

三、redis之strings类型
strings是redis中使用最多的类型。
redis官网中是这么描述strings的:
Redis strings store sequences of bytes, including text, serialized objects, and binary arrays.
可以看到Redis strings保存的是sequences of bytes,也就是字节序列。不仅可以保存字符串,而且还可以保存二进制数据,比如图片,音频,视频等。可以看到Redis strings可以满足大多数场景。
现在来看下操作strings的命令:
因为存的是字符串和数字,同一个操作会产生不同的影响,所以对存的值分类。
存的值是字符串
get
get命令获取key对应的值。
set
SET key value [NX|XX] [GET] [EX seconds|PX milliseconds|EXAT unix-time-seconds|PXAT unix-time-milliseconds|KEEPTTL]
set命令将key和value绑定关系并设置到内存中。
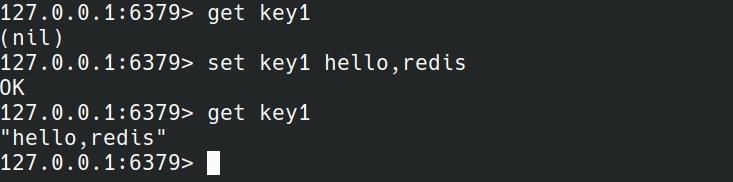
set命令还有NX,XX选项。NX表示当key对应的值不存在时执行的命令才会执行。XX表示key对应的值存在时执行的命令才会执行。
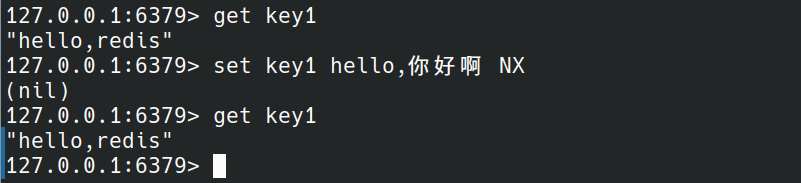
key1对应的值已存在,所以set加NX命令不会改变数据。

key2没有数据时,set加NX才会实际执行。
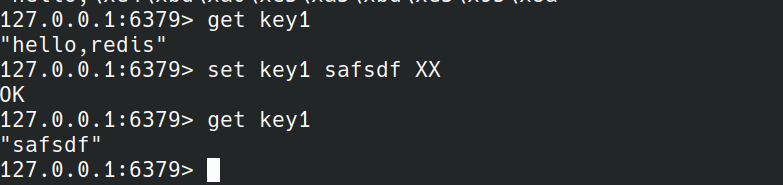
当key1有数据时,set加XX才会实际执行。
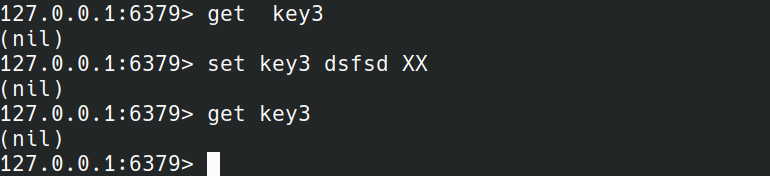
当key3没有数据时,set加XX不会实际执行。
set命令后面的EX seconds|PX milliseconds是加过期时间,EX是以秒为单位,PX是以毫秒为单位。
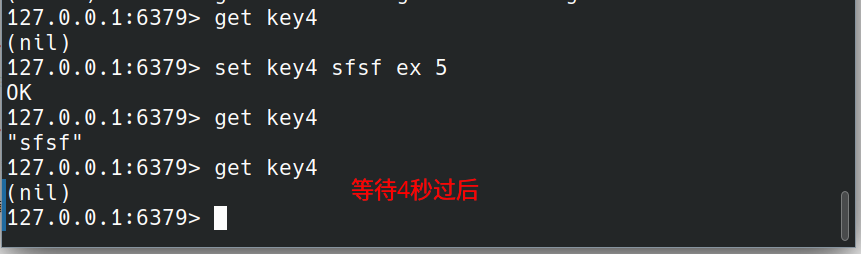
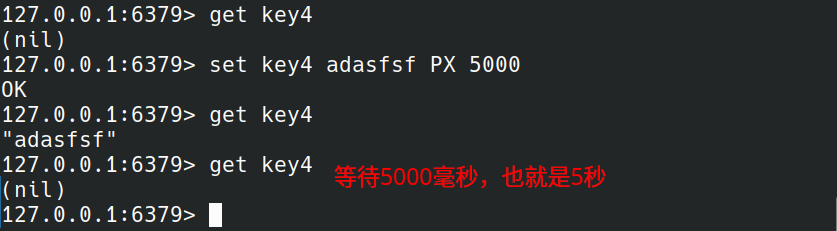
数据过期后就获取不到了。
setnx
SETNX key value
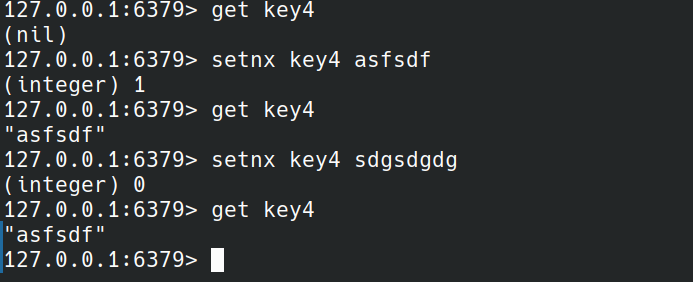
setnx命令和set命令加nx选项作用相同。
setex
SETEX key seconds value
setex命令和set命令加EX seconds选项相同。
PSETEX
PSETEX key milliseconds value
setex命令和set命令加PX milliseconds选项相同。
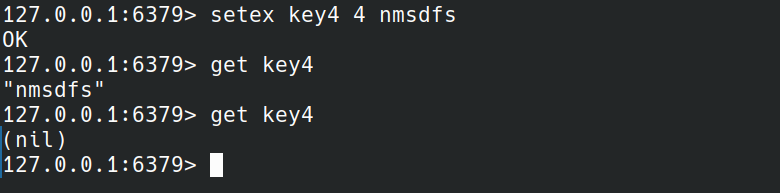
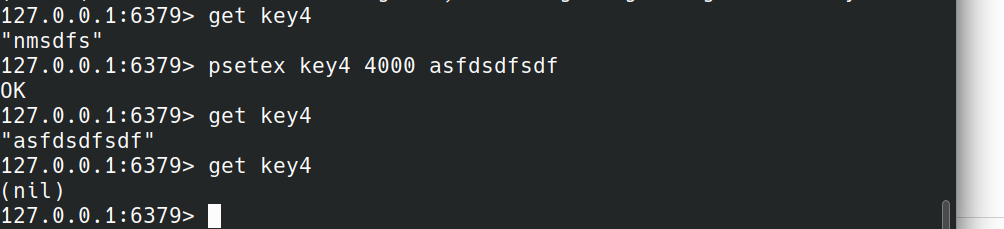
setex,PSETEX执行后等数据过期后都查询不到。
get命令只能一次获取一个key的数据,如果想要一次获取多个key的数据,可以使用mget命令。

有同时获取多个key的命令,应该也有同时设置多个key,value的命令,那就是mset。
MSET key value [key value ...]
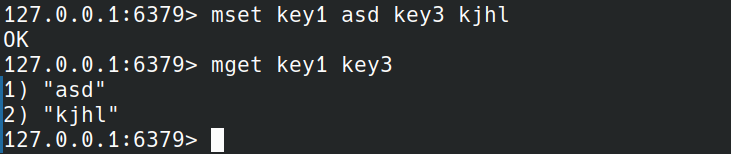
可以看到mset命令要比set命令简单,没有set命令的选项。
msetnx
MSETNX key value [key value ...]
当所有的key都不存在时才会执行命令。
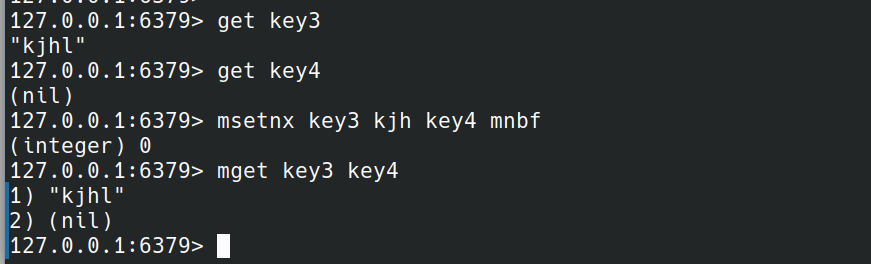
当其中一个key存在数据时不会执行命令。
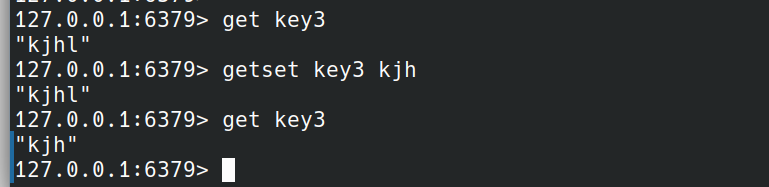
GETSET
GETSET key value
GETSET返回执行此命令key之前的值,并且设置新值value。
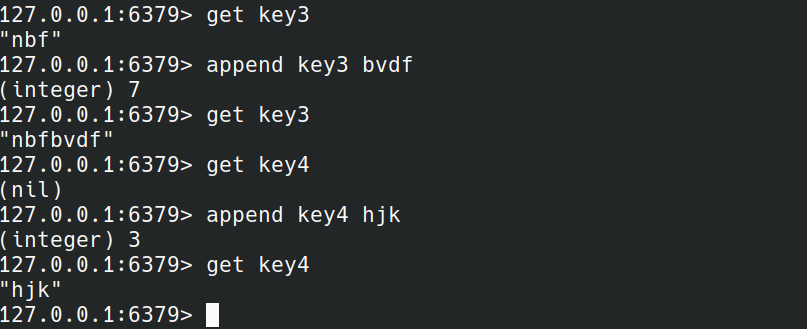
APPEND
APPEND key value
APPEND将value附加到原先的值之后。如果原先没有值就创建它。
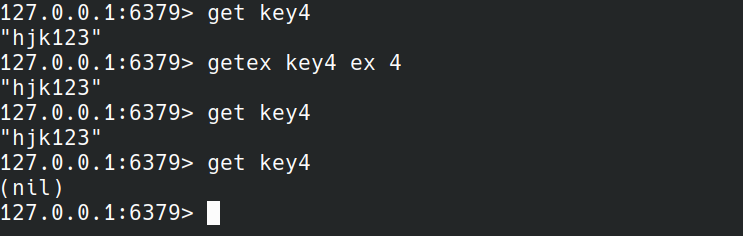
GETEX
GETEX key [EX seconds|PX milliseconds|EXAT unix-time-seconds|PXAT unix-time-milliseconds|PERSIST]
GETEX获取值并设置过期时间。EX seconds|PX milliseconds与set命令的含义相同。
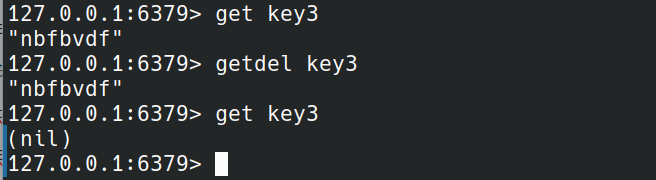
GETDEL
GETDEL key
返回value并删除key。
GETRANGE
GETRANGE key start end
返回start和end之间的子串。
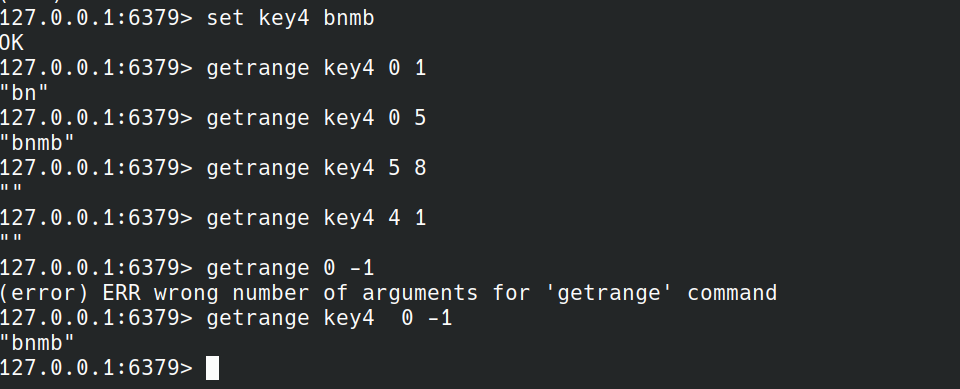
如果start大于end则返回空串.start和end可以使用负数.-1表示最后一个位置.

只要start和end的范围可以在key之间取到值就可以.从上面可以看到-10已经超过key4的长度了,但还是可以正常返回.
SUBSTR
SUBSTR key start end
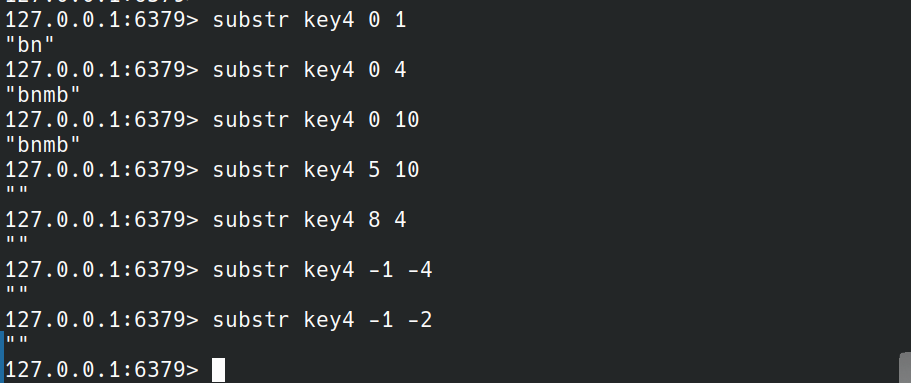
SUBSTR和GETRANGE命令相同,但是SUBSTR只能使用0和正整数,不能使用负数.
SETRANGE
SETRANGE key offset value
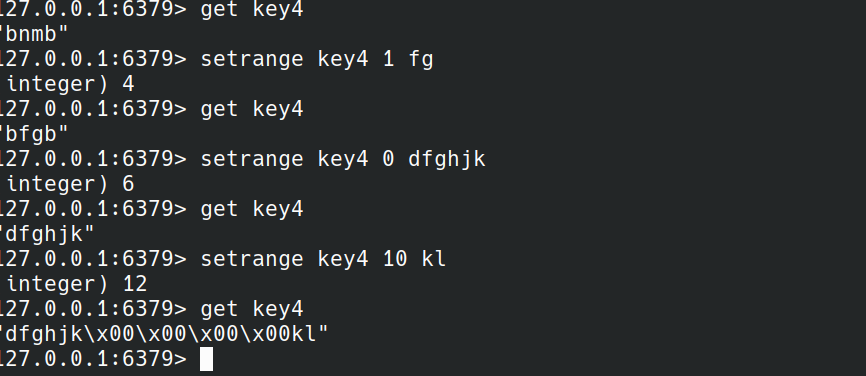
SETRANGE从offset开始将数据覆盖为value.如果offset超过key的长度,那么超出的部分设置为空字符串.
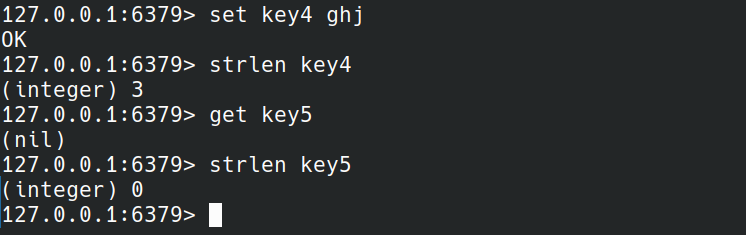
STRLEN
STRLEN返回key对应值的长度.
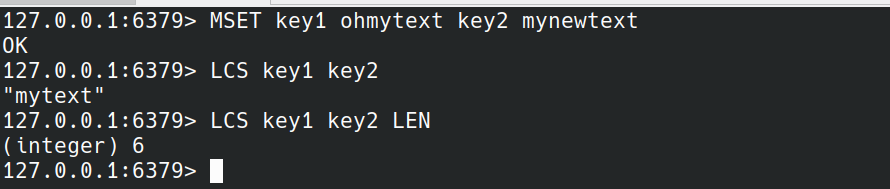
LCS
LCS key1 key2 [LEN] [IDX] [MINMATCHLEN min-match-len] [WITHMATCHLEN]
返回key1,key对应的值的最长公共子序列.比如"foo"和"fao"的最长公共子序列是"fo",不要求连续.LCS对于评估两个字符串的相似程度非常有用。字符串可以代表很多东西。例如,如果两个字符串是DNA序列,LCS将提供两个DNA序列之间相似性的度量。如果字符串表示某个用户编辑的某些文本,则LCS可以表示新文本与旧文本的差异,以此类推。
返回匹配的文本:

只返回匹配的长度:
有时还需要返回匹配的位置:
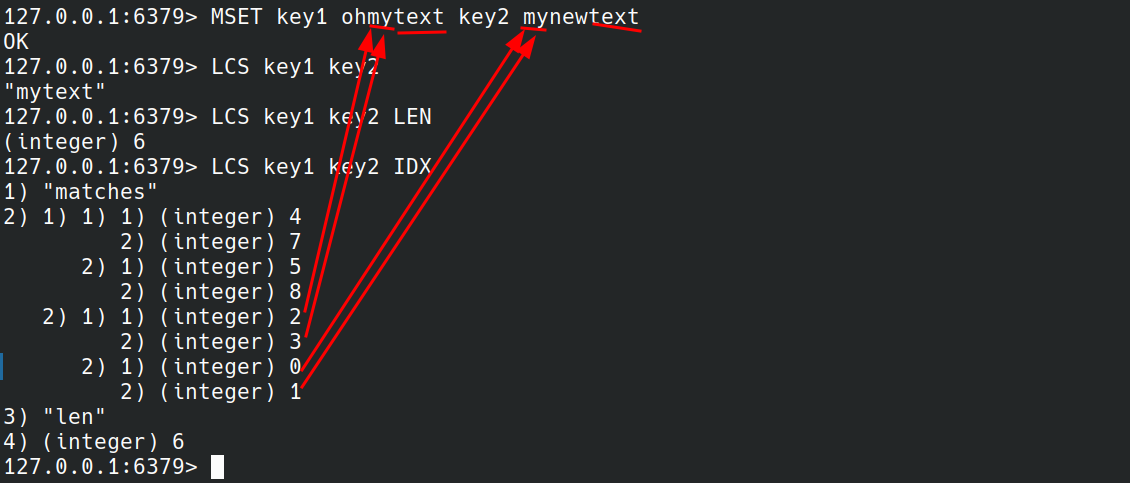
因为匹配算法是从后往前匹配的,所以要反着看.
2) 1) 1) (integer) 2
2) (integer) 3
2) 1) (integer) 0
2) (integer) 1
2,3表示key1中第一个连续匹配的字符串的开始下标和结束下标(从0开始).0,1表示key2中第一个连续匹配的字符串的开始下标和结束下标(从0开始)
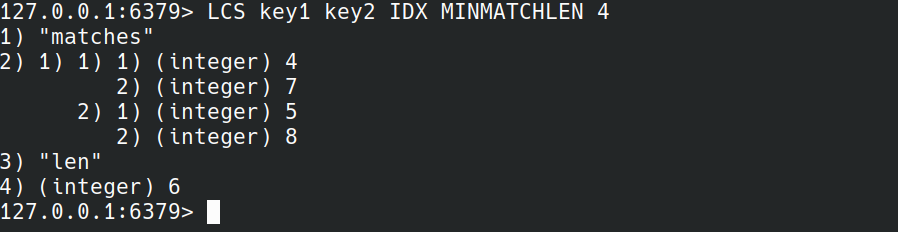
要将匹配列表限制为给定最小长度的匹配:
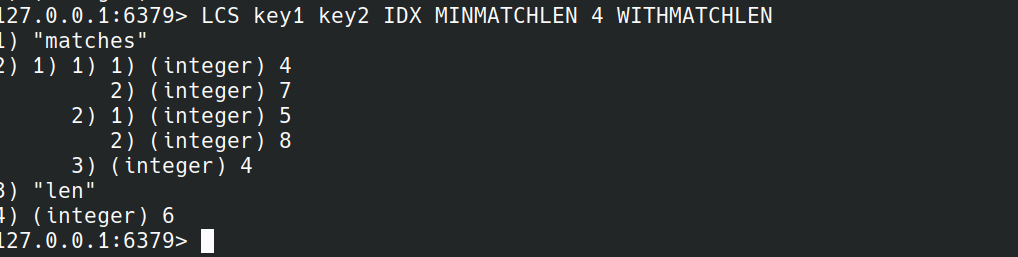
最后还带有匹配长度:
英文采用的是ASCII编码,用一个字节可以表示所有的符号,但是对于中文则不同,要用多字节表示.比如:

所以对于中文,操作每个字符时与操作每个字节是不同的,需要注意.
存的值是数字
因为数字是可以运算的.所以要对数字特殊处理.redis提供的数字操作很简单.
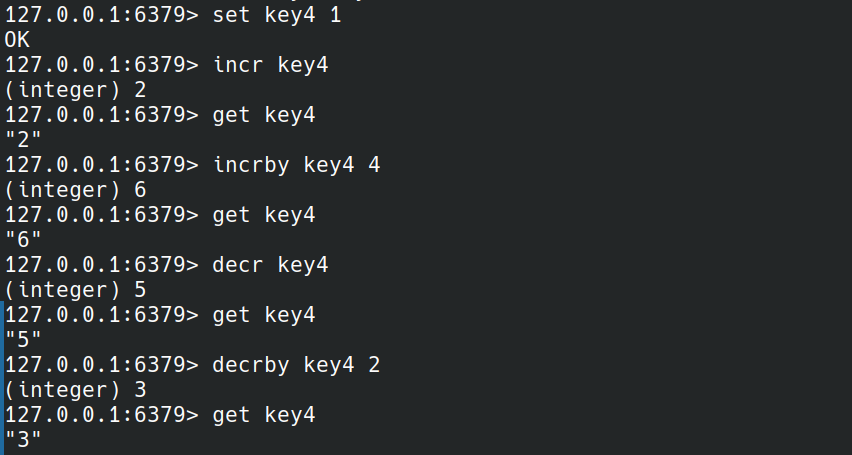
INCR key
INCRBY key increment
INCRBYFLOAT key increment
DECR key
DECRBY key decrement
INCR,INCRBY,INCRBYFLOAT是加法运算,DECR,DECRBY是减法运算.INCR,DECR是加一或减一,INCRBY,DECRBY加或减后面给定的整数,INCRBYFLOAT加一个给定的小数.
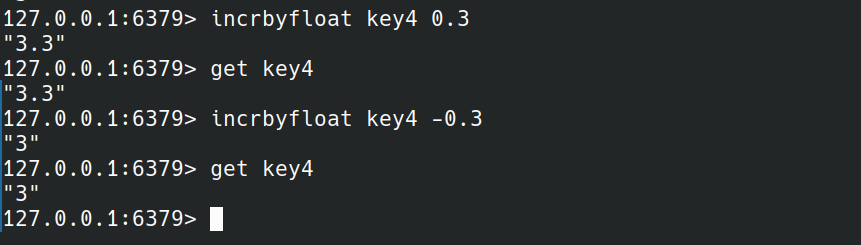

当INCRBY,DECRBY的参数不是整数时会报错.
当然虽然是整数,但是也可以使用操作字符串的命令
存的值是二进制数据
在控制台运行:
cat 1.jpg | redis-cli -x set key6
将1.jpg的内容存到key6中.
也可以使用操作字符串的命令,最好还是采用专业的工具操作.
编码方式
最后来看下字符串在redis中采用的编码方式:
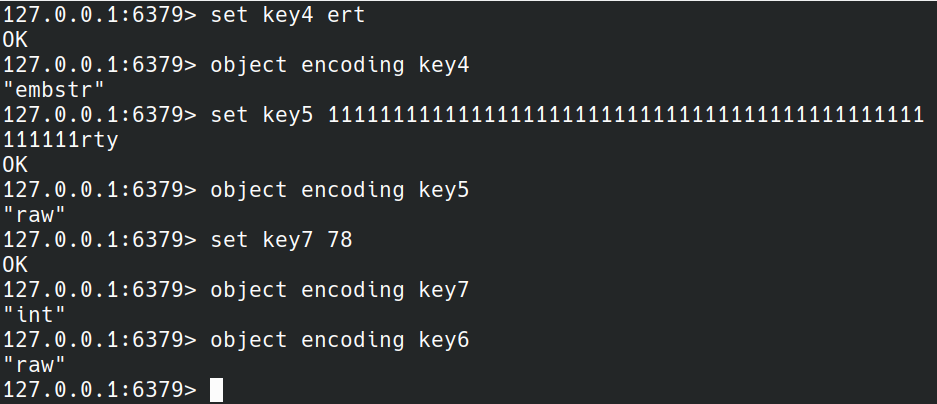
如果是数字则采用int编码,如果字符串的长度小于等于44则采用embstr,否则采用raw.那为什么要采用不同的编码呢? 主要是为了节省使用的空间.比如数字23,采用int编码会保存为C语言的long类型,一般是4字节或8字节,采用embstr则是3字节,C语言的字符串还需结尾字符\0.看起来没有节省空间,但是当数字特别大时,比如123456789,就看出差距了.

