

PostgreSQL-运算符和函数2
一、Bit String 函数和操作



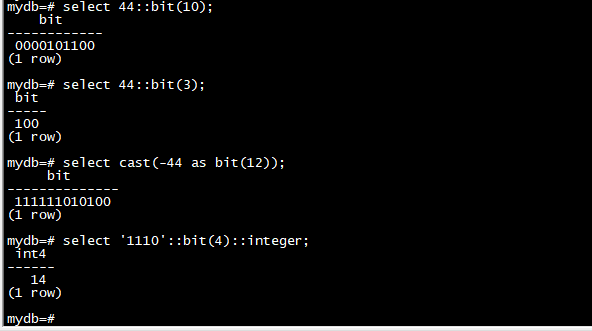
此外,可以将整数值转换为位类型或从位类型转换为整数值。将整数转换为 bit(n) 会复制最右边的 n 位。将整数转换为比整数本身更宽的位串宽度将在左侧进行符号扩展。一些例子:
select 44::bit(10);
select 44::bit(3);
select cast(-44 as bit(12));
select '1110'::bit(4)::integer;
二、模式匹配
PostgreSQL 提供了三种不同的模式匹配方法:传统的 SQL LIKE 运算符、最近的 SIMILAR TO 运算符(在 SQL:1999 中添加)和 POSIX 样式的正则表达式。除了基本的“这个字符串是否匹配这个模式?”运算符、函数可用于提取或替换匹配的子字符串以及在匹配位置拆分字符串。
所有三种模式匹配运算符都不支持非确定性排序规则。如果需要,请对表达式应用不同的排序规则以解决此限制。
Like:
string LIKE pattern [ESCAPE escape-character]
string NOT LIKE pattern [ESCAPE escape-character]
如果模式不包含百分号或下划线,则模式仅代表字符串本身;在这种情况下,LIKE 的作用类似于等于运算符。模式中的下划线 (_) 代表(匹配)任何单个字符;百分号 (%) 匹配任何零个或多个字符的序列。
'abc' LIKE 'abc' true
'abc' LIKE 'a%' true
'abc' LIKE '_b_' true
'abc' LIKE 'c' false
根据活动区域设置,可以使用关键字 ILIKE 代替 LIKE 以使匹配不区分大小写。这不在 SQL 标准中,而是 PostgreSQL 扩展。
操作符等价于LIKE,对应于ILIKE。还有 !~~ 和 !~~ 运算符分别代表 NOT LIKE 和 NOT ILIKE。所有这些运算符都是 PostgreSQL 特定的。您可能会在 EXPLAIN 输出和类似位置看到这些运算符名称。
SIMILAR TO正则表达式
string SIMILAR TO pattern [ESCAPE escape-character]
string NOT SIMILAR TO pattern [ESCAPE escape-character]
与 LIKE 一样,SIMILAR TO 运算符只有在其模式与整个字符串匹配时才会成功;这与模式可以匹配字符串的任何部分的常见正则表达式行为不同。与 LIKE 一样,SIMILAR TO 使用 _ 和 % 作为通配符,分别表示任何单个字符和任何字符串(它们与 POSIX 正则表达式中的 . 和 .* 相当)。
除了从 LIKE 借来的这些工具之外,SIMILAR TO 还支持从 POSIX 正则表达式借来的这些模式匹配元字符:
|表示交替(两种选择中的任何一种)。
- 表示前一项重复零次或多次。
- 表示前一项重复一次或多次。
?表示前一项重复零次或一次。
{m} 表示前一项正好重复 m 次。
{m,} 表示前一项重复 m 次或更多次。
{m,n} 表示前一项至少重复 m 次且不超过 n 次。
括号 () 可用于将项目分组为单个逻辑项目。
括号表达式 [...] 指定一个字符类,就像在 POSIX 正则表达式中一样。
请注意,句点 (.) 不是 SIMILAR TO 的元字符。
与 LIKE 一样,反斜杠禁用任何这些元字符的特殊含义。可以使用 ESCAPE 指定不同的转义字符,或者可以通过编写 ESCAPE '' 来禁用转义功能。
例子:
'abc' SIMILAR TO 'abc' true
'abc' SIMILAR TO 'a' false
'abc' SIMILAR TO '%(b|d)%' true
'abc' SIMILAR TO '(b|c)%' false
'-abc-' SIMILAR TO '%\mabc\M%' true
'xabcy' SIMILAR TO '%\mabc\M%' false
POSIX 正则表达式
正则表达式是一个字符序列,它是一组字符串(正则集)的缩写定义。如果字符串是正则表达式描述的正则集的成员,则称该字符串与正则表达式匹配。
'abcd' ~ 'bc' true
'abcd' ~ 'a.c' true — 点匹配任意字符
'abcd' ~ 'a.*d' true — * 重复前面的模式项
'abcd' ~ '(b|x)' true — |表示 OR,括号组
'abcd' ~ '^a' true — ^ 锚定到字符串的开头
'abcd' ~ '^(b|c)' false — 匹配b或c开头的字符串
具有两个参数 substring(string from pattern) 的 substring 函数提供与 POSIX 正则表达式模式匹配的子字符串的提取。如果没有匹配,则返回 null,否则返回与模式匹配的文本的第一部分。但是,如果模式包含任何括号,则返回与第一个带括号的子表达式(左括号在前的那个)匹配的文本部分。如果要在其中使用括号而不触发此异常,则可以在整个表达式周围放置括号。如果在要提取的子表达式之前的模式中需要括号,请参阅下面描述的非捕获括号。
例子:
substring('foobar' from 'o.b') oob
substring('foobar' from 'o(.)b') o
regexp_replace 函数为匹配 POSIX 正则表达式模式的子字符串提供新文本的替换。它的语法为 regexp_replace(source, pattern, replacement [, flags ])。如果与模式不匹配,则源字符串将原样返回。如果匹配,则返回源字符串,并用替换字符串替换匹配的子字符串。替换字符串可以包含 \n,其中 n 是 1 到 9,表示应该插入匹配模式的第 n 个括号子表达式的源子字符串,它可以包含 & 表示匹配整个模式的子字符串应该插入。如果您需要在替换文本中添加文字反斜杠,请编写 \。flags 参数是一个可选的文本字符串,包含零个或多个更改函数行为的单字母标志。标志 i 指定不区分大小写的匹配,而标志 g 指定替换每个匹配的子字符串,而不仅仅是第一个。
例子:
regexp_replace('foobarbaz', 'b..', 'X')
fooXbaz
regexp_replace('foobarbaz', 'b..', 'X', 'g')
fooXX
regexp_replace('foobarbaz', 'b(..)', 'X\1Y', 'g')
fooXarYXazY
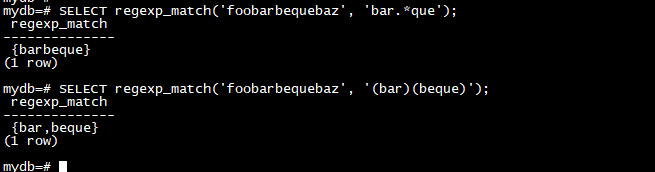
regexp_match 函数返回一个由 POSIX 正则表达式模式与字符串的第一次匹配产生的捕获子字符串的文本数组。它的语法为 regexp_match(string, pattern [, flags ])。如果没有匹配,则结果为 NULL。如果找到匹配项,并且模式不包含带括号的子表达式,则结果是一个单元素文本数组,其中包含与整个模式匹配的子字符串。如果找到匹配项,并且模式包含带括号的子表达式,则结果是一个文本数组,其第 n 个元素是匹配模式的第 n 个带括号的子表达式的子字符串。flags 参数是一个可选的文本字符串,包含零个或多个更改函数行为的单字母标志。
例子:
SELECT regexp_match('foobarbequebaz', 'bar.*que');
SELECT regexp_match('foobarbequebaz', '(bar)(beque)');
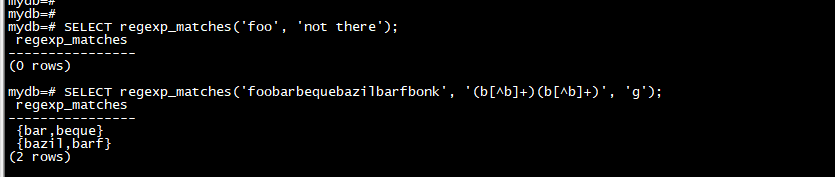
regexp_matches 函数返回一组捕获的子字符串的文本数组,这些子字符串是由将 POSIX 正则表达式模式与字符串匹配的结果。它具有与 regexp_match 相同的语法。如果没有匹配,此函数不返回任何行,如果有匹配且未给出 g 标志则返回一行,或者如果有 N 个匹配且已给出 g 标志,则返回 N 行。每个返回的行都是一个文本数组,其中包含整个匹配的子字符串或匹配模式的带括号的子表达式的子字符串,就像上面对 regexp_match 的描述一样。
例子:
SELECT regexp_matches('foo', 'not there');
SELECT regexp_matches('foobarbequebazilbarfbonk', '(b[^b]+)(b[^b]+)', 'g');
SELECT regexp_matches('foobarbequebazilbonk', '(b[^b]+)(b[^b]+)', 'g');

regexp_split_to_table 函数使用 POSIX 正则表达式模式作为分隔符拆分字符串。它的语法为 regexp_split_to_table(string, pattern [, flags ])。如果模式不匹配,则函数返回字符串。如果至少有一个匹配,则对于每个匹配,它都会返回从最后一个匹配的结尾(或字符串的开头)到匹配开头的文本。当没有更多匹配时,它将从最后一个匹配的末尾返回到字符串末尾的文本。flags 参数是一个可选的文本字符串,包含零个或多个更改函数行为的单字母标志。
regexp_split_to_array 函数的行为与 regexp_split_to_table 相同,只是 regexp_split_to_array 将其结果作为文本数组返回。它的语法为 regexp_split_to_array(string, pattern [, flags ])。参数与 regexp_split_to_table 相同。
例子:
SELECT foo FROM regexp_split_to_table('the quick brown fox jumps over the lazy dog', '\s+') AS foo;
SELECT regexp_split_to_array('the quick brown fox jumps over the lazy dog', '\s+');
SELECT foo FROM regexp_split_to_table('the quick brown fox', '\s*') AS foo;

POSIX 1003.2 中定义的正则表达式 (REs) 有两种形式:扩展 REs 或 EREs(大致是 egrep 的那些),以及基本 REs 或 BREs(大致是 ed 的那些)。PostgreSQL 支持这两种形式,并且还实现了一些不在 POSIX 标准中的扩展,但由于它们在 Perl 和 Tcl 等编程语言中的可用性而被广泛使用。使用这些非 POSIX 扩展的 RE 称为高级 RE 或 ARE。ARE 几乎是 ERE 的精确超集,但 BRE 有几个符号上的不兼容性(并且受到更多限制)。
正则表达式定义为一个或多个分支,用 | 分隔。它匹配任何与其中一个分支匹配的东西。
分支是连接在一起的零个或多个量化原子或约束。它匹配第一个匹配,然后匹配第二个匹配,依此类推;空分支匹配空字符串。
Regular Expression Atoms:
(re) (其中 re 是任何正则表达式)匹配 re 的匹配项,并注明匹配项以用于可能的报告
(?:re) 如上所述,但不记录匹配报告(一组“非捕获”括号)(仅限 ARE)
. 匹配任何单个字符
[chars] 一个括号表达式,匹配任何一个字符
\k (其中 k 是非字母数字字符)匹配作为普通字符的字符,例如,\ 匹配反斜杠字符
\c 其中 c 是字母数字(可能后跟其他字符)是转义符
{ 当后跟一个数字以外的字符时,匹配左大括号字符 {;当后面跟着一个数字时,它是一个边界的开始
x 其中 x 是没有其他意义的单个字符,匹配该字符
正则表达式量词:

使用 {...} 的形式称为边界。范围内的数字 m 和 n 是无符号十进制整数,其允许值从 0 到 255(含)。
非贪心量词(Non-greedy)(仅在 ARE 中可用)匹配与其对应的正常(贪心)对应物相同的可能性,但更喜欢最小数量而不是最大数量的匹配。
一个量词不能紧跟另一个量词,例如,** 是无效的。量词不能以表达式或子表达式开头,也不能跟在 ^ 或 | 之后。
正则表达式约束:
^ 匹配字符串的开头
$ 在字符串末尾匹配
(?=re) 在子字符串匹配 re 开始的任何点进行正向前瞻匹配(仅限 ARE)
(?!re) 在没有子字符串匹配 re 开始的任何点处匹配负前瞻(仅限 ARE)
(?<=re) 正向后向匹配在子字符串匹配重新结束的任何点(仅限 ARE)
(?<!re) 否定后向匹配在没有子字符串匹配重新结束的任何点(仅限 ARE)
括号表达式
括号表达式是包含在 [] 中的字符列表。它通常匹配列表中的任何单个字符。如果列表以 ^ 开头,则它匹配列表其余部分以外的任何单个字符。如果列表中的两个字符由 - 分隔,这是整理序列中这两个(包括)之间的全部字符范围的简写,例如,ASCII 中的 [0-9] 匹配任何十进制数字。两个范围共享一个端点是非法的,例如 a-c-e。范围非常依赖于排序序列,因此可移植程序应避免依赖它们。
要在列表中包含文字 ],请将其设为第一个字符(在 ^ 之后,如果使用的话)。要包含文字 -,请将其设为第一个或最后一个字符,或范围的第二个端点。要使用文字 - 作为范围的第一个端点,请将其括在 [.和 .] 使其成为整理元素。除了这些字符、一些使用 [和转义符(仅限 ARE)的组合之外,所有其他特殊字符在括号表达式中都失去了它们的特殊意义。特别是,\ 在遵循 ERE 或 BRE 规则时并不特殊,尽管它在 ARE 中是特殊的(如引入转义)。
在括号表达式中,包含在 [.和 .] 代表该整理元素的字符序列。该序列被视为括号表达式列表的单个元素。这允许包含多字符排序元素的括号表达式匹配多个字符,例如,如果排序序列包含 ch 排序元素,则 RE [[.ch.]]*c 匹配 chchcc 的前五个字符.
在括号表达式中,包含在 [= 和 =] 中的整理元素是一个等价类,代表与该元素等效的所有整理元素的字符序列,包括它自己。(如果没有其他等价的整理元素,处理方式就像封闭的分隔符是 [. 和 .]。)例如,如果 o 和 ^ 是等价类的成员,则 [[=o=]],[[=^=]] 和 [o^] 都是同义词。等价类不能是范围的端点。
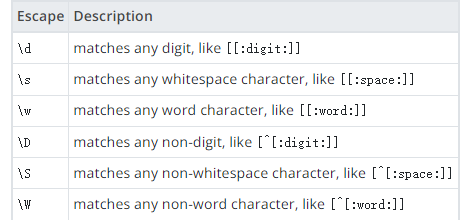
在括号表达式中,包含在 [: 和 :] 中的字符类的名称代表属于该类的所有字符的列表。字符类不能用作范围的端点。POSIX 标准定义了这些字符类名称:alnum(字母和数字)、alpha(字母)、blank(空格和制表符)、cntrl(控制字符)、digit(数字)、graph(除空格外的可打印字符)、lower(小写字母)、print(可打印字符,包括空格)、punct(标点符号)、空格(任何空格)、upper(大写字母)和 xdigit(十六进制数字)。对于 7 位 ASCII 集中的字符,这些标准字符类的行为在不同平台上通常是一致的。给定的非 ASCII 字符是否被认为属于这些类之一取决于用于正则表达式函数或运算符的排序规则,或者默认情况下取决于数据库的 LC_CTYPE 语言环境设置。即使在名称相似的语言环境中,非 ASCII 字符的分类也会因平台而异。(但 C 语言环境从不认为任何非 ASCII 字符属于这些类中的任何一个。)除了这些标准字符类之外,PostgreSQL 还定义了 word 字符类,它与 alnum 加下划线 (_) 字符相同,和 ascii 字符类,它正好包含 7 位 ASCII 集。
括号表达式有两种特殊情况:括号表达式 [[:<:]] 和 [[:>:]] 是约束,分别匹配单词开头和结尾的空字符串。一个单词被定义为一个单词字符序列,它既不在单词字符的前面也不在其后面。单词字符是属于单词字符类的任何字符,即任何字母、数字或下划线。这是一个扩展,与 POSIX 1003.2 兼容但未指定,在旨在移植到其他系统的软件中应谨慎使用。
正则表达式转义
转义符是以 \ 开头的特殊序列,后跟一个字母数字字符。转义有多种形式:字符输入、类速记、约束转义和反向引用。在 ARE 中,后跟字母数字字符但不构成有效转义的 \ 是非法的。在 ERE 中,没有转义:在括号表达式之外,后跟字母数字字符的 \ 仅表示该字符是普通字符,而在括号表达式内,\ 是普通字符。(后者是 ERE 和 ARE 之间的一个实际不兼容。)
反向引用 (\n) 匹配由数字 n 指定的前一个带括号的子表达式匹配的相同字符串。例如,([bc])\1 匹配 bb 或 cc,但不匹配 bc 或 cb。子表达式必须完全位于 RE 中的反向引用之前。子表达式按其前括号的顺序编号。非捕获括号不定义子表达式。反向引用只考虑被引用的子表达式匹配的字符串字符,而不考虑其中包含的任何约束。例如,(^\d)\1 将匹配 22。

正则表达式元语法
一个 RE 可以以两个特殊的 director 前缀之一开始。如果 RE 以 ***: 开头,则 RE 的其余部分被视为 ARE。(这在 PostgreSQL 中通常没有效果,因为 RE 被假定为 ARE;但如果 ERE 或 BRE 模式已由正则表达式函数的 flags 参数指定。)如果 RE 以 ***= 开头, RE 的其余部分被视为文字字符串,所有字符都被视为普通字符。

嵌入选项在 ) 终止序列时生效。它们只能出现在 ARE 的开头(在 ***:director 之后,如果有的话)。
正则表达式匹配规则
如果 RE 可以匹配给定字符串的多个子字符串,则 RE 匹配字符串中最早开始的那个。如果 RE 可以从该点开始匹配多个子字符串,则将采用最长可能匹配或最短可能匹配,具体取决于 RE 是贪婪的还是非贪婪的。
RE 是否贪婪由以下规则确定:
- 大多数原子和所有约束都没有贪婪属性(因为它们无论如何都无法匹配可变数量的文本)。
- 在 RE 周围添加括号不会改变它的贪婪性。
- 具有固定重复量词({m} 或 {m}?)的量化原子与原子本身具有相同的贪心(可能没有)。
- 具有其他正常量词的量化原子(包括 m 等于 n 的 {m,n})是贪婪的(更喜欢最长匹配)。
- 具有非贪婪量词(包括 {m,n}? 且 m 等于 n)的量化原子是非贪婪的(更喜欢最短匹配)。
- 一个分支——也就是一个没有顶级 | 的 RE运算符 — 与其中第一个具有贪心属性的量化原子具有相同的贪心。
- 由 | 连接的两个或多个分支组成的 RE操作总是贪婪的。
上述规则不仅将贪婪属性与单个量化原子相关联,还与包含量化原子的分支和整个 RE 相关联。这意味着匹配是以这样一种方式完成的,即分支或整个 RE 匹配整个最长或最短的可能子字符串。一旦确定了整个匹配的长度,匹配任何特定子表达式的部分将根据该子表达式的贪婪属性来确定,RE 中较早开始的子表达式优先于较晚开始的子表达式。
例子:
SELECT SUBSTRING('XY1234Z', 'Y*([0-9]{1,3})');
SELECT SUBSTRING('XY1234Z', 'Y*?([0-9]{1,3})');
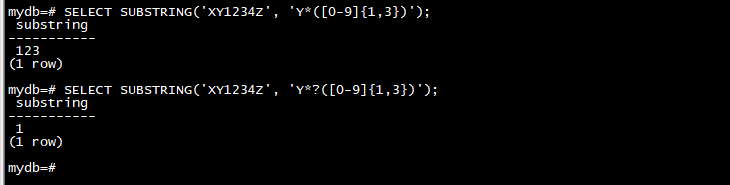
在第一种情况下,RE 作为一个整体是贪婪的,因为 Y* 是贪婪的。它可以从 Y 开始匹配,并且匹配从那里开始的最长可能字符串,即 Y123。输出是括号内的部分,即 123。在第二种情况下,RE 作为一个整体是非贪婪的,因为 Y*?是非贪婪的。它可以从 Y 开始匹配,并且匹配从那里开始的最短可能字符串,即 Y1。子表达式 [0-9]{1,3} 是贪心的,但它不能改变关于整体匹配长度的决定;所以它被迫只匹配1。
简而言之,当一个 RE 包含贪婪和非贪婪子表达式时,根据分配给整个 RE 的属性,总匹配长度要么尽可能长,要么尽可能短。分配给子表达式的属性仅影响它们被允许相对于彼此“吃”多少匹配。
量词 {1,1} 和 {1,1}?可用于分别在子表达式或整个 RE 上强制贪婪或非贪婪。当您需要整个 RE 具有不同于从其元素推导出的贪婪属性时,这很有用。例如,假设我们试图将包含一些数字的字符串分成数字以及它们之前和之后的部分。我们可能会尝试这样做:
SELECT regexp_match('abc01234xyz', '(.*)(\d+)(.*)');

那没有用:第一个 .* 是贪婪的,所以它尽可能多地“吃”,让 \d+ 匹配最后一个可能的位置,最后一个数字。我们可能会尝试通过使其不贪婪来解决这个问题:
SELECT regexp_match('abc01234xyz', '(.*?)(\d+)(.*)');

这也不起作用,因为现在整个 RE 是非贪婪的,因此它会尽快结束结果。我们可以通过强制整个 RE 变得贪婪来得到我们想要的:
SELECT regexp_match('abc01234xyz', '(?:(.*?)(\d+)(.*)){1,1}');

将 RE 的整体贪心与其组件的贪心分开控制,可以在处理可变长度模式时提供极大的灵活性。
在决定什么是更长或更短的匹配时,匹配长度以字符而不是排序元素来衡量。空字符串被认为比不匹配更长。例如:bb* 匹配 abbbc 的中间三个字符;(week|wee)(night|knights) 匹配 weeknights 的所有十个字符;当 (.). 与 abc 匹配时,括号内的子表达式匹配所有三个字符;当 (a) 与 bc 匹配时,整个 RE 和带括号的子表达式都匹配一个空字符串。
如果指定了与大小写无关的匹配,则效果就像所有大小写区别都从字母表中消失一样。当存在多种情况的字母作为普通字符出现在方括号表达式之外时,它会有效地转换为包含两种情况的方括号表达式,例如,x 变为 [xX]。当它出现在括号表达式中时,它的所有大小写对应项都将添加到括号表达式中,例如,[x] 变为 [xX] 并且 [^x] 变为 [^xX]。
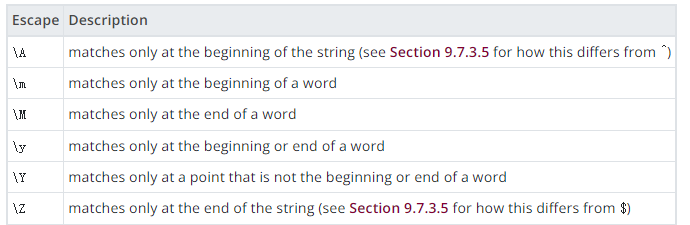
如果指定了换行敏感匹配,.和使用 ^ 的括号表达式将永远不会匹配换行符(因此匹配不会跨行,除非 RE 明确包含换行符)并且 ^ 和 $ 将分别匹配换行符之后和之前的空字符串,除了在开头匹配和分别结束字符串。但是 ARE 转义 \A 和 \Z 仅继续匹配字符串的开头或结尾。此外,无论这种模式如何,字符类简写 \D 和 \W 都将匹配换行符。(在 PostgreSQL 14 之前,它们在换行敏感模式下不匹配换行符。写入 [[1]] 或 [[2]] 以获得旧行为。)
限制和兼容性
在本实施方式中,对RE的长度没有特别的限制。但是,旨在高度可移植的程序不应使用超过 256 字节的 RE,因为符合 POSIX 的实现可以拒绝接受此类 RE。
ARE 与 POSIX ERE 不兼容的唯一特性是 \ 在括号表达式中不会失去其特殊意义。所有其他 ARE 功能使用在 POSIX ERE 中非法或具有未定义或未指定效果的语法;Director 的 *** 语法同样在 BRE 和 ERE 的 POSIX 语法之外。
许多 ARE 扩展是从 Perl 借来的,但有些已被更改以清理它们,还有一些 Perl 扩展不存在。注意的不兼容性包括 \b、\B、缺少对尾随换行符的特殊处理、在受换行敏感匹配影响的事物中添加补充括号表达式、在前瞻/后视约束中对括号和后向引用的限制,以及最长/最短匹配(而不是第一次匹配)匹配语义。

