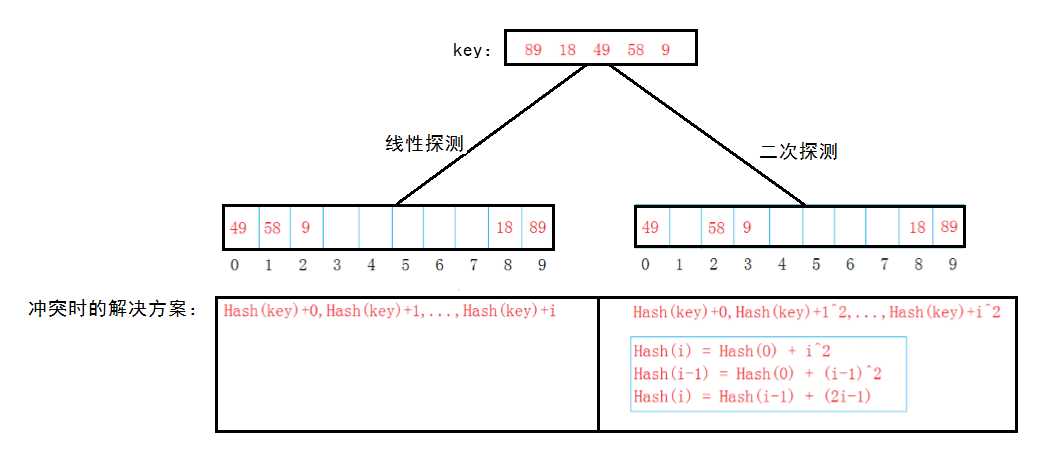
处理哈希冲突的开链法(哈希桶):

素数表(使用素数做除数可以减少哈希冲突) // 使用素数表对齐做哈希表的容量,降低哈希冲突
// 使用素数表对齐做哈希表的容量,降低哈希冲突 const int _PrimeSize = 28; static const unsigned long _PrimeList [_PrimeSize] = { 53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul };
字符串哈希算法
http://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
哈希表的应用之布隆过滤器:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就知道集合中有没有它了:
如果这些点有任何一个 0,则被检索元素一定不在;
如果都是 1,则被检索元素很可能在。

布隆过滤器的博文:
https://segmentfault.com/a/1190000002729689
http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html
相应的源代码请点击:https://github.com/shihaokiss
