

LoadRunner测试结果分析
原文:http://blog.sina.com.cn/s/blog_8216ada70100tyx3.html
LoadRunner生成测试结果并不代表着这次测试结果的结束,相反,这次测试结果的重头戏才刚刚开始。如何对测试结果进行分析,关系着这次测试的成功与否。网上关于LoadRunner测试结果如何分析的介绍相当匮乏,在总结他人的观点和自己的实验体会基础上来介绍如何进行LoadRunner测试结果分析。
1. LoadRunner测试结果分析的第一步应该是查看分析综述(Analysis Summary),其包括统计综述(Statistics Summary)、事务综述(Transaction Summary)、HTTP 响应综述(HTTP Responses Summary)三部分。在统计综述中查看Total Errors的数量,HTTP 响应综述中查看HTTP 404数量,若数值相对较大(HTTP 404则相对于HTTP 200),则说明系统测试中出错较多,系统系能有问题;另外查看事务的平均响应时间和其90%的事务平均响应时间,若时间过长,超过测试计划中的要求值,则说明系统的性能不满足我们的要求。
2. 第二步对LoadRunner测试结果图进行分析,首先对事务综述(Transaction Summary)进行分析,该图可以直观地看出在测试时间内事务的成功与失败情况,所以比第一步更容易判断出被测系统运行是否正常。
3. 接着分析事务平均响应时间(Average Transaciton Response Time),若事务平均响应时间曲线趋高,则说明被测系统处理事务的速度开始逐渐变慢,即被测系统随着运行时间的变化,整体性能不断下降。当系统性能存在问题时,该曲线的走向一般表现为开始缓慢上升,然后趋于平稳,最后缓慢下降。原因是:被测系统处理事务能力下降,事务平均响应时间变长,在曲线上表现为缓慢上升;而并发事务达到一定数量时,被测系统无法处理多余的事务,此时曲线变现为趋于平稳;当一段时间后,事务不断被处理,其数量减少,在曲线上表现为下降。如果被测系统没有等待机制,那么事务响应时间会越来越长,最后系统崩溃。
4. 再分析每秒通过事务数(Transactions per Second/TPS),该曲线表示被测系统在运行的任意时刻,每个事务通过、失败的情况,其是考查系统性能的一个重要参数。若随着压力的增加,曲线如果开始变化缓慢或有平稳的趋势,则有可能是服务器开始出现瓶颈。
[5]. 分析每秒通过事务总数(Total Transactions per Second),该曲线显示在任意时刻被测系统通过的事务总数、失败的事务总数。该曲线走向和TPS曲线走向一致。
[6]. 事务性能摘要(Transaction Performance Sunmmary)该曲线表示被测系统中所有事务的最小、最大和平均事务响应时间。
[7]. 事务在负载情况下的响应时间(Transaction Response Time Under Load),该曲线表示在不同数量的虚拟用户情况下的事务响应时间情况。该图对分析具有渐变负载的测试场景比较有用。
[8]. 事务响应时间(百分比)(Transaction Response Time(Percentile)),该曲线可以容易地分析出在给定的响应时间范围内事务量的百分比重。
[9]. 事务响应时间(分布)(Transaction Response Time(Distribution)),该图可以容易地分析出在给定响应时间范围内的事务量情况。
其实,若并不是十分详细地分析测试结果,第4步与第5步选其一分析,第6步、第7步、第8步为可选项,因为在第1步就在一定程度上分析了,而第9步又与第8步功能相识。LoadRunner生成测试结果图在很大的程度上具有一定的重复性,只不过是在不同情况下的具体显示。
以下内容原文:http://www.testwo.com/blog/5466
Duration(持续时间):了解该测试过程持续时间。测试人员本身要对这个时期内系统一共做了多少的事有大致的熟悉了解.以确定下次增加更多的任务条件下测试的持续时间。
Statistics Summary(统计摘要):只是大概了解一下测试数据,对我们具体分析没有太大的作用.
Transaction Summary(事务摘要):了解平均响应时间Average单位为秒。
其余的看不看都可以,都不是很重要。
4、分析集合点
在录制脚本中通常我们会使用到集合点,那么既然我们用到了集合点,我们就需要知道Vuser是在什么时候集合在这个点上,又是怎样的一个被释放的过程。这个时候就需要观察Vuser-Rendezvous图。
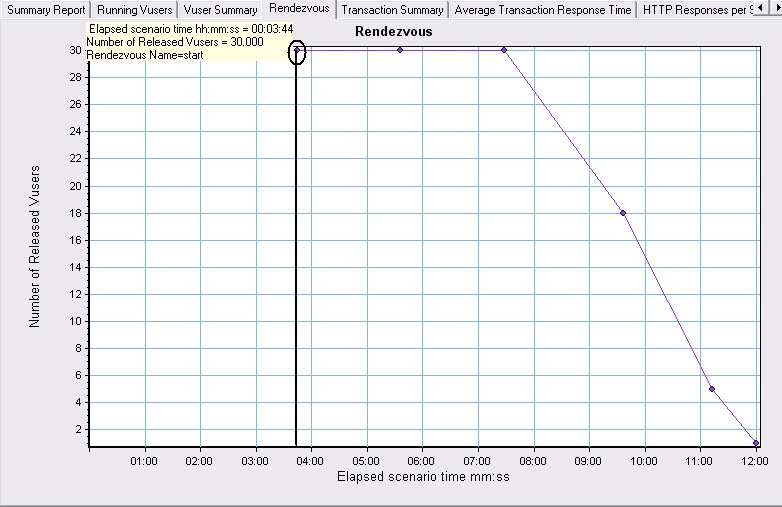
图1
可以看到大概在3分50的地方30个用户才全部集中到start集合点,持续了3分多,在7分30的位置开始释放用户,9分30还有18个用户,11分10还有5个用户,整个过程持续了12分。
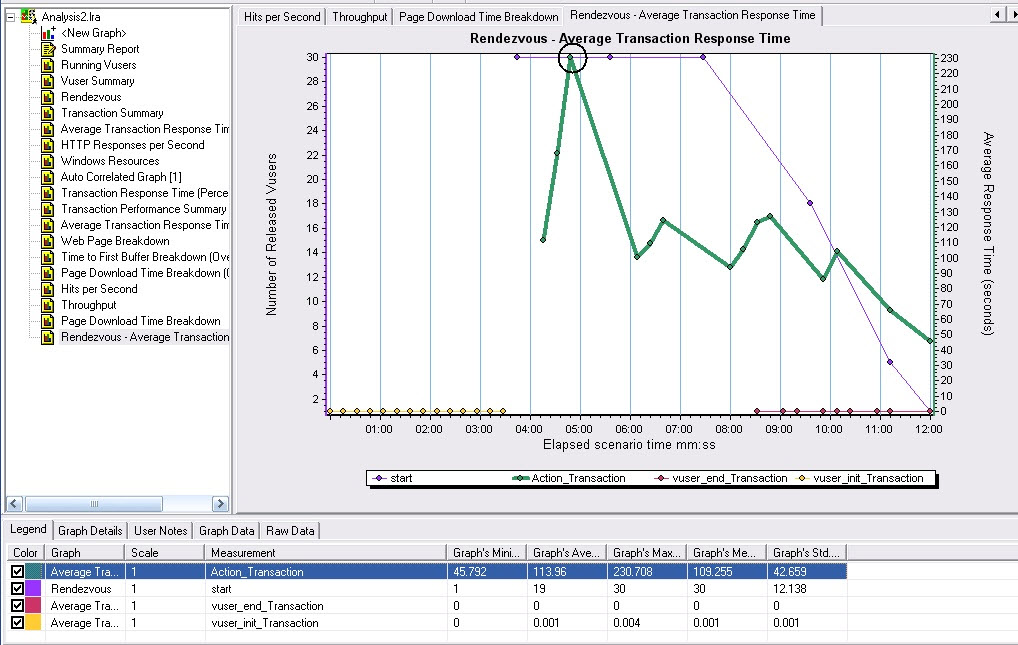
图2
上面图2是集合点与平均事务响应时间的比较图。
注:在打开analysis之后系统LR默认这两个曲线是不在同一张图中的。这就需要自行设置了。具体步骤如下:
点击图上,右键选择merge graphs,然后在select graph to merge with中选择即将用来进行比较的graph。如图3:
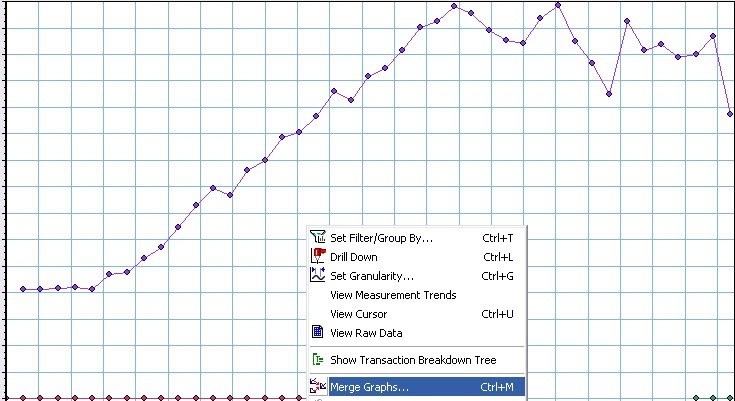
图3
图2中较深颜色的是平均响应时间,浅色的为集合点,当Vuser在集合点持续了1分后平均响应时间呈现最大值,可见用户的并发对系统的性能是一个很大的考验。
接下来看一下与事务有关的参数分析。看下一张图。
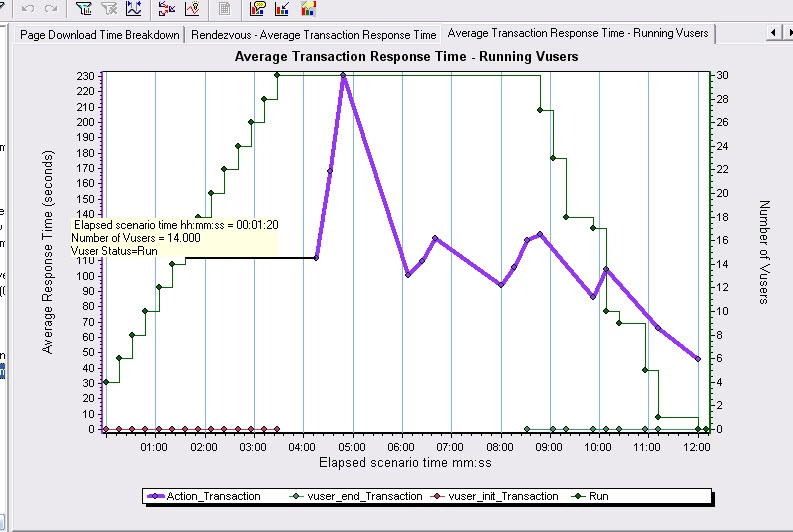
图4
这张图包括Average Transaction Response Time和Running Vuser两个数据图。从图中可以看到Vuser_init_Transaction(系统登录)对系统无任何的影响,Vuser达到15个的时候平均事务响应时间才有明显的升高,也就是说系统达到最优性能的时候允许14个用户同时处理事务,Vuser达到30后1分,系统响应时间最大,那么这个最大响应时间是要推迟1分钟才出现的,在系统稳定之后事务响应时间开始下降说明这个时候有些用户已经执行完了操作。同时也可以看出要想将事务响应时间控制在10S内,Vuser数量最多不能超过2个,看来是很难满足用户的需求了。
做一件事有时候上级会问你这件事办得怎么样了,你会说做完一半了,那么这个一半的事情你花了多少时间呢?所以我们要想知道在给定时间的范围内完成事务的百分比就要靠下面这个图(Transaction Response Time(Percentile))
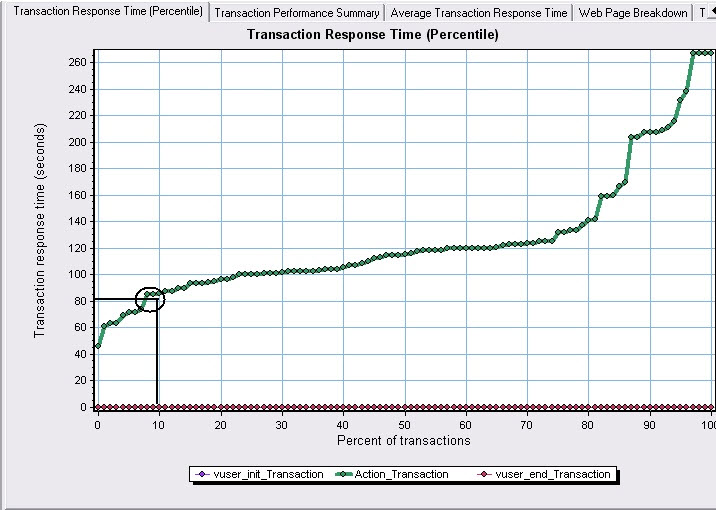
图中画圈的地方表示10%的事务响应时间是在80S左右。80S对于用户来说不是一个很小的数字,而且只有10%的事务,汗!你觉得这个系统性能会好么!
实际工作中遇到的事情不是每一件事都能够在很短的时间内完成的,对于那些需要时间的事情我们就要分配适当的时间处理,时间分配的不均匀就会出现有些事情消耗的时间长一些,有些事情消耗的短一些,但我们自己清楚LR同样也为我们提供了这样的功能,使我们可以了解大部分的事务响应时间是多少,以确定这个系统我们还要付出多少的代价来提高它。
Transaction Response Time(Distribution)-事务响应时间(分布)
显示在方案中执行事务所用时间的分布。如果定义了可以接受的最小和最大事务性能时间,可以通过此图确定服务器性能是否在可接受范围内。
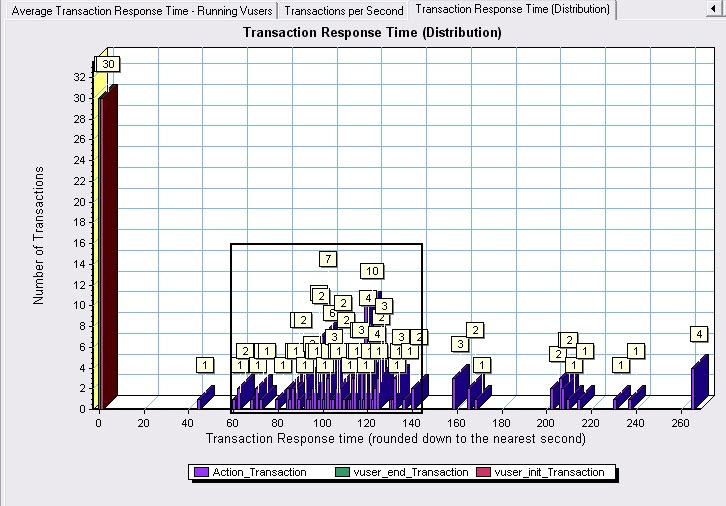
很明显大多数事务的响应时间在60-140S。在我测试过的项目中多数客户所能接受的最大响应时间也要在20S左右。140S的时间很少有人会去花这么多的时间去等待页面的出现吧!
通过观察以上的数据表,我们不难看到此系统在这种环境下并不理想。世间事有果就有因,那么是什么原因导致得系统性能这样差呢?让我们一步一步的分析。
系统性能不好的原因多方面,我们先从应用程序看,有的时候我不得不承认LR的功能真的很强大,这也是我喜欢它的原因。先看一张页面细分图。
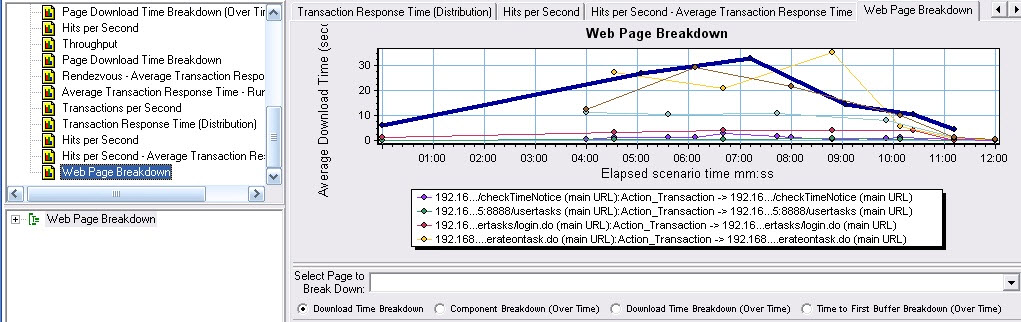
一个应用程序是由很多个组件组成的,整个系统性能不好那我们就把它彻底的剖析一下。图片中显示了整个测试过程中涉及到的所有web页。web page breakdown中显示的是每个页面的下载时间。点选左下角web page breakdown展开,可以看到每个页中包括的css样式表,js脚本,jsp页面等所有的属性。在select page to breakdown中选择页面。见图。
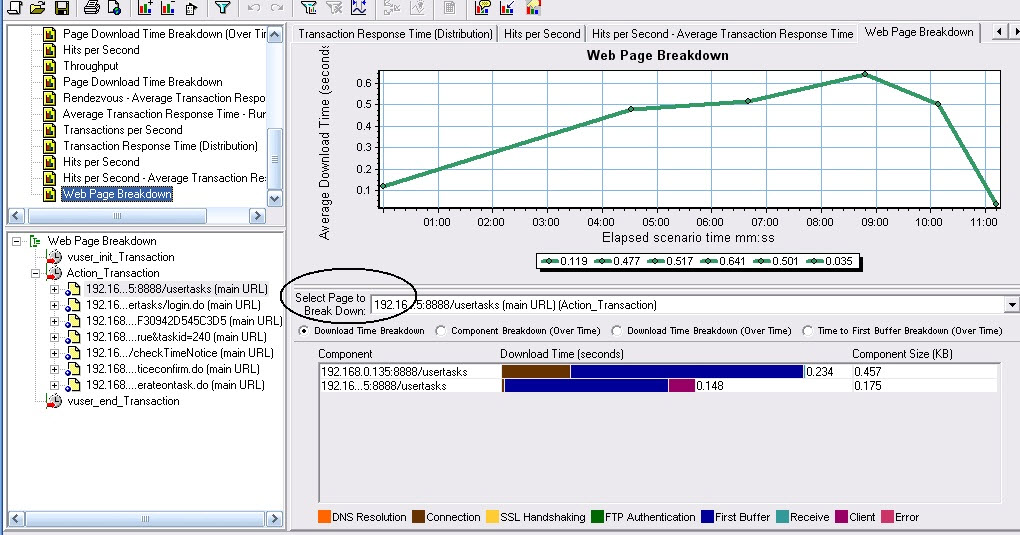
在Select Page To Breakdown 中选择http://192.168.0.135:8888/usertasks后,在下方看到属于它的两个组件,第一行中Connection和First Buffer占据了整个的时间,那么它的消耗时间点就在这里,我们解决问题就要从这里下手。
|
名称 |
描述 |
|
|
显示使用最近的 DNS 服务器将 DNS 名称解析为 IP 地 址所需的时间。“DNS 查找”度量是指示 DNS 解析问 题或 DNS 服务器问题的一个很好的指示器。 |
|
|
显示与包含指定 URL 的 Web 服务器建立初始连接所需 的时间。连接度量是一个很好的网络问题指示器。此 外,它还可表明服务器是否对请求作出响应。 |
|
|
显示从初始 HTTP 请求(通常为 GET)到成功收回来 自 Web 服务器的第一次缓冲时为止所经过的时间。第 一次缓冲度量是很好的 Web 服务器延迟和网络滞后指 示器。 注意:由于缓冲区大小最大为 8K,因此第一次缓冲时 间可能也就是完成元素下载所需的时间。 |
|
|
显示建立 SSL 连接(包括客户端 hello、服务器 hello、客户端公用密钥传输、服务器证书传输和其他 部分可选阶段)所用的时间。自此点之后,客户端与服 务器之间的所有通信都将被加密。 SSL 握手度量仅适用于 HTTPS 通信。 |
|
|
显示从服务器收到最后一个字节并完成下载之前经过的 时间。 “接收”度量是很好的网络质量指示器(查看用来计算 接收速率的时间/ 大小比率)。 |
|
|
显示验证客户端所用的时间。如果使用 FTP,则服务器 在开始处理客户端命令之前,必须验证该客户端。 “FTP 验证”度量仅适用于 FTP 协议通信。 |
|
|
显示因浏览器思考时间或其他与客户端有关的延迟而使 客户机上的请求发生延迟时,所经过的平均时间。 |
|
|
显示从发出 HTTP 请求到返回错误消息(仅限于 HTTP 错误)这期间经过的平均时间。 |




也有可能你的程序中client的时间最长,或者其他的,这些就要根据你自己的测试结果来分析了。下面我们来看一下CPU、内存、硬盘的瓶颈分析方法:
首先我们要监视CPU、内存、硬盘的资源情况,得到以下的参数提供分析的依据。
%processor time(processor_total):消耗的处理器时间数量,如果服务器专用于sql server可接受的最大上限是80% -85 %.也就是常见的CPU使用率。
%User time(processor_total):表示耗费CPU的数据库操作,如排序、执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。
%DPC time(processor_total):越低越好。在多处理器系统中,如果这个值大于50%并且Processor:% Processor Time非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。
%Disk time(physicaldisk_total):指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。
Availiable bytes(memory):用物理内存数. 如果Available Mbytes的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
Context switch/sec(system): (实例化inetinfo 和dllhost 进程) 如果你决定要增加线程字节池的大小,你应该监视这三个计数器(包括上面的一个)。增加线程数可能会增加上下文切换次数,这样性能不会上升反而会下降。如果十个实例的上下文切换值非常高,就应该减小线程字节池的大小。
%Disk reads/sec(physicaldisk_total):每秒读硬盘字节数。
%Disk write/sec(physicaldisk_total):每秒写硬盘字节数。
Page faults/sec:进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
Pages per second:每秒钟检索的页数。该数字应少于每秒一页。
Working set:理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Avg.disk queue length:读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
Average disk read/write queue length: 指读取(写入)请求(列队)的平均数。
Disk reads/(writes)/s:理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
Average disk sec/read:以秒计算的在此盘上读取数据的所需平均时间。
Average disk sec/transfer:指以秒计算的在此盘上写入数据的所需平均时间。
Bytes total/sec:为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
Page read/sec:每秒发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理 I/O 的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。
Page write/sec:(写的页/秒)每秒执行的物理数据库写的页数。
1、判断应用程序的问题
如果系统由于应用程序代码效率低下或者系统结构设计有缺陷而导致大量的上下文切换(context switches/sec显示的上下文切换次数太高)那么就会占用大量的系统资源,如果系统的吞吐量降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高。
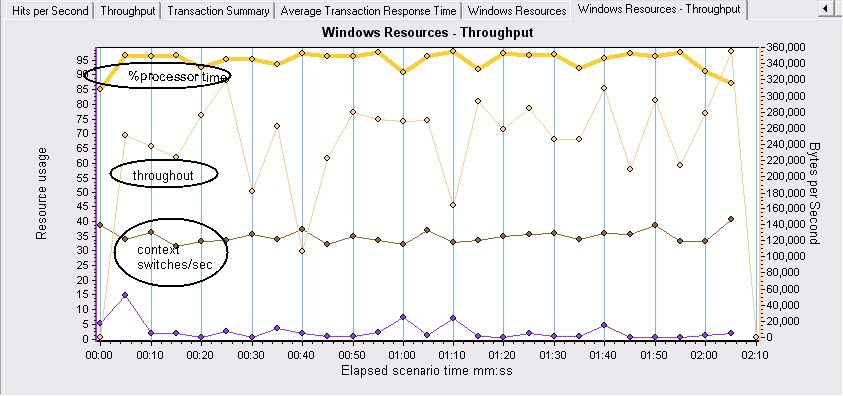
从图的整体看context switches/sec变化不大,throughout曲线的斜率较高,并且此时的context switches/sec已经超过了15000。程序还是需要进一步优化。
2、判断CPU瓶颈
如果processor queue length显示的队列长度保持不变(>=2)个并且处理器的利用率%Processor time超过90%,那么很可能存在处理器瓶颈。如果发现processor queue length显示的队列长度超过2,而处理器的利用率却一直很低,或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈。
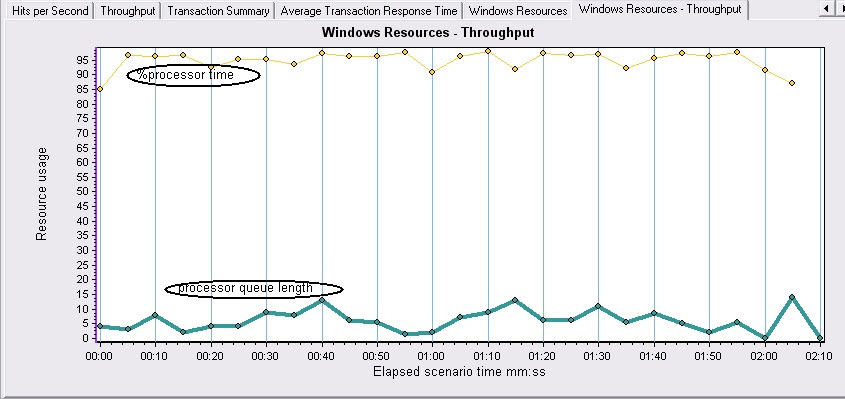
%processor time平均值大于95,processor queue length大于2,可以确定CPU瓶颈,此时的CPU已经不能满足程序需要,急需扩展。
3、判断内存泄露问题
内存问题主要检查应用程序是否存在内存泄漏,如果发生了内存泄漏,process\private bytes计数器和process\working set 计数器的值往往会升高,同时avaiable bytes的值会降低。内存泄漏应该通过一个长时间的用来研究分析所有内存都耗尽时,应用程序反应情况的测试来检验。
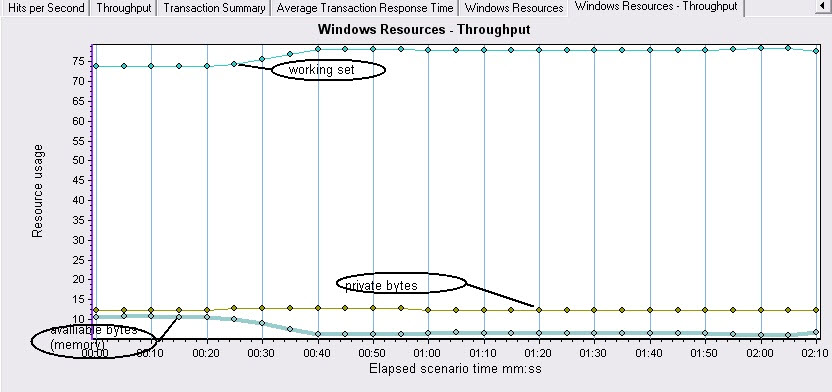
图中可以看到该程序并不存在内存泄露的问题,内存泄露问题经常出现在服务长时间运转的时候,由于部分程序对内存没有释放,而将内存慢慢耗尽。也是提醒大家对系统稳定性测试的关注。
Duration(持续时间):了解该测试过程持续时间。测试人员本身要对这个时期内系统一共做了多少的事有大致的熟悉了解.以确定下次增加更多的任务条件下测试的持续时间。
Statistics Summary(统计摘要):只是大概了解一下测试数据,对我们具体分析没有太大的作用.
Transaction Summary(事务摘要):了解平均响应时间Average单位为秒。
其余的看不看都可以,都不是很重要。
4、分析集合点
在录制脚本中通常我们会使用到集合点,那么既然我们用到了集合点,我们就需要知道Vuser是在什么时候集合在这个点上,又是怎样的一个被释放的过程。这个时候就需要观察Vuser-Rendezvous图。
图1
可以看到大概在3分50的地方30个用户才全部集中到start集合点,持续了3分多,在7分30的位置开始释放用户,9分30还有18个用户,11分10还有5个用户,整个过程持续了12分。
图2
上面图2是集合点与平均事务响应时间的比较图。
注:在打开analysis之后系统LR默认这两个曲线是不在同一张图中的。这就需要自行设置了。具体步骤如下:
点击图上,右键选择merge graphs,然后在select graph to merge with中选择即将用来进行比较的graph。如图3:
图3
图2中较深颜色的是平均响应时间,浅色的为集合点,当Vuser在集合点持续了1分后平均响应时间呈现最大值,可见用户的并发对系统的性能是一个很大的考验。
接下来看一下与事务有关的参数分析。看下一张图。
图4
这张图包括Average Transaction Response Time和Running Vuser两个数据图。从图中可以看到Vuser_init_Transaction(系统登录)对系统无任何的影响,Vuser达到15个的时候平均事务响应时间才有明显的升高,也就是说系统达到最优性能的时候允许14个用户同时处理事务,Vuser达到30后1分,系统响应时间最大,那么这个最大响应时间是要推迟1分钟才出现的,在系统稳定之后事务响应时间开始下降说明这个时候有些用户已经执行完了操作。同时也可以看出要想将事务响应时间控制在10S内,Vuser数量最多不能超过2个,看来是很难满足用户的需求了。
做一件事有时候上级会问你这件事办得怎么样了,你会说做完一半了,那么这个一半的事情你花了多少时间呢?所以我们要想知道在给定时间的范围内完成事务的百分比就要靠下面这个图(Transaction Response Time(Percentile))
图中画圈的地方表示10%的事务响应时间是在80S左右。80S对于用户来说不是一个很小的数字,而且只有10%的事务,汗!你觉得这个系统性能会好么!
实际工作中遇到的事情不是每一件事都能够在很短的时间内完成的,对于那些需要时间的事情我们就要分配适当的时间处理,时间分配的不均匀就会出现有些事情消耗的时间长一些,有些事情消耗的短一些,但我们自己清楚LR同样也为我们提供了这样的功能,使我们可以了解大部分的事务响应时间是多少,以确定这个系统我们还要付出多少的代价来提高它。
Transaction Response Time(Distribution)-事务响应时间(分布)
显示在方案中执行事务所用时间的分布。如果定义了可以接受的最小和最大事务性能时间,可以通过此图确定服务器性能是否在可接受范围内。
很明显大多数事务的响应时间在60-140S。在我测试过的项目中多数客户所能接受的最大响应时间也要在20S左右。140S的时间很少有人会去花这么多的时间去等待页面的出现吧!
通过观察以上的数据表,我们不难看到此系统在这种环境下并不理想。世间事有果就有因,那么是什么原因导致得系统性能这样差呢?让我们一步一步的分析。
系统性能不好的原因多方面,我们先从应用程序看,有的时候我不得不承认LR的功能真的很强大,这也是我喜欢它的原因。先看一张页面细分图。
一个应用程序是由很多个组件组成的,整个系统性能不好那我们就把它彻底的剖析一下。图片中显示了整个测试过程中涉及到的所有web页。web page breakdown中显示的是每个页面的下载时间。点选左下角web page breakdown展开,可以看到每个页中包括的css样式表,js脚本,jsp页面等所有的属性。在select page to breakdown中选择页面。见图。
在Select Page To Breakdown 中选择http://192.168.0.135:8888/usertasks后,在下方看到属于它的两个组件,第一行中Connection和First Buffer占据了整个的时间,那么它的消耗时间点就在这里,我们解决问题就要从这里下手。
|
名称 |
描述 |
|
|
显示使用最近的 DNS 服务器将 DNS 名称解析为 IP 地 址所需的时间。“DNS 查找”度量是指示 DNS 解析问 题或 DNS 服务器问题的一个很好的指示器。 |
|
|
显示与包含指定 URL 的 Web 服务器建立初始连接所需 的时间。连接度量是一个很好的网络问题指示器。此 外,它还可表明服务器是否对请求作出响应。 |
|
|
显示从初始 HTTP 请求(通常为 GET)到成功收回来 自 Web 服务器的第一次缓冲时为止所经过的时间。第 一次缓冲度量是很好的 Web 服务器延迟和网络滞后指 示器。 注意:由于缓冲区大小最大为 8K,因此第一次缓冲时 间可能也就是完成元素下载所需的时间。 |
|
|
显示建立 SSL 连接(包括客户端 hello、服务器 hello、客户端公用密钥传输、服务器证书传输和其他 部分可选阶段)所用的时间。自此点之后,客户端与服 务器之间的所有通信都将被加密。 SSL 握手度量仅适用于 HTTPS 通信。 |
|
|
显示从服务器收到最后一个字节并完成下载之前经过的 时间。 “接收”度量是很好的网络质量指示器(查看用来计算 接收速率的时间/ 大小比率)。 |
|
|
显示验证客户端所用的时间。如果使用 FTP,则服务器 在开始处理客户端命令之前,必须验证该客户端。 “FTP 验证”度量仅适用于 FTP 协议通信。 |
|
|
显示因浏览器思考时间或其他与客户端有关的延迟而使 客户机上的请求发生延迟时,所经过的平均时间。 |
|
|
显示从发出 HTTP 请求到返回错误消息(仅限于 HTTP 错误)这期间经过的平均时间。 |
也有可能你的程序中client的时间最长,或者其他的,这些就要根据你自己的测试结果来分析了。下面我们来看一下CPU、内存、硬盘的瓶颈分析方法:
首先我们要监视CPU、内存、硬盘的资源情况,得到以下的参数提供分析的依据。
%processor time(processor_total):消耗的处理器时间数量,如果服务器专用于sql server可接受的最大上限是80% -85 %.也就是常见的CPU使用率。
%User time(processor_total):表示耗费CPU的数据库操作,如排序、执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。
%DPC time(processor_total):越低越好。在多处理器系统中,如果这个值大于50%并且Processor:% Processor Time非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。
%Disk time(physicaldisk_total):指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。
Availiable bytes(memory):用物理内存数. 如果Available Mbytes的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
Context switch/sec(system): (实例化inetinfo 和dllhost 进程) 如果你决定要增加线程字节池的大小,你应该监视这三个计数器(包括上面的一个)。增加线程数可能会增加上下文切换次数,这样性能不会上升反而会下降。如果十个实例的上下文切换值非常高,就应该减小线程字节池的大小。
%Disk reads/sec(physicaldisk_total):每秒读硬盘字节数。
%Disk write/sec(physicaldisk_total):每秒写硬盘字节数。
Page faults/sec:进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
Pages per second:每秒钟检索的页数。该数字应少于每秒一页。
Working set:理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Avg.disk queue length:读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
Average disk read/write queue length: 指读取(写入)请求(列队)的平均数。
Disk reads/(writes)/s:理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
Average disk sec/read:以秒计算的在此盘上读取数据的所需平均时间。
Average disk sec/transfer:指以秒计算的在此盘上写入数据的所需平均时间。
Bytes total/sec:为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
Page read/sec:每秒发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理 I/O 的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。
Page write/sec:(写的页/秒)每秒执行的物理数据库写的页数。
1、判断应用程序的问题
如果系统由于应用程序代码效率低下或者系统结构设计有缺陷而导致大量的上下文切换(context switches/sec显示的上下文切换次数太高)那么就会占用大量的系统资源,如果系统的吞吐量降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高。
从图的整体看context switches/sec变化不大,throughout曲线的斜率较高,并且此时的context switches/sec已经超过了15000。程序还是需要进一步优化。
2、判断CPU瓶颈
如果processor queue length显示的队列长度保持不变(>=2)个并且处理器的利用率%Processor time超过90%,那么很可能存在处理器瓶颈。如果发现processor queue length显示的队列长度超过2,而处理器的利用率却一直很低,或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈。
%processor time平均值大于95,processor queue length大于2,可以确定CPU瓶颈,此时的CPU已经不能满足程序需要,急需扩展。
3、判断内存泄露问题
内存问题主要检查应用程序是否存在内存泄漏,如果发生了内存泄漏,process\private bytes计数器和process\working set 计数器的值往往会升高,同时avaiable bytes的值会降低。内存泄漏应该通过一个长时间的用来研究分析所有内存都耗尽时,应用程序反应情况的测试来检验。
图中可以看到该程序并不存在内存泄露的问题,内存泄露问题经常出现在服务长时间运转的时候,由于部分程序对内存没有释放,而将内存慢慢耗尽。也是提醒大家对系统稳定性测试的关注。
看完打开支付宝扫一扫领个红包吧!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号