


OO第三单元作业总结
OO第三单元作业总结
一、JML理论及工具链应用
1.注释结构
有两种注释方式,行注释和块注释。
- 行注释://@annotation
- 块注释:/* @ annotation @*/
2.JML表达式
2.1原子表达式
- \result表达式:表示一个非void类型的方法执行后的返回值;
- \old(expr)表达式:表示一个表达式执行该方法前的值;
- \not_assigned(x,y,...)表达式:用来表示在执行过程中括号内的变量是否被赋值;
- \not_modified(x,y,...)表达式:表示括号内的变量的值是否被改变;
- \nonnullelements( container )表达式:表示容器中存储对象不包含null;
- \type(type)表达式:返回类型type对应的类型(Class);
- \typeof(expr)表达式:该表达式返回expr对应的准确类型。
2.2量化表达式
- \forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束;
- \exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束;
- \sum表达式:返回给定范围内的表达式的和;
- \product表达式:返回给定范围内的表达式的连乘结果;
- \max表达式:返回给定范围内的表达式的最大值;
- \min表达式:返回给定范围内的表达式的最小值;
- \num_of表达式:返回指定变量中满足相应条件的取值个数。
2.3集合表达式
可以在JML规格中构造一个局部的集合,并明确集合中包含的元素。
2.4操作符
- 子类型关系操作符: E1<:E2;
- 等价关系操作符: b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2;
- 推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1;
- 变量引用操作符:除了可以直接引用Java代码或者JML规格中定义的变量外,JML还提供了几个概括性的关键词来 引用相关的变量。\nothing指示一个空集;\everything指示一个全集。
3.方法规格
- 前置条件(pre-condition)
前置条件通过requires子句来表示: requires P; 。其中requires是JML关键词,表达的意思是“要求调用者确保P为 真”。
- 后置条件(post-condition)
后置条件通过ensures子句来表示: ensures P; 。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执 行返回结果一定满足谓词P的要求,即确保P为真”。
- 副作用范围限定(side-effects)
副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。
- signals子句
signals子句的结构为 signals (***Exception e) b_expr ,意思是当 b_expr 为 true 时,方法会抛出括号中给出 的相应异常e。
4.类型规格
- 不变式invariant
不变式是指在所有可见状态下都必须满足的特性,可见状态是一种特殊概念,以下几种情形被定义为可见状态:
-
- 对象的有状态构造方法(用来初始化对象成员变量初值)的执行结束时刻
- 在调用一个对象回收方法(finalize方法)来释放相关资源开始的时刻
- 在调用对象o的非静态、有状态方法(non-helper)的开始和结束时刻
- 在调用对象o对应的类或父类的静态、有状态方法的开始和结束时刻
- 在未处于对象o的构造方法、回收方法、非静态方法被调用过程中的任意时刻
- 在未处于对象o对应类或者父类的静态方法被调用过程中的任意时刻
- 状态变化约束constraint
对象的状态在变化时也需要满足的一些约束。
5.JML工具链
- 使用OpenJML对代码进行检查,支持JML语法静态检查,代码静态检查,运行时检查,在出现违规时会抛出异常并反馈错误信息。
- 使用JMLUnitNG根据JML语言自动生成测试数据进行测试,测试主要针对边缘数据进行。
二、部署JMLUnitNG/JMLUnit并应用
1.JMLUnitNG的使用
这里使用了简单的代码来尝试JMLUnitNG的使用,使用的代码如下:
package demo; public class Demo { /*@ public normal_behaviour @ ensures (x > y) ==> \result == 1; @ ensures (x == y) ==> \result == 0; @ ensures (x < y) ==> \result == -1; */ public static int compare(int x, int y) { if (x > y) { return 1; } else { if (x == y) { return 0; } else { return -1; } } } public static void main(String[] args) { compare(1234,2234); } }
代码完成了一个简单的compare方法,并通过了OpenJML检查,使用JMLUnitNG检查的结果如下: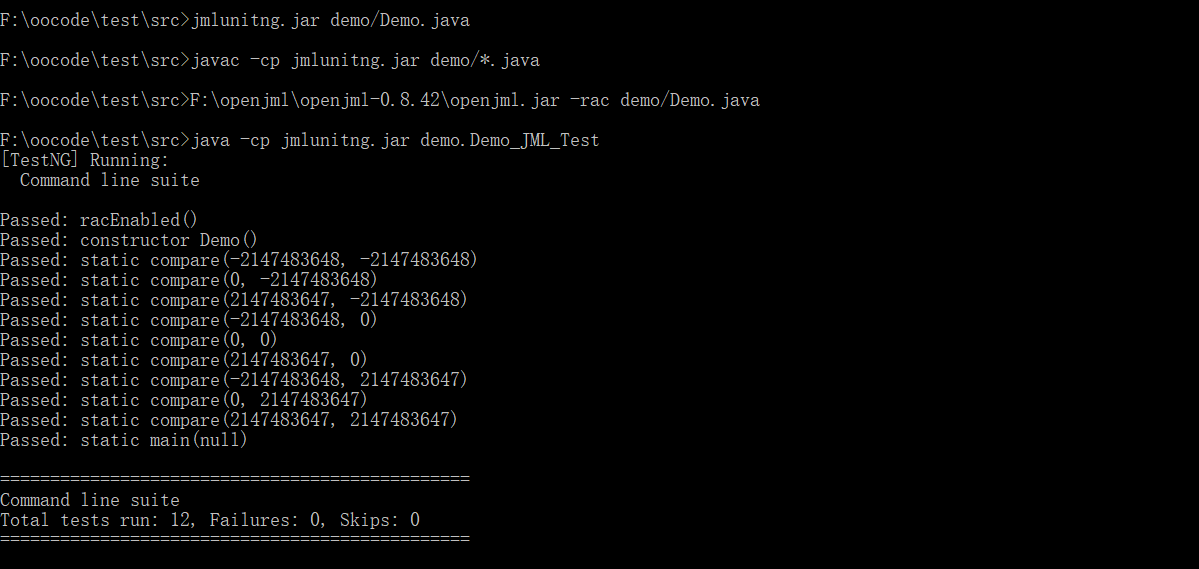
可以看到,其主要构造边界数据来完成分支覆盖并检查正确性。
2.JMLUnit的使用
JMLUnit主要针对于单元检查,同过自己构造数据来完成对特定方法的语句检查和分支覆盖。
三、架构设计与重构分析
1.第一次作业
1.1架构设计
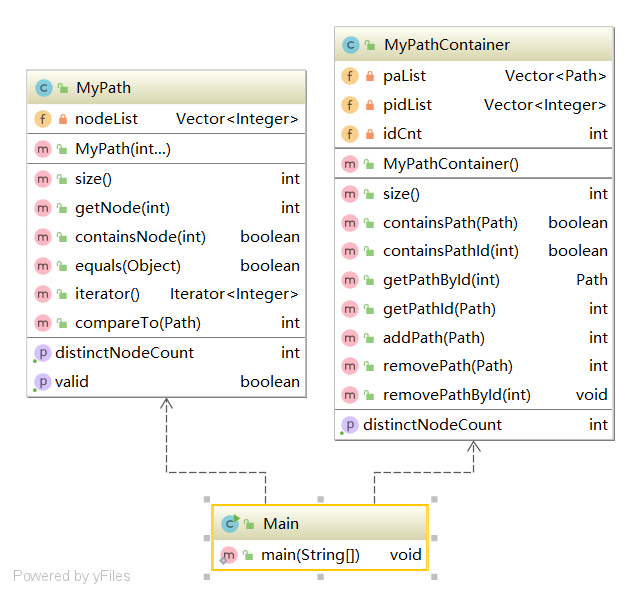
1.2复杂度分析
| method | ev(G) | iv(G) | v(G) |
| path.Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| path.MyPath.compareTo(Path) | 4.0 | 2.0 | 4.0 |
| path.MyPath.containsNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.equals(Object) | 5.0 | 2.0 | 6.0 |
| path.MyPath.getDistinctNodeCount() | 1.0 | 3.0 | 3.0 |
| path.MyPath.getNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.isValid() | 1.0 | 1.0 | 1.0 |
| path.MyPath.iterator() | 1.0 | 1.0 | 1.0 |
| path.MyPath.MyPath(int...) | 1.0 | 2.0 | 2.0 |
| path.MyPath.size() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.addPath(Path) | 2.0 | 3.0 | 4.0 |
| path.MyPathContainer.containsPath(Path) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.containsPathId(int) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getDistinctNodeCount() | 1.0 | 4.0 | 4.0 |
| path.MyPathContainer.getPathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.getPathId(Path) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.MyPathContainer() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.removePath(Path) | 2.0 | 3.0 | 4.0 |
| path.MyPathContainer.removePathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.size() | 1.0 | 1.0 | 1.0 |
| Total | 32.0 | 32.0 | 43.0 |
| Average | 1.6 | 1.6 | 2.15 |
1.3设计思路
本次的规格作业比较简单,没有什么复杂的地方,设计上只需要按照规格完成即可。但在统计不同的点的个数时,需要存储结果来避免重复计算从而导致的超时问题。
2.第二次作业
2.1架构设计
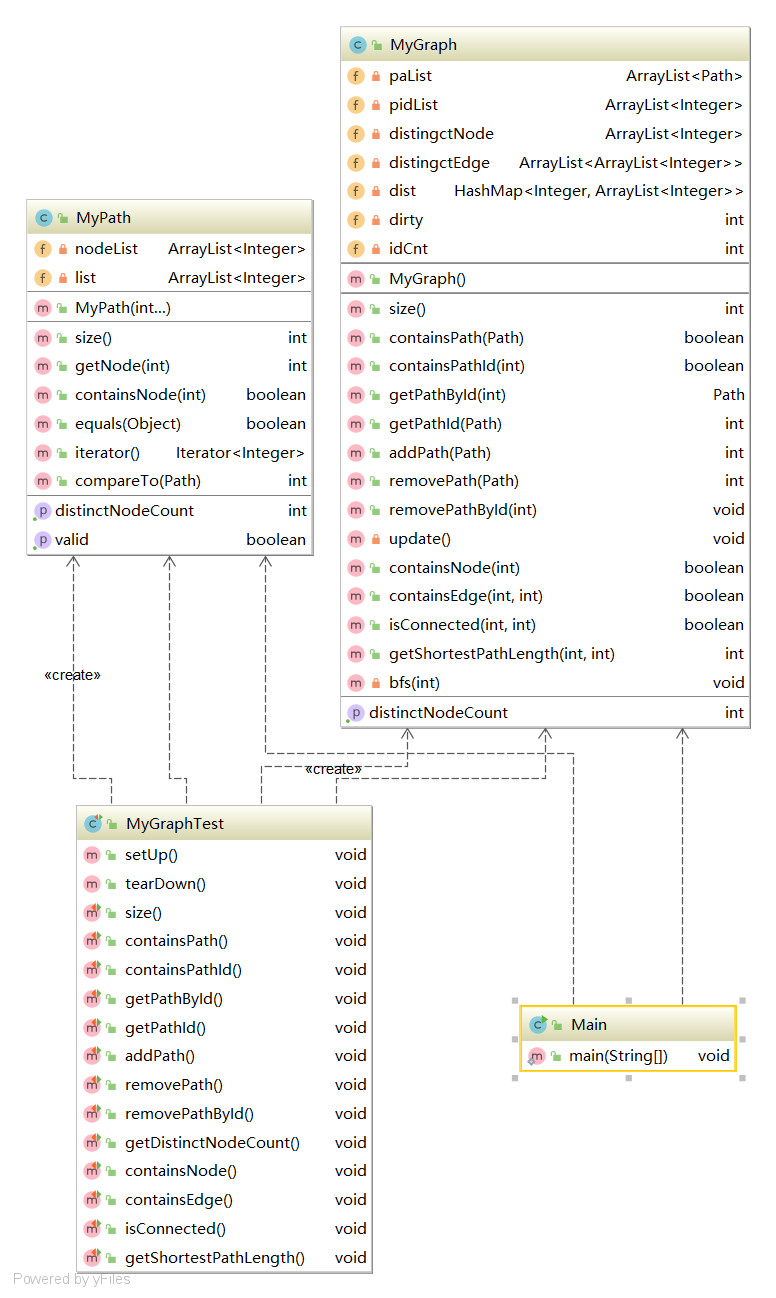
2.2复杂度分析
| method | ev(G) | iv(G) | v(G) |
| path.Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| path.MyGraph.addPath(Path) | 2.0 | 8.0 | 9.0 |
| path.MyGraph.bfs(int) | 1.0 | 5.0 | 5.0 |
| path.MyGraph.containsEdge(int,int) | 2.0 | 3.0 | 4.0 |
| path.MyGraph.containsNode(int) | 1.0 | 2.0 | 2.0 |
| path.MyGraph.containsPath(Path) | 1.0 | 1.0 | 1.0 |
| path.MyGraph.containsPathId(int) | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getDistinctNodeCount() | 1.0 | 2.0 | 2.0 |
| path.MyGraph.getPathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyGraph.getPathId(Path) | 2.0 | 1.0 | 2.0 |
| path.MyGraph.getShortestPathLength(int,int) | 5.0 | 2.0 | 5.0 |
| path.MyGraph.isConnected(int,int) | 5.0 | 4.0 | 6.0 |
| path.MyGraph.MyGraph() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.removePath(Path) | 2.0 | 3.0 | 4.0 |
| path.MyGraph.removePathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyGraph.size() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.update() | 1.0 | 6.0 | 6.0 |
| path.MyGraphTest.addPath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsEdge() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsNode() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsPath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsPathId() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getDistinctNodeCount() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getPathById() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getPathId() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getShortestPathLength() | 1.0 | 10.0 | 12.0 |
| path.MyGraphTest.isConnected() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.removePath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.removePathById() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.setUp() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.size() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.tearDown() | 1.0 | 1.0 | 1.0 |
| path.MyPath.compareTo(Path) | 4.0 | 2.0 | 4.0 |
| path.MyPath.containsNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.equals(Object) | 5.0 | 2.0 | 6.0 |
| path.MyPath.getDistinctNodeCount() | 1.0 | 1.0 | 1.0 |
| path.MyPath.getNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.isValid() | 1.0 | 1.0 | 1.0 |
| path.MyPath.iterator() | 1.0 | 1.0 | 1.0 |
| path.MyPath.MyPath(int...) | 1.0 | 3.0 | 3.0 |
| path.MyPath.size() | 1.0 | 1.0 | 1.0 |
| Total | 62.0 | 80.0 | 99.0 |
| Average | 1.51 | 1.95 | 2.41 |
2.3设计思路
在本次作业中,较好的方法是Graph继承上次的PathContainer,并进一步扩展新增的功能。相比于上次的作业,本次规格中增加了边的概念,并引进了距离,进而增加了两点间距离的查询。由于本次图结构更改指令很少,所以可以建立一个缓存机制,将中间计算到的结果保存下来,在查询时先在缓存中查找,没有的话再进行bfs计算。对于本次边的存储,采用了邻接表的方法,该方法对于特定边的查询复杂度为O(1),具有较好的性能。总体来说,此次作业难度不大,但由于在增加路径时存在bug,导致在强测中表现不好。
3.第三次作业
3.1架构设计
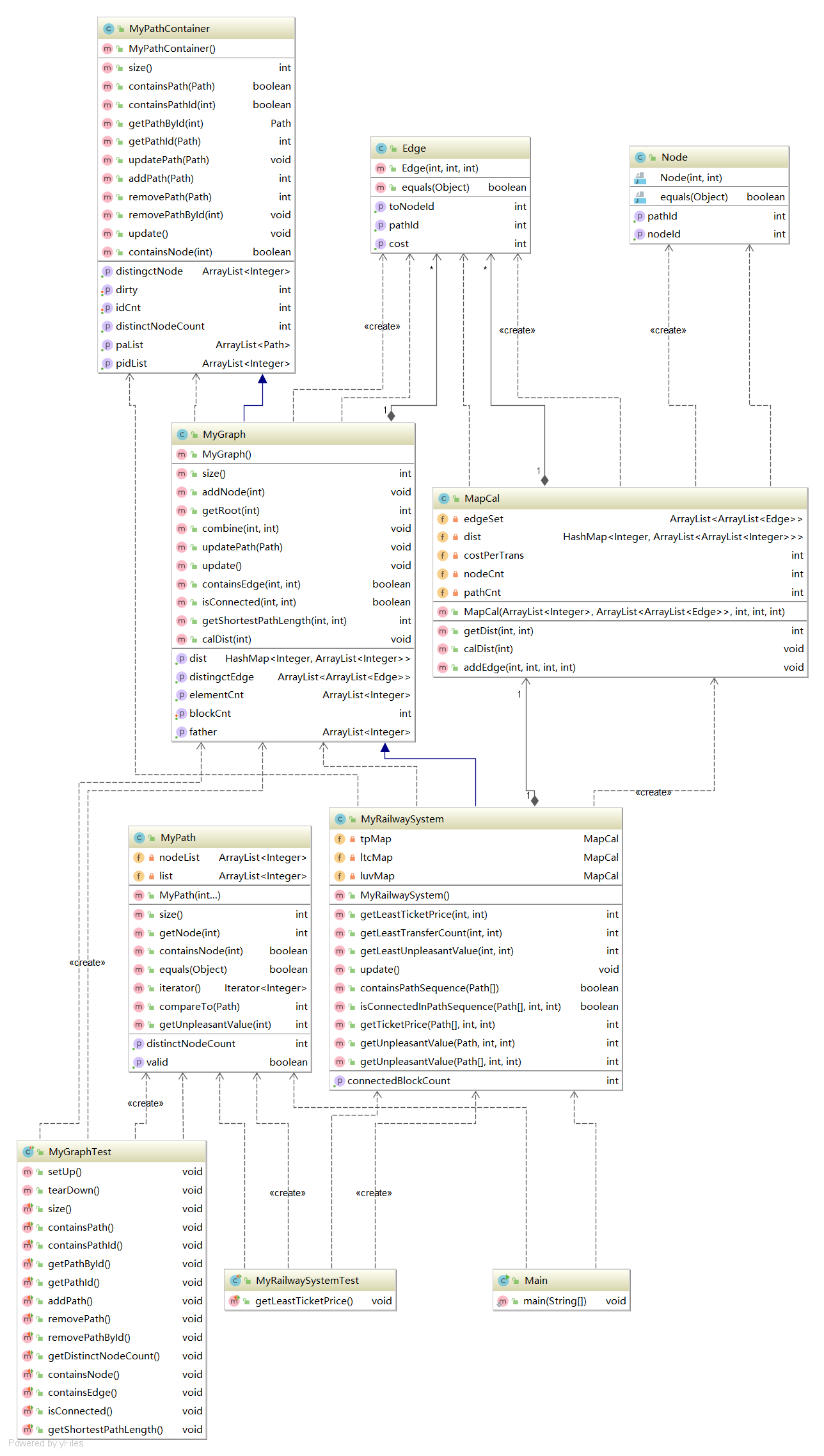
3.2复杂度分析
| method | ev(G) | iv(G) | v(G) |
| path.Edge.Edge(int,int,int) | 1.0 | 1.0 | 1.0 |
| path.Edge.equals(Object) | 2.0 | 1.0 | 2.0 |
| path.Edge.getCost() | 1.0 | 1.0 | 1.0 |
| path.Edge.getPathId() | 1.0 | 1.0 | 1.0 |
| path.Edge.getToNodeId() | 1.0 | 1.0 | 1.0 |
| path.Main.main(String[]) | 1.0 | 1.0 | 1.0 |
| path.MapCal.addEdge(int,int,int,int) | 1.0 | 1.0 | 1.0 |
| path.MapCal.calDist(int) | 1.0 | 9.0 | 10.0 |
| path.MapCal.getDist(int,int) | 3.0 | 6.0 | 6.0 |
| path.MapCal.MapCal(ArrayList,ArrayList<arraylist>,int,int,int) | 1.0 | 4.0 | 4.0 |
| path.MyGraph.addNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyGraph.calDist(int) | 1.0 | 5.0 | 5.0 |
| path.MyGraph.combine(int,int) | 1.0 | 2.0 | 2.0 |
| path.MyGraph.containsEdge(int,int) | 2.0 | 3.0 | 4.0 |
| path.MyGraph.getBlockCnt() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getDist() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getDistingctEdge() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getElementCnt() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getFather() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.getRoot(int) | 2.0 | 2.0 | 2.0 |
| path.MyGraph.getShortestPathLength(int,int) | 4.0 | 2.0 | 5.0 |
| path.MyGraph.isConnected(int,int) | 3.0 | 2.0 | 4.0 |
| path.MyGraph.MyGraph() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.setBlockCnt(int) | 1.0 | 1.0 | 1.0 |
| path.MyGraph.size() | 1.0 | 1.0 | 1.0 |
| path.MyGraph.update() | 1.0 | 2.0 | 2.0 |
| path.MyGraph.updatePath(Path) | 1.0 | 6.0 | 6.0 |
| path.MyGraphTest.addPath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsEdge() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsNode() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsPath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.containsPathId() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getDistinctNodeCount() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getPathById() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getPathId() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.getShortestPathLength() | 1.0 | 10.0 | 12.0 |
| path.MyGraphTest.isConnected() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.removePath() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.removePathById() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.setUp() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.size() | 1.0 | 1.0 | 1.0 |
| path.MyGraphTest.tearDown() | 1.0 | 1.0 | 1.0 |
| path.MyPath.compareTo(Path) | 4.0 | 2.0 | 4.0 |
| path.MyPath.containsNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.equals(Object) | 5.0 | 2.0 | 6.0 |
| path.MyPath.getDistinctNodeCount() | 1.0 | 1.0 | 1.0 |
| path.MyPath.getNode(int) | 1.0 | 1.0 | 1.0 |
| path.MyPath.getUnpleasantValue(int) | 2.0 | 2.0 | 2.0 |
| path.MyPath.isValid() | 1.0 | 1.0 | 1.0 |
| path.MyPath.iterator() | 1.0 | 1.0 | 1.0 |
| path.MyPath.MyPath(int...) | 1.0 | 3.0 | 3.0 |
| path.MyPath.size() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.addPath(Path) | 2.0 | 3.0 | 4.0 |
| path.MyPathContainer.containsNode(int) | 1.0 | 2.0 | 2.0 |
| path.MyPathContainer.containsPath(Path) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.containsPathId(int) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getDirty() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getDistinctNodeCount() | 1.0 | 2.0 | 2.0 |
| path.MyPathContainer.getDistingctNode() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getIdCnt() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getPaList() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.getPathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.getPathId(Path) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.getPidList() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.MyPathContainer() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.removePath(Path) | 2.0 | 3.0 | 4.0 |
| path.MyPathContainer.removePathById(int) | 2.0 | 1.0 | 2.0 |
| path.MyPathContainer.setDirty(int) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.setIdCnt(int) | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.size() | 1.0 | 1.0 | 1.0 |
| path.MyPathContainer.update() | 1.0 | 4.0 | 4.0 |
| path.MyPathContainer.updatePath(Path) | 1.0 | 3.0 | 3.0 |
| path.MyRailwaySystem.containsPathSequence(Path[]) | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.getConnectedBlockCount() | 1.0 | 2.0 | 2.0 |
| path.MyRailwaySystem.getLeastTicketPrice(int,int) | 4.0 | 2.0 | 5.0 |
| path.MyRailwaySystem.getLeastTransferCount(int,int) | 4.0 | 2.0 | 5.0 |
| path.MyRailwaySystem.getLeastUnpleasantValue(int,int) | 4.0 | 2.0 | 5.0 |
| path.MyRailwaySystem.getTicketPrice(Path[],int,int) | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.getUnpleasantValue(Path,int,int) | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.getUnpleasantValue(Path[],int,int) | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.isConnectedInPathSequence(Path[],int,int) | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.MyRailwaySystem() | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystem.update() | 1.0 | 1.0 | 1.0 |
| path.MyRailwaySystemTest.getLeastTicketPrice() | 1.0 | 5.0 | 6.0 |
| path.Node.equals(Object) | 2.0 | 1.0 | 3.0 |
| path.Node.getNodeId() | 1.0 | 1.0 | 1.0 |
| path.Node.getPathId() | 1.0 | 1.0 | 1.0 |
| path.Node.Node(int,int) | 1.0 | 1.0 | 1.0 |
| Total | 121.0 | 153.0 | 186.0 |
| Average | 1.37 | 1.73 | 2.11 |
3.3设计分析
在这次的作业中,使用继承机制继承了前次的架构,并在此基础上进行修改。这次引入了新的距离概念,并增加了换乘的cost,对比发现,这三个新的查询请求具有相同的结构——边的cost和换乘的cost,于是就增加了一个计算类,专门用于图的计算,将三个查询分散到三个对象中独立完成,在每次图结构更新后,重新构建三个计算图,并把每次的结果存储在各自的计算图中,最大限度的降低耦合。对于新增的查询连通块的请求,使用带路径压缩的并查集即可完成,实现起来也很简单。
此次作业比较坑的一个地方在于,并不能简单的使用单源最短路算法来计算最少代价,这是因为换乘的存在导致当前的最优解不一定能推出后续的最优解,因此,应该将所有的点拆成和路径条数相同的子点,利用这些子点进行计算,并返回所有子点中代价最小的值。
四、bug分析
第一次作业中无bug出现,问题在于复杂度过高,导致超时,引入缓存机制后即可解决。
第二次作业中存在一个严重bug,在增加路径时,如果增加了一条已存在路径,那么会导致返回值错误,违反了规格的描述。在修改时,修改返回的值即可。出现这个问题的原因在于测试不够充分,没有对代码进行足够充分的测试,应该引以为戒。
第三次作业中不存在bug。
五、心得和体会
为了更好地描述一个方法,引入了JML,按照规范的语言描述了方法的内容,要求是什么,会修改什么,会返回什么,异常处理是什么。使用这种没有二义性的方式去描述代码更加有利于多人协作,对于开发项目的正确性有极大的积极作用,并有效避免了bug的出现。
JML提供了规范的描述语言,而各种JML工具提供了针对于JML语言的形式化验证方法,对于书写正确规范的JML语言提供了很大的帮助。
在架构设计方面,继承和接口的合理使用会极大地提高代码的可读性和可拓展性,对于增加新功能或原有功能进行修改有很大的便利。对于一些功能相近的方法,应进行封装和解耦,降低耦合度,从而利于维护和修改。缓存机制的合理使用会极大地提高代码的运行效率,充分利用中间结果也会很大程度的优化求解过程。
以及充分测试代码的必要性……
