
MyBatis学习笔记
PO, BO,VO,POJO的关系和区别
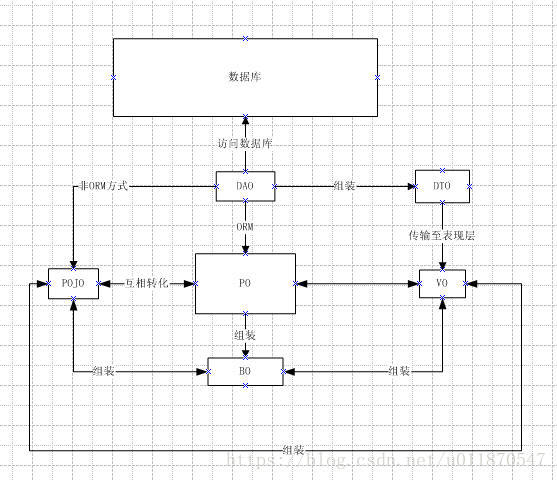
PO:persistent object 持久对象
1 .有时也被称为Data对象,对应数据库中的entity,可以简单认为一个PO对应数据库中的一条记录。
2 .在hibernate持久化框架中与insert/delet操作密切相关。
3 .PO中不应该包含任何对数据库的操作。
POJO :plain ordinary java object 无规则简单java对象
一个中间对象,可以转化为PO、DTO、VO。
1 .POJO持久化之后==〉PO
(在运行期,由Hibernate中的cglib动态把POJO转换为PO,PO相对于POJO会增加一些用来管理数据库entity状态的属性和方法。PO对于programmer来说完全透明,由于是运行期生成PO,所以可以支持增量编译,增量调试。)
2 .POJO传输过程中==〉DTO
3 .POJO用作表示层==〉VO
PO 和VO都应该属于它。
BO:business object 业务对象
业务对象主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。
比如一个简历,有教育经历、工作经历、社会关系等等。我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。
建立一个对应简历的BO对象处理简历,每个BO包含这些PO。
这样处理业务逻辑时,我们就可以针对BO去处理。
封装业务逻辑为一个对象(可以包括多个PO,通常需要将BO转化成PO,才能进行数据的持久化,反之,从DB中得到的PO,需要转化成BO才能在业务层使用)。
关于BO主要有三种概念
1 、只包含业务对象的属性;
2 、只包含业务方法;
3 、两者都包含。
在实际使用中,认为哪一种概念正确并不重要,关键是实际应用中适合自己项目的需要。
VO:value object 值对象 / view object 表现层对象
1 .主要对应页面显示(web页面/swt、swing界面)的数据对象。
2 .可以和表对应,也可以不,这根据业务的需要。
DTO(TO):Data Transfer Object 数据传输对象
1 .用在需要跨进程或远程传输时,它不应该包含业务逻辑。
2 .比如一张表有100个字段,那么对应的PO就有100个属性(大多数情况下,DTO内的数据来自多个表)。但view层只需显示10个字段,没有必要把整个PO对象传递到client,这时我们就可以用只有这10个属性的DTO来传输数据到client,这样也不会暴露server端表结构。到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO。
DAO:data access object数据访问对象
1 .主要用来封装对DB的访问(CRUD操作)。
2 .通过接收Business层的数据,把POJO持久化为PO。
简易的关系图:
对于写配置文件的MyBatis来说,整个Mapper文件是这样的:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace:命名空间,用于隔离SQL语句,后继有重要作用-->
<!--动态代理开发规则
1.namespace必须是接口的全路径名
2.接口的方法名必须与SQL ID一致
3.接口的入参必须与parameterType类型一致
4.接口的返回值必须与resultType类型一致
-->
<!--
id:语句的唯一标示
parameterType:入参的数据类型
resultType:返回结果的数据类型
#{}:点位符,相当于jdbc的?,里面写个传入对象的属性名字就好
${}:字符串拼接指令,如果入参为普通数据类型,括号内只能写value
-->
<mapper namespace="cn.gaolei.mapper.OrderMapper">
<!--resultMap的入门,type是映射的类的别名-->
<!--resultMap代表的是自己编写的一种返回类型,比如说他返回的
不是一种固定的对象映射,而是自己要拼接组合出来的一种类型,
那么就使用resultMap来配置,id是resultMap的名字,type是resultMap实际返回的类型-->
<resultMap id="order_list_map" type="order">
<!--配置主键,ID用于映射主键-->
<!--property是对应的类的属性名,而column是对应的列名-->
<id property="id" column="id"/>
<!--普通字段用result映射-->
<result property="userId" column="user_id"/>
<result property="number" column="number"/>
<result property="createtime" column="createtime"/>
<result property="note" column="note"/>
</resultMap>
<resultMap id="order_user_map" type="order">
<id property="id" column="id"/>
<result property="userId" column="user_id"/>
<result property="number" column="number"/>
<result property="createtime" column="createtime"/>
<result property="note" column="note"/>
<!--association用于配置一对一关系,property是要映射的属性,javaType是类的数据类型,支持别名(别名默认是类名的首字母小写),column
是数据库表的列名 select 表示执行一条查询语句,将查询到的数据封装到property所代表的类型对象上(当然这条语句也要自己写)-->
<association property="user" javaType="cn.gaolei.pojo.User" column = "user_id" select = "selectUserWithId">
<id property="id" column="user_id"/>
<result property="username" column="username"/>
<result property="address" column="address"/>
<result property="sex" column="sex"/>
<result property="birthday" column="birthday"/>
</association>
</resultMap>
<!--使用resultmap,这条查询语句,对于接口中的方法来说,返回结果不是resultMap,而是一个list,list里面封装的是resultMap.-->
<!--关于一对多的封装,请看下一段代码-->
<select id="getOrderListMap" resultMap="order_list_map">
select * from `order`;
</select>
<!--我们的select标签,同理还有insert, update, delete, sql, cache,
cache-ref, resultMap 标签-->
<!--这里的id要和mapper接口里的方法名完全一致-->
<!--标签还会有其他参数,比如:parameterType 传入参数的完全限定名,这个参
数是可选的-->
<!--还有比如-->
<!--resultType 返回结果的类型,如果正好是个类的话,mybatis会自动把列
映射到类的属性上面去-->
<select id="getOrderList" resultType="order">
select * from `order`;
</select>
<select id="getOrderUser" resultType="orderuser">
select
o.id,o.number,o.createtime,o.note,u.username,u.address,u.id
from `order` o left join `user` u on o.user_id=u.id;
</select>
<select id="getOrderUserMap" resultMap="order_user_map">
select
o.id,o.user_id,o.number,o.createtime,o.note,u.username,u.address,u.sex,u.birthday
from `order` o left join `user` u on o.user_id=u.id;
</select>
<!--sql标签就是一段代码段,id就是这段代码段的名字,$(prefix)是个占位符,使用这段代码段的时候,可以把占位符换成其他的内容.-->
<sql id = "userColumns">
${prefix}.id, ${prefix}.username, ${prefix}.address from
</sql>
<!--使用sql片段,片段要用include标签来引用,refid的值就是你要引用的sql片段的id,property标签用来把sql片段中的占位符(name)换成实际的值(value)-->
<select>
select
<include refid = "userColumns">
<property name = "prefix" value = "user" />
</include>
`user`
</select>
</mapper>
关于一对多的使用以及其他标签,请看这里
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.gaolei.mapper.UserMapper">
<resultMap id="user_order_map" type="user">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="address" column="address"/>
<result property="sex" column="sex"/>
<result property="birthday" column="birthday"/>
<!--一对多,用collection,property是对应的多的那一方的属性名,ofType是属性对
应的集合当中的类的名称,支持别名 javaType表示该属性对应的类型名称.
column 是表示使用Oid作为参数进行后面的select语句查询
select 是表示执行一条查询语句,将查询到的结果封装到property所代表的类型对象当中(当然
这个查询语句要自己写) fetchType表示的是加载类型,有立即加载,eager和延迟加载lazy.一般使
用lazy性能会提高.不过mybatis要打开相应的设置才可以.不然没用-->
<collection property="orders" ofType="cn.gaolei.pojo.Order" javaType = "ArrayList"
column = "oid" select = "selectOrdersByOid" fetchType = "lazy">
<!--配置主键,ID用于映射主键-->
<id property="id" column="oid"/>
<!--普通字段用result映射-->
<result property="userId" column="user_id"/>
<result property="number" column="number"/>
<result property="createtime" column="createtime"/>
<result property="note" column="note"/>
</collection>
</resultMap>
<!--sql片段的抽取,定义-->
<sql id="user_sql">
select * from
</sql>
<select id="getUserById" parameterType="int" resultType="cn.gaolei.pojo.User">
<!--引用定义好的SQL片段,见上方-->
<!--这里的#{}也是一种占位符,他会直接从你传入方法的参数里找.如果传入的是一个POJO,那么
他会找对象的对应名字的属性来映射上去-->
<include refid="user_sql"/>
user where id=#{id2};
</select>
<!--
虽然返回的是集合,但是结果类型写单个元素的足矣
-->
<select id="getUserByUserName" parameterType="string" resultType="cn.gaolei.pojo.User">
select * from user where username like '%${value}%';
</select>
<!--if标签的使用,if标签用于条件判断-->
<select id="getUserByPojo" parameterType="user" resultType="cn.gaolei.pojo.User">
select * from user
<!--where标签自动补上where关键字,同时处理多余的and字符-->
<where>
<if test="username!=null and username!=''">
and username like '%${username}%'
</if>
<if test="sex!=null and sex!=''">
and sex=#{sex};
</if>
</where>
</select>
<!--新增数据,传入的参数是个对象类型-->
<insert id="insertUser" parameterType="cn.gaolei.pojo.User">
insert into user values(null,#{username},#{birthday},#{sex},#{address});
</insert>
<select id="getUserCount" resultType="int">
select count(1) from user;
</select>
<select id="getUserByIds" parameterType="queryvo" resultType="user">
<include refid="user_sql"/>
user
<where>
<!--foreach循环标签的使用
collection:要遍历的集合
open:循环开始之前输出的内容
close:循环开始之后输出的内容
separator:设置分割符
item:循环的变量
-->
<!--目的:组成id in (1,10,24)-->
<foreach collection="ids" open="id in (" close=")" item="uID" separator=",">
#{uID}
</foreach>
</where>
</select>
<select id="getUserOrderMap" resultMap="user_order_map">
select u.id,u.username,u.birthday,u.address,u.sex ,
o.id oid,o.number,o.createtime,o.note
from user u left join `order` o on u.id = o.user_id;
</select>
</mapper>
关于多对多的话,其实和一对多一样的.
MyBatis的动态sql,也就是sql片段,有很多种.常用的动态SQL元素包括:
if
<select id ="selectEmployeeByIdLike" resultType = "cn.gaolei.pojo.Employee">
select * from employee where state = 'active'
<!--if就是一个可选条件,如果传进来的参数有id属性,那么就加上id查询条件,在
test里面写判断条件即可,判断条件可以用and或or来拼接-->
<if test = "id != null">
and id = #{id}
</if>
</select>
choose(when、otherwise)
<select id = "selectEmployeeChoose" parameterType = "hashmap"(这些类型全小写也完全没问题的,别名不区分大小写) resultType = "cn.gaolei.pojo.Employee" >
select * from employee where state = 'active'
<!--如果传入id,就根据id查询,没有传入id就根据loginname和password查询,否则查询sex等于男的数据-->
<choose>
<when test = "id != null">
and id = #{id}
</when>
<when test = "loginname != null and password != null">
and loginname = #{loginname} and password = #{password}
</when>
<otherwise>
and sex = '男'
</otherwise>
</choose>
</select>
where
<select id = "selectEmployeeByIdLike" resultType = "cn.gaolei.pojo.Employee">
select * from employee
<!--where 标签很智能,如果里面没有一个为真,那么就没有where,而且多余的and也能智能帮你去除.-->
<where>
<if test = "state != null">
state = #{state}
</if>
<if test = "id != null">
and id = #{id}
</if>
</where>
</select>
set
<!--set元素可以用于动态包含需要更新的列,而不包含其他的列-->
<update id = "updateEmployeeIfNecessary" parameterType = "cn.gaolei.pojo.Employee">
update employee
<set>
<if test = "loginname != null">loginname = #{loginname},</if>
<if test = "password != null">password = #{password},</if>
</set>
where id = #{id}
</update>
<!--set元素会智能帮你消除无关的逗号.-->
foreach(对集合进行遍历)
<!--foreach指定一个集合,相当于把集合里的每一个元素都加入到括号里了.item就是要遍历的变量.当使用可迭代对象或者数组时,
index 是当前迭代的次数,item 的值是本次迭代获取的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。-->
<select id = "selectEmployeeIn" resultType = "cn.gaolei.pojo.Employee">
select * from employee where id in
<foreach item = "item" index = "index" collection = "list" open = "(" seperator = "," close = ")">
#{item}
</foreach>
</select>
bind
<select id = "selectEmployeeLikeName" resultType = "cn.gaolei.pojo.Employee">
<!--你可以把bind理解为创造一个变量,后面就可以直接使用了-->
<bind name = "pattern" value = "'%' + _parameter.getName() + '%'"/>
select * from employee where loginname like #{pattern}
</select>
trim
mybatis的trim标签一般用于去除sql语句中多余的and关键字,逗号,或者给sql语句前拼接 “where“、“set“以及“values(“ 等前缀,或者添加“)“等后缀,可用于选择性插入、更新、删除或者条件查询等操作。
prefix 是给sql语句拼接的前缀,suffix 是给sql语句拼接的后缀。 prefixOverrides 去除sql语句前面的关键字或者字符,该关键字或者字符由prefixOverrides属性指定,假设该属性指定为"AND",当sql语句的开头为"AND",trim标签将会去除该"AND"
suffixOverrides 去除sql语句后面的关键字或者字符,该关键字或者字符由suffixOverrides属性指定
<trim prefix="WHERE" prefixOverrides="AND">
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</trim>
<!--上面的trim标签回给语句前面加上 where 并且如果语句是用and开头的话,还会自动去掉and。使用起来和 where标签达到的功能差不多,但是trim标签可以完成更多的功能-->
MyBatis的注解配置
让mybatis告别xml,走上注解的高速公路~~~
在mapper接口文件的方法上直接写上各种注解即可.
@Select @Insert @Update @Delete
注解后面括号里跟的语句和在xml文件里写的一样就行.resultmap则可以使用@Results({@Result}). 举个例子:
@Select("select * from employee where id = #{id}")
@Results({
@Result(id = true, column = "id", property = "id"),
@Result(column = "name", property = "name"),
@Result(column = "sex", property = "sex"),
@Result(column = "age", property = "age")//如果列和属性的名称相同,还可以省略@Result注解
})
Employee selectEmployeeById(Integer id);
关于一对一关联的代码如下
public interface PersonMapper {
@Select("select * from person where id = #{id}")
@Results({
@Result(id = true, column = "id", property = "id")
@Result(column = "name", property = "name"),
@Result(column = "sex", property = "sex"),
@Result(column = "age", property = "age")
@Result(column = "card_id", property = "card",
one = @One(
select = "cn.gaolei.mapper.CardMapper.selectCardById", fetchType = FetchType.EAGER))
})//one属性表示是个一对一的关联列.select表示需要关联执行的sql语句.
//fetchtype表示加载类型是立即加载EAGER还是延迟加载LAZY
Person selectPersonById(Integer id);
}
一对多关联的话,把一对一的one = @One() 改成 many = @Many()即可
注解的动态SQL
注解的动态sql有一些复杂,过程是这样的:
- 注解改为
@SelectProvicer @InsertProvider @UpdateProvider @DeleteProvider - 注解里的type写一个Provider类.class, method写对应的该类的方法.
- 新建Provider类(就是你第二步里用的那个),里面要有你第二步写的那个方法,同时该方法的参数和你注解的Mapper里面的方法的参数一样.
- 该方法要
return new SQL(){具体逻辑}.toString(); - 写好具体逻辑,SELECT 、FROM、WHERE、JOIN、INNER_JOIN、LEFT_OUTER_JOIN、RIGHT_OUTER_JOIN、OR、AND、GROUP_BY、HAVING、ORDER_BY、INSERT_INTO、VALUES(要插入的列,要插入的值)、DELETE_FROM、UPDATE、SET都成为了这个SQL匿名内部类的方法。用这些方法。实现这里的你需要的方法就行了。
举个例子:
public interface EmployeeMapper {
@SelectProvider(Type = EmployeeDynaSqlProvider.class, method = "selectWithParam")
List<Employee> selectWithParam(Map<String, Object> param);
}
public class EmployeeDynaSqlProvider {
public String selectWithParam(Map<String, Object> param) {
return new SQL(){
SELECT("*");
FROM("employee");
if (param.get("id") != null) {
WHERE("id = #{id}");
}
//...再有其他的if
}.toString;
}
}
Mybatis使用分页助手PageHelper也非常的简单,
第一步,在pom文件中引入依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>最新版本</version>
</dependency>
第二步,在要分页查询的方法前面加一个静态方法PageHelper.startPage(pageNum, pageSize);
第一个参数是第几页,第二个参数是每页的大小.那么查询结果就是自动分页的了.
但要注意,只有静态方法后面的第一个方法会被分页.要想再次分页,需要再次调用静态方法.
关于#{}和${}的区别如下:
#{ }:解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。
例如,Mapper.xml中如下的 sql 语句:
select * from user where name = #{name};
动态解析为:
select * from user where name = ?;
一个 #{ } 被解析为一个参数占位符 ? 。
而${ } 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换。
例如,Mapper.xml中如下的 sql:
select * from user where name = ${name};
当我们传递的参数为 "Jack" 时,上述 sql 的解析为:
select * from user where name = "Jack";
预编译之前的 SQL 语句已经不包含变量了,完全已经是常量数据了。 综上所得,${ }变量的替换阶段是在动态 SQL 解析阶段,而 #{ }变量的替换是在 DBMS 中。

