

PostgreSQL-数据类型4
一、range类型
范围类型是表示某个元素类型(称为范围的子类型)的一系列值的数据类型。例如,时间戳的范围可用于表示会议室预定的时间范围。在这种情况下,数据类型是 tsrange(“timestamp range”的缩写),timestamp 是子类型。子类型必须具有总顺序,以便明确定义元素值是在值范围内、之前还是之后。
范围类型很有用,因为它们表示单个范围值中的许多元素值,并且可以清楚地表达重叠范围等概念。将时间和日期范围用于调度目的是最明显的例子;但价格范围、仪器的测量范围等也很有用。
每个范围类型都有一个对应的多范围类型。多范围是非连续、非空、非空范围的有序列表。大多数范围运算符也适用于多范围,并且它们有自己的一些功能。
PostgreSQL 带有以下内置范围类型:
-
int4range — 整数范围,int4multirange — 对应的 Multirange
-
int8range — bigint 的范围,int8multirange — 对应的 Multirange
-
numrange - 数值范围,nummultirange - 对应的 Multirange
-
tsrange — 没有时区的时间戳范围,tsmultirange — 对应的 Multirange
-
tstzrange — 带有时区的时间戳范围,tstzmultirange — 对应的 Multirange
-
daterange - 日期范围,datemultirange - 对应的 Multirange
举个栗子:
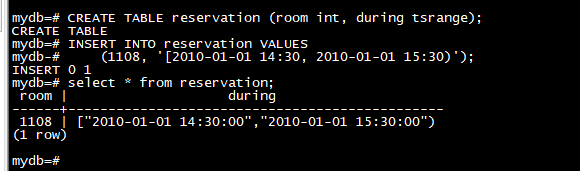
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
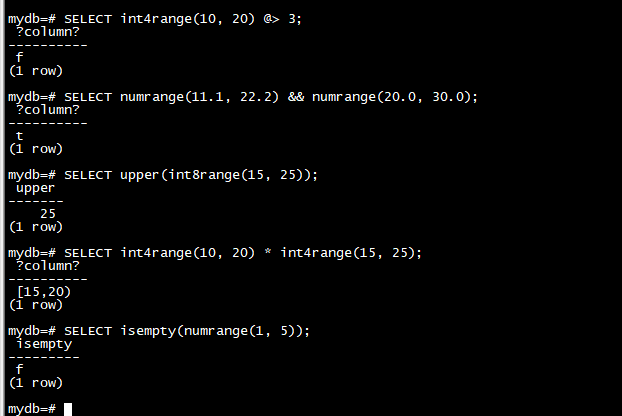
SELECT int4range(10, 20) @> 3; --包含
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0); --是否相交
SELECT upper(int8range(15, 25)); --提取上限
SELECT int4range(10, 20) * int4range(15, 25); --计算交点
SELECT isempty(numrange(1, 5)); --非空判断
每个非空范围都有两个界限,下限和上限。这些值之间的所有点都包含在该范围内。包含边界意味着边界点本身也包含在范围内,而排他边界意味着边界点不包括在范围内。
在范围的文本形式中,包含的下界用“[”表示,而独占的下限用“(”表示。同样,包含的上界用“]”表示,而独占的上界表示经过 ”)”。
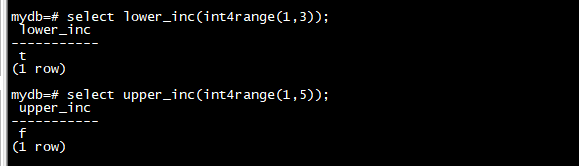
函数 lower_inc 和 upper_inc 分别测试范围值的下限和上限的包容性。
select lower_inc(int4range(1,3));
select upper_inc(int4range(1,5));
无界范围
范围的下限可以省略,这意味着所有小于上限的值都包含在范围内,例如 (,3]。同样,如果范围的上限被省略,则所有大于下限包含在范围内。如果下限和上限都省略,则元素类型的所有值都被认为在范围内。将缺少的边界指定为包含会自动转换为排除,例如,[,] 被转换to (,). 您可以将这些缺失值视为 +/-infinity,但它们是特殊的范围类型值,并且被认为超出了任何范围元素类型的 +/-infinity 值。
具有“无穷大”概念的元素类型可以将它们用作显式绑定值。例如,对于时间戳范围,[today,infinity) 不包括特殊时间戳值 infinity,而 [today,infinity] 包括它,[today,) 和 [today,] 也是如此。
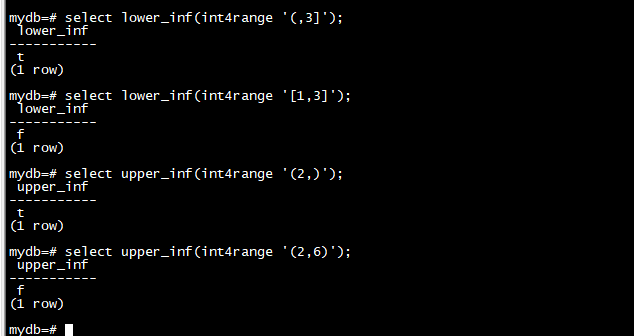
函数 lower_inf 和 upper_inf 分别测试一个范围的无限下限和上限。
select lower_inf(int4range '[1,3]');
select lower_inf(int4range '(,3]');
select upper_inf(int4range '(2,)');
select upper_inf(int4range '(2,6)');
范围值的输入必须遵循以下模式之一:
(lower-bound,upper-bound)
(lower-bound,upper-bound]
[lower-bound,upper-bound)
[lower-bound,upper-bound]
empty
如前所述,括号或方括号指示下限和上限是互斥的还是包含的。请注意,最终的模式是空的,它表示一个空范围(一个不包含点的范围)。下限可以是作为子类型有效输入的字符串,也可以是空的表示没有下限。同样,上限可以是子类型的有效输入字符串,也可以是空的表示没有上限。
例子:
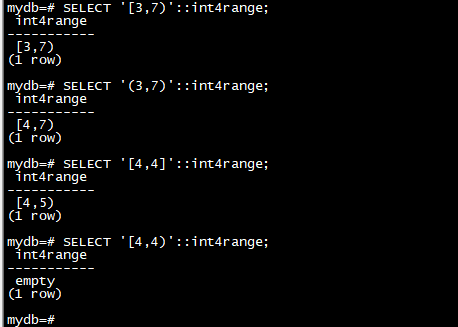
SELECT '[3,7)'::int4range;
SELECT '(3,7)'::int4range;
SELECT '[4,4]'::int4range;
SELECT '[4,4)'::int4range;
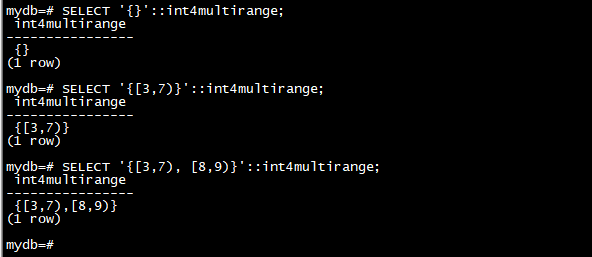
多范围的输入是包含零个或多个有效范围的大括号({ 和 }),以逗号分隔。括号和逗号周围允许有空格。
例子:
SELECT '{}'::int4multirange;
SELECT '{[3,7)}'::int4multirange;
SELECT '{[3,7), [8,9)}'::int4multirange;
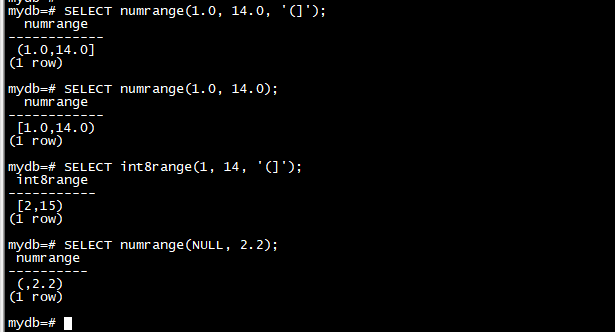
每个范围类型都有一个与范围类型同名的构造函数。使用构造函数通常比编写范围文字常量更方便,因为它避免了对绑定值的额外引用。构造函数接受两个或三个参数。双参数形式以标准形式构造范围(包括下限,不包括上限),而三参数形式构造具有由第三个参数指定的形式的范围的范围。第三个参数必须是字符串“()”、“(]”、“[)”或“[]”之一。例如:
SELECT numrange(1.0, 14.0, '(]');
SELECT numrange(1.0, 14.0);
SELECT int8range(1, 14, '(]');
SELECT numrange(NULL, 2.2);
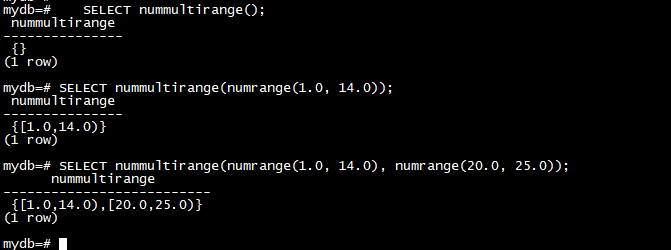
每个范围类型还具有与多范围类型同名的多范围构造函数。构造函数接受零个或多个参数,这些参数都是适当类型的范围。例如:
SELECT nummultirange();
SELECT nummultirange(numrange(1.0, 14.0));
SELECT nummultirange(numrange(1.0, 14.0), numrange(20.0, 25.0));
离散范围是其元素类型具有明确定义的“步长”的范围,例如整数或日期。在这些类型中,当两个元素之间没有有效值时,可以说它们是相邻的。这与连续范围形成对比,连续范围总是(或几乎总是)可以识别两个给定值之间的其他元素值。例如,数字类型上的范围是连续的,时间戳上的范围也是如此。(尽管时间戳的精度有限,因此理论上可以视为离散的,但最好将其视为连续的,因为步长通常不重要。)
考虑离散范围类型的另一种方法是,每个元素值都有一个“下一个”或“上一个”值的清晰概念。知道了这一点,可以通过选择下一个或前一个元素值而不是最初给定的值来在范围边界的包含表示和排除表示之间进行转换。例如,在整数范围内,类型 [4,8] 和 (3,9) 表示同一组值;但对于数字范围内的情况并非如此。
离散范围类型应该有一个规范化函数,该函数知道元素类型的所需步长。规范化函数负责将范围类型的等效值转换为具有相同表示,特别是始终包含或排除边界。如果未指定规范化函数,则具有不同格式的范围将始终被视为不相等,即使它们实际上可能表示同一组值。
内置范围类型 int4range、int8range 和 daterange 都使用包含下限但不包括上限的规范形式;那是, [)。但是,用户定义的范围类型可以使用其他约定。
用户可以定义自己的范围类型。这样做的最常见原因是使用内置范围类型中未提供的子类型的范围。例如,要定义子类型 float8 的新范围类型:
CREATE TYPE floatrange AS RANGE (
subtype = float8,
subtype_diff = float8mi
);
SELECT '[1.234, 5.678]'::floatrange;
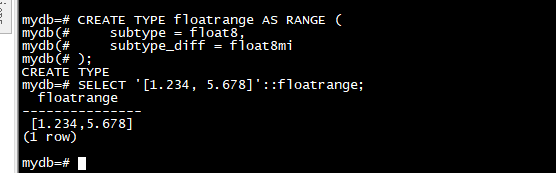
因为 float8 没有有意义的“步骤”,所以我们在这个例子中没有定义规范化函数。
当您定义自己的范围时,您会自动获得相应的多范围类型。定义自己的范围类型还允许您指定要使用的不同子类型 B-tree 运算符类或排序规则,以便更改确定哪些值落入给定范围的排序顺序。
如果子类型被认为具有离散值而不是连续值,则 CREATE TYPE 命令应指定规范函数。规范化函数采用输入范围值,并且必须返回可能具有不同边界和格式的等效范围值。代表同一组值的两个范围的规范输出必须相同,例如整数范围 [1, 7] 和 [1, 8)。您选择哪种表示形式作为规范表示并不重要,只要两个具有不同格式的等效值始终映射到具有相同格式的相同值即可。除了调整包含/排除边界格式之外,规范化函数可能会舍入边界值,以防所需的步长大于子类型能够存储的步长。例如,可以将时间戳上的范围类型定义为一个小时的步长,在这种情况下,规范化函数将需要舍入不是一个小时的倍数的边界,或者可能会引发错误。
此外,任何打算与 GiST 或 SP-GiST 索引一起使用的范围类型都应定义子类型差异或 subtype_diff 函数。(如果没有 subtype_diff,索引仍然可以工作,但它可能比提供差异函数的效率低得多。)子类型差异函数接受子类型的两个输入值,并返回它们的差异(即 X 减去 Y)表示为 float8 值。在上面的示例中,可以使用作为常规 float8 减号运算符基础的函数 float8mi;但对于任何其他子类型,都需要进行一些类型转换。可能还需要一些关于如何将差异表示为数字的创造性想法。subtype_diff 函数应尽可能与所选运算符类和排序规则隐含的排序顺序一致;也就是说,根据排序顺序,只要它的第一个参数大于它的第二个参数,它的结果就应该是正数。
subtype_diff 函数的一个不太简单的示例是:
CREATE FUNCTION time_subtype_diff(x time, y time) RETURNS float8 AS
'SELECT EXTRACT(EPOCH FROM (x - y))' LANGUAGE sql STRICT IMMUTABLE;
CREATE TYPE timerange AS RANGE (
subtype = time,
subtype_diff = time_subtype_diff
);
SELECT '[11:10, 23:00]'::timerange;

可以为范围类型的表列创建 GiST 和 SP-GiST 索引。还可以为多范围类型的表列创建 GiST 索引。例如,要创建一个 GiST 索引:
CREATE INDEX reservation_idx ON reservation USING GIST (during);
范围上的 GiST 或 SP-GiST 索引可以加速涉及以下范围运算符的查询:=、&&、<@、@>、<<、>>、-|-、&< 和 &>。多范围的 GiST 索引可以加速涉及同一组多范围运算符的查询。范围上的 GiST 索引和多范围上的 GiST 索引也可以相应地加速涉及这些跨类型范围到多范围和多范围到范围运算符的查询:&&、<@、@>、<<、>>、-|-、&<、和&>。
此外,还可以为范围类型的表列创建 B-tree 和 hash 索引。对于这些索引类型,基本上唯一有用的范围操作是相等。为范围值定义了一个 B-tree 排序排序,并带有相应的 < 和 > 运算符,但排序相当随意,在现实世界中通常没有用处。范围类型的 B-tree 和散列支持主要是为了允许在查询内部进行排序和散列,而不是创建实际索引。
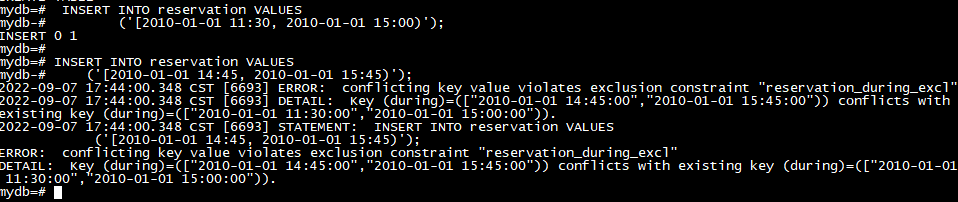
虽然 UNIQUE 是对标量值的自然约束,但它通常不适用于范围类型。相反,排除约束通常更合适。排除约束允许在范围类型上指定约束,例如“不重叠”。例如:
CREATE TABLE reservation (
during tsrange,
EXCLUDE USING GIST (during WITH &&)
);
该约束将防止表中同时存在任何重叠值:
INSERT INTO reservation VALUES
('[2010-01-01 11:30, 2010-01-01 15:00)');
INSERT INTO reservation VALUES
('[2010-01-01 14:45, 2010-01-01 15:45)');
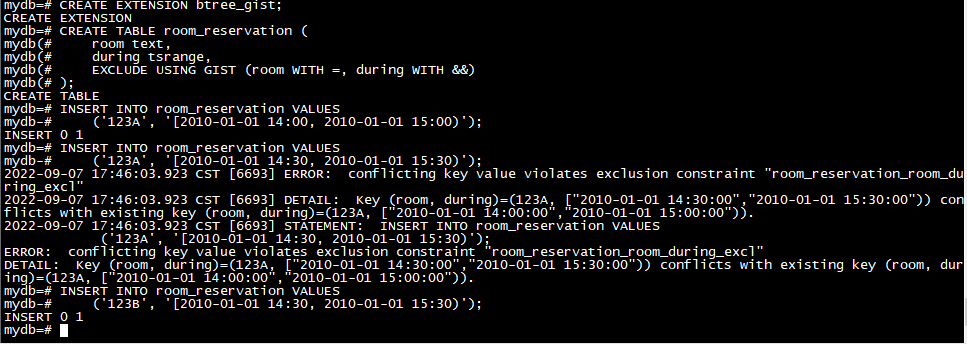
您可以使用 btree_gist 扩展来定义纯标量数据类型的排除约束,然后可以将其与范围排除相结合以获得最大的灵活性。例如,安装 btree_gist 后,仅当会议室编号相等时,以下约束才会拒绝重叠范围:
CREATE EXTENSION btree_gist;
CREATE TABLE room_reservation (
room text,
during tsrange,
EXCLUDE USING GIST (room WITH =, during WITH &&)
);
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:00, 2010-01-01 15:00)');
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:30, 2010-01-01 15:30)');
INSERT INTO room_reservation VALUES
('123B', '[2010-01-01 14:30, 2010-01-01 15:30)');
二、Domain 类型
域是基于另一种基础类型的用户定义数据类型。可选地,它可以具有将其有效值限制为基础类型允许的子集的约束。否则,它的行为就像基础类型一样——例如,任何可以应用于基础类型的运算符或函数都将适用于域类型。基础类型可以是任何内置或用户定义的基本类型、枚举类型、数组类型、复合类型、范围类型或其他域。
例如,我们可以创建一个只接受正整数的整数域:
CREATE DOMAIN posint AS integer CHECK (VALUE > 0);
CREATE TABLE mytable (id posint);
INSERT INTO mytable VALUES(1);
INSERT INTO mytable VALUES(-1);
当基础类型的运算符或函数应用于域值时,域会自动向下转换为基础类型。因此,例如,mytable.id - 1 的结果被认为是整数类型而不是正整数。我们可以编写 (mytable.id - 1)::posint 将结果转换回 posint,从而重新检查域的约束。在这种情况下,如果将表达式应用于 id 值 1,则会导致错误。允许将基础类型的值分配给域类型的字段或变量,而无需编写显式强制转换,但域的将检查约束。
select (id-1)::posint from mytable;

三、Object Identifier 类型
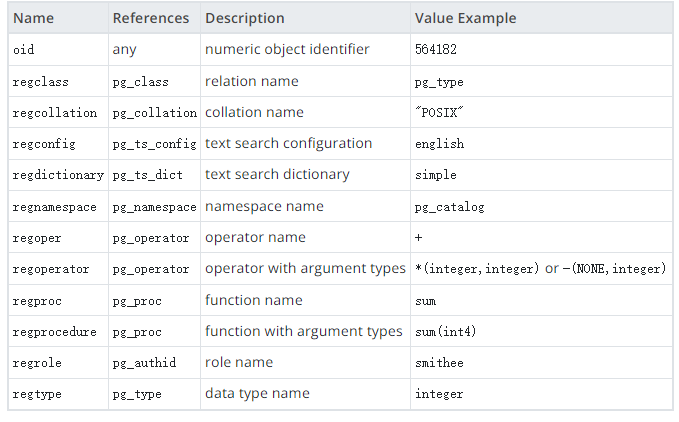
PostgreSQL 在内部使用对象标识符 (OID) 作为各种系统表的主键。类型 oid 表示对象标识符。oid 也有几种别名类型,每一种都命名为 regsomething。
oid 类型当前实现为无符号四字节整数。因此,它不足以在大型数据库甚至大型单个表中提供数据库范围的唯一性。
oid 类型本身几乎没有可比性的操作。但是,它可以转换为整数,然后使用标准整数运算符进行操作。
除了专门的输入和输出例程外,OID 别名类型没有自己的操作。这些例程能够接受和显示系统对象的符号名称,而不是类型 oid 将使用的原始数值。别名类型允许对对象的 OID 值进行简化查找。例如,要检查与表 mytable 相关的 pg_attribute 行,可以编写:
SELECT * FROM pg_attribute WHERE attrelid = 'mytable'::regclass;
而不是:
SELECT * FROM pg_attribute
WHERE attrelid = (SELECT oid FROM pg_class WHERE relname = 'mytable');
虽然这本身看起来并没有那么糟糕,但它仍然过于简单化了。如果在不同的模式中有多个名为 mytable 的表,则需要更复杂的子选择来选择正确的 OID。regclass 输入转换器根据模式路径设置处理表查找,因此它会自动执行“正确的事情”。同样,将表的 OID 转换为 regclass 对于数字 OID 的符号显示很方便。
按命名空间分组的对象的所有 OID 别名类型都接受模式限定名称,并且如果在当前搜索路径中找不到对象而没有经过限定,则将在输出中显示模式限定名称。例如,myschema.mytable 是 regclass 可接受的输入(如果有这样的表)。该值可能会输出为 myschema.mytable,或者只是 mytable,具体取决于当前的搜索路径。regproc 和 regoper 别名类型将只接受唯一的输入名称(未重载),因此它们的用途有限;对于大多数用途,regprocedure 或 regoperator 更合适。对于 regoperator,一元运算符通过为未使用的操作数写入 NONE 来标识。
这些类型的输入函数允许标记之间有空格,并将大写字母折叠成小写字母,双引号内除外;这样做是为了使语法规则类似于用 SQL 编写对象名称的方式。相反,如果需要使输出成为有效的 SQL 标识符,输出函数将使用双引号。例如,一个名为 Foo(大写 F)的函数的 OID 可以使用两个整数参数输入为 ' "Foo" ( int, integer ) '::regprocedure。输出看起来像“Foo”(整数,整数)。函数名称和参数类型名称也可以是模式限定的。
许多内置的 PostgreSQL 函数接受表的 OID 或其他类型的数据库对象,并且为了方便起见被声明为采用 regclass (或适当的 OID 别名类型)。这意味着您不必手动查找对象的 OID,而只需将其名称作为字符串文字输入即可。例如, nextval(regclass) 函数采用序列关系的 OID,因此您可以这样调用它:
nextval('foo') --对序列 foo 进行操作
nextval('FOO') --和上面一样
nextval('"Foo"') --对序列 Foo 进行操作
nextval('myschema.foo') --在 myschema.foo 上运行
nextval('"myschema".foo') --和上面一样
nextval('foo') --搜索 foo 的搜索路径
另一个使用 regclass 的实际示例是查找 information_schema 视图中列出的表的 OID,这些视图不直接提供此类 OID。例如,可能希望调用需要表 OID 的 pg_relation_size() 函数。考虑到上述规则,正确的做法是
SELECT table_schema, table_name,
pg_relation_size((quote_ident(table_schema) || '.' ||
quote_ident(table_name))::regclass)
FROM information_schema.tables;
quote_ident() 函数将负责在需要时对标识符进行双引号。看似简单的
SELECT pg_relation_size(table_name)
FROM information_schema.tables;
不建议这样做,因为对于位于搜索路径之外或名称需要引用的表,它将失败。
大多数 OID 别名类型的另一个属性是创建依赖项。如果其中一种类型的常量出现在存储表达式(例如列默认表达式或视图)中,它会创建对引用对象的依赖关系。例如,如果一个列有一个默认表达式 nextval('my_seq'::regclass),PostgreSQL 理解默认表达式依赖于序列 my_seq,所以系统不会在没有先删除默认表达式的情况下让序列被删除。nextval('my_seq'::text) 的替代方案不会创建依赖项。(regrole 是该属性的一个例外。存储表达式中不允许使用这种类型的常量。)
系统使用的另一种标识符类型是 xid,或事务(缩写为 xact)标识符。这是系统列 xmin 和 xmax 的数据类型。事务标识符是 32 位的数量。在某些情况下,使用 64 位变体 xid8。与 xid 值不同的是,xid8 值严格单调递增,并且不能在数据库集群的生命周期内重复使用。
系统使用的第三种标识符类型是 cid 或命令标识符。这是系统列 cmin 和 cmax 的数据类型。命令标识符也是 32 位数量。
系统使用的最终标识符类型是 tid,或元组标识符(行标识符)。这是系统列 ctid 的数据类型。元组 ID 是一对(块编号,块内的元组索引),用于标识行在其表中的物理位置。
四、pg_lsn 类型
pg_lsn 数据类型可用于存储 LSN(日志序列号)数据,它是指向 WAL 中某个位置的指针。此类型是 XLogRecPtr 的一种表示形式和 PostgreSQL 的内部系统类型。
在内部,LSN 是一个 64 位整数,表示预写日志流中的一个字节位置。它打印为两个最多 8 位的十六进制数字,用斜杠分隔;例如,16/B374D848。pg_lsn 类型支持标准比较运算符,例如 = 和 >。可以使用 - 运算符减去两个 LSN;结果是分隔这些预写日志位置的字节数。此外,可以分别使用 +(pg_lsn,numeric) 和 -(pg_lsn,numeric) 运算符在 LSN 中添加和减去字节数。注意计算的 LSN 应该在 pg_lsn 类型的范围内,即在 0/0 和 FFFFFFFF/FFFFFFFF 之间。
五、Pseudo 类型
PostgreSQL 类型系统包含许多特殊用途的条目,统称为伪类型。伪类型不能用作列数据类型,但可以用于声明函数的参数或结果类型。在函数的行为不对应于简单地获取或返回特定 SQL 数据类型的值的情况下,每种可用的伪类型都很有用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!