
PostgreSQL-数据类型2
一、Enumerated 类型
枚举(enum)类型是包含一组静态、有序值的数据类型。它们等效于许多编程语言中支持的枚举类型。枚举类型的一个示例可能是星期几,或者是一组数据的状态值。
枚举类型是使用 CREATE TYPE 命令创建的,例如:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
创建后,枚举类型可以像任何其他类型一样在表和函数定义中使用:
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
INSERT INTO person VALUES ('Moe', 'queit');

枚举类型中值的顺序是创建类型时列出的值的顺序。枚举支持所有标准比较运算符和相关的聚合函数。例如:
INSERT INTO person VALUES ('Larry', 'sad');
INSERT INTO person VALUES ('Curly', 'ok');
SELECT * FROM person WHERE current_mood > 'sad';
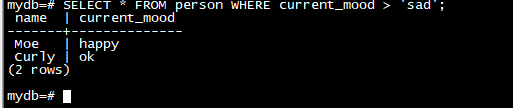
SELECT * FROM person WHERE current_mood > 'sad' ORDER BY current_mood;

SELECT name
FROM person
WHERE current_mood = (SELECT MIN(current_mood) FROM person);

每个枚举数据类型都是独立的,不能与其他枚举类型进行比较。看这个例子:
CREATE TYPE happiness AS ENUM ('happy', 'very happy', 'ecstatic');
CREATE TABLE holidays (
num_weeks integer,
happiness happiness
);
INSERT INTO holidays(num_weeks,happiness) VALUES (4, 'happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (6, 'very happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (8, 'ecstatic');
INSERT INTO holidays(num_weeks,happiness) VALUES (2, 'sad');

如果您真的需要做类似的事情,您可以编写自定义运算符或向查询添加显式强制转换:
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood::text = holidays.happiness::text;

枚举标签区分大小写,因此“happy”与“HAPPY”不同。标签中的空白也很重要。
尽管枚举类型主要用于静态值集,但支持向现有枚举类型添加新值以及重命名值(参见 ALTER TYPE)。不能从枚举类型中删除现有值,也不能更改这些值的排序顺序,除非删除并重新创建枚举类型。
一个枚举值占用磁盘上的四个字节。枚举值的文本标签的长度受编译到 PostgreSQL 中的 NAMEDATALEN 设置的限制;在标准版本中,这意味着最多 63 个字节。
从内部枚举值到文本标签的翻译保存在系统目录 pg_enum 中。直接查询此目录可能很有用。
二、Geometric 类型
几何数据类型表示二维空间对象。

Points
点是几何类型的基本二维构建块。使用以下任一语法指定类型点的值:
( x , y )
x , y
其中 x 和 y 是各自的坐标,作为浮点数。
Lines
线由线性方程 Ax + By + C = 0 表示,其中 A 和 B 不都是零。line 类型的值按以下形式输入和输出:
{ A, B, C }
或者,可以使用以下任何形式进行输入:
[ ( x1 , y1 ) , ( x2 , y2 ) ]
( ( x1 , y1 ) , ( x2 , y2 ) )
( x1 , y1 ) , ( x2 , y2 )
x1 , y1 , x2 , y2
其中 (x1,y1) 和 (x2,y2) 是线上的两个不同点。
Boxes
盒子由盒子的对角点对表示。box 类型的值使用以下任何语法指定:
( ( x1 , y1 ) , ( x2 , y2 ) )
( x1 , y1 ) , ( x2 , y2 )
x1 , y1 , x2 , y2
其中 (x1,y1) 和 (x2,y2) 是盒子的任意两个对角。
可以在输入时提供任何两个对角,但这些值将根据需要重新排序,以按该顺序存储右上角和左下角。
Paths
路径由连接点列表表示。路径可以是开放的,列表中的第一个和最后一个点被认为是未连接的,也可以是封闭的,其中第一个和最后一个点被认为是连接的。
使用以下任何语法指定类型路径的值:
[ ( x1 , y1 ) , ... , ( xn , yn ) ]
( ( x1 , y1 ) , ... , ( xn , yn ) )
( x1 , y1 ) , ... , ( xn , yn )
( x1 , y1 , ... , xn , yn )
x1 , y1 , ... , xn , yn
其中这些点是构成路径的线段的端点。方括号 ([]) 表示开放路径,圆括号 (()) 表示封闭路径。当最外层的括号被省略时,如在第三到第五个语法中,假定一个闭合路径。
Polygons(多边形)
多边形由点列表(多边形的顶点)表示。多边形与封闭路径非常相似,但存储方式不同,并且有自己的一组支持例程。
使用以下任何语法指定多边形类型的值:
( ( x1 , y1 ) , ... , ( xn , yn ) )
( x1 , y1 ) , ... , ( xn , yn )
( x1 , y1 , ... , xn , yn )
x1 , y1 , ... , xn , yn
其中这些点是构成多边形边界的线段的端点。
Circles
圆由中心点和半径表示。circle 类型的值使用以下任何语法指定:
< ( x , y ) , r >
( ( x , y ) , r )
( x , y ) , r
x , y , r
其中 (x,y) 是圆心,r 是圆的半径。
三、Network Address 类型
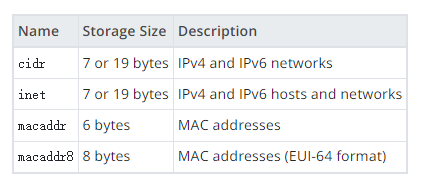
PostgreSQL 提供数据类型来存储 IPv4、IPv6 和 MAC 地址,如下表所示。最好使用这些类型而不是纯文本类型来存储网络地址,因为这些类型提供输入错误检查和专门的运算符和函数。
在对 inet 或 cidr 数据类型进行排序时,IPv4 地址将始终排在 IPv6 地址之前,包括封装或映射到 IPv6 地址的 IPv4 地址,例如 ::10.2.3.4 或 ::ffff:10.4.3.2。
inet
inet 类型在一个字段中包含 IPv4 或 IPv6 主机地址,以及可选的子网。子网由主机地址中存在的网络地址位数(“网络掩码”)表示。如果网络掩码为 32 且地址为 IPv4,则该值不表示子网,仅表示单个主机。在 IPv6 中,地址长度为 128 位,因此 128 位指定了唯一的主机地址。请注意,如果您只想接受网络,您应该使用 cidr 类型而不是 inet。
此类型的输入格式是address/y,其中address是 IPv4 或 IPv6 地址,y 是网络掩码中的位数。如果省略 /y 部分,则网络掩码对于 IPv4 为 32,对于 IPv6 为 128,因此该值仅表示单个主机。在显示中,如果网络掩码指定单个主机,则 /y 部分将被禁止。
** cidr**
cidr 类型包含 IPv4 或 IPv6 网络规范。输入和输出格式遵循无类 Internet 域路由约定。指定网络的格式是address/y,其中address是网络的最低地址,表示为 IPv4 或 IPv6 地址,y 是网络掩码中的位数。如果省略 y,则使用旧有类网络编号系统的假设进行计算,除非它至少足够大以包含输入中写入的所有八位字节。指定将位设置在指定网络掩码右侧的网络地址是错误的。
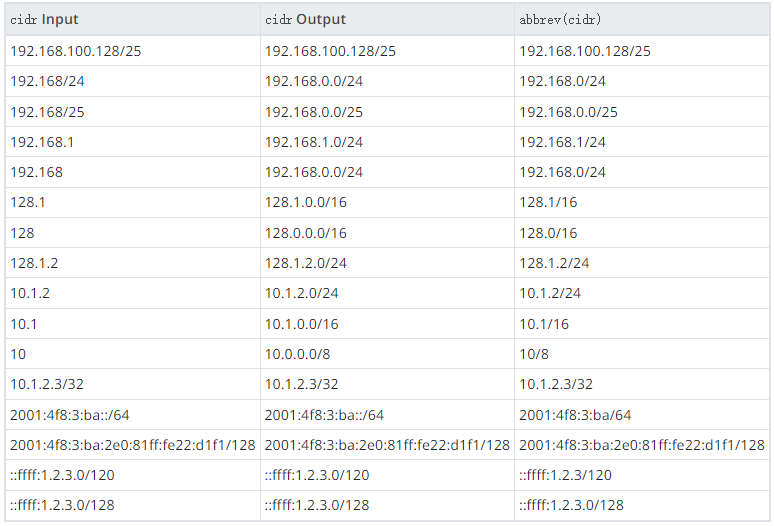
inet vs. cidr
inet 和 cidr 数据类型之间的本质区别在于 inet 接受网络掩码右侧具有非零位的值,而 cidr 不接受。例如,192.168.0.1/24 对 inet 有效,但对 cidr 无效。
macaddr
macaddr 类型存储 MAC 地址,例如从以太网卡硬件地址(尽管 MAC 地址也用于其他目的)。接受以下格式的输入:
'08:00:2b:01:02:03'
'08-00-2b-01-02-03'
'08002b:010203'
'08002b-010203'
'0800.2b01.0203'
'0800-2b01-0203'
'08002b010203'
IEEE 标准 802-2001 指定显示的第二种形式(带连字符)作为 MAC 地址的规范形式,并指定第一种形式(带冒号)与位反转、MSB 优先表示法一起使用,因此 08-00-2b-01-02-03 = 10:00:D4:80:40:C0。这种约定如今被广泛忽略,仅与过时的网络协议(例如令牌环)相关。PostgreSQL 没有为位反转做任何规定;所有接受的格式都使用规范的 LSB 顺序。
macaddr8
macaddr8 类型以 EUI-64 格式存储 MAC 地址,例如以太网卡硬件地址(尽管 MAC 地址也用于其他目的)。这种类型可以接受 6 和 8 字节长度的 MAC 地址,并以 8 字节长度的格式存储它们。以 6 字节格式给出的 MAC 地址将以 8 字节长度格式存储,第 4 和第 5 字节分别设置为 FF 和 FE。请注意,IPv6 使用修改后的 EUI-64 格式,其中第 7 位应在从 EUI-48 转换后设置为 1。提供了函数 macaddr8_set7bit 来进行此更改。一般来说,任何由成对的十六进制数字(在字节边界上)组成的输入,可选地由“:”、“-”或“.”之一一致地分隔,都被接受。十六进制数字的数量必须是 16(8 字节)或 12(6 字节)。忽略前导和尾随空格。以下是可接受的输入格式示例:
'08:00:2b:01:02:03:04:05'
'08-00-2b-01-02-03-04-05'
'08002b:0102030405'
'08002b-0102030405'
'0800.2b01.0203.0405'
'0800-2b01-0203-0405'
'08002b01:02030405'
'08002b0102030405'
要将 EUI-48 格式的传统 48 位 MAC 地址转换为修改后的 EUI-64 格式以作为 IPv6 地址的主机部分包含,请使用 macaddr8_set7bit,如下所示:
SELECT macaddr8_set7bit('08:00:2b:01:02:03');

四、Bit String 类型
Bit strings是 1 和 0 的字符串。它们可用于存储或可视化位掩码。有两种 SQL 位类型:bit(n) 和 bit varying(n),其中 n 是一个正整数。
位类型数据必须与长度 n 完全匹配;尝试存储较短或较长的位串是错误的。位变化数据是可变长度的,最大长度为 n;较长的字符串将被拒绝。写入没有长度的位相当于位(1),而没有长度规范的位变化意味着无限长度。
如果将一个位串值显式转换为 bit(n),它将被截断或在右侧补零以恰好是 n 位,而不会引发错误。类似地,如果将一个位串值显式转换为位可变(n),如果它超过 n 位,它将在右侧被截断。
例子:
CREATE TABLE test (a BIT(3), b BIT VARYING(5));
INSERT INTO test VALUES (B'101', B'00');
INSERT INTO test VALUES (B'10', B'101');

INSERT INTO test VALUES (B'10'::bit(3), B'101');
SELECT * FROM test;

位串值每组 8 位需要 1 个字节,外加 5 或 8 个字节的开销,具体取决于字符串的长度(但长值可能会被压缩或移出线外)。
五、Text Search 类型
PostgreSQL 提供了两种数据类型,旨在支持全文搜索,即在自然语言文档集合中搜索以找到与查询最匹配的那些活动。tsvector 类型表示为文本搜索优化的形式的文档;tsquery 类型同样代表一个文本查询。
tsvector
tsvector 值是不同词位的排序列表,这些词位是经过规范化以合并同一词的不同变体的词)。排序和重复消除在输入过程中自动完成,如下例所示:
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;

要表示包含空格或标点符号的词位,请用引号将它们括起来:
SELECT $$the lexeme ' ' contains spaces$$::tsvector;

SELECT $$the lexeme 'Joe''s' contains a quote$$::tsvector;

可选地,整数位置可以附加到词位:
SELECT 'a:1 fat:2 cat:3 sat:4 on:5 a:6 mat:7 and:8 ate:9 a:10 fat:11 rat:12'::tsvector;

位置通常指示源词在文档中的位置。位置信息可用于邻近度排名。位置值的范围可以从 1 到 16383;较大的数字被静默设置为 16383。相同词位的重复位置被丢弃。
具有位置的词素可以进一步用权重标记,可以是 A、B、C 或 D。D 是默认值,因此不会显示在输出中:
SELECT 'a:1A fat:2B,4C cat:5D'::tsvector;

权重通常用于反映文档结构,例如通过标记标题词与正文词不同。文本搜索排名功能可以为不同的权重标记分配不同的优先级。
重要的是要了解 tsvector 类型本身不执行任何单词归一化;它假定它给出的单词已针对应用程序进行了适当的规范化。例如,
SELECT 'The Fat Rats'::tsvector;

对于大多数英文文本搜索应用程序,上述单词将被视为非规范化,但 tsvector 不在乎。原始文档文本通常应通过 to_tsvector 传递以适当地标准化单词以进行搜索:
SELECT to_tsvector('english', 'The Fat Rats');

tsquery
tsquery 值存储要搜索的词位,并且可以使用布尔运算符 & (AND)、| 将它们组合起来。(或),和!(NOT),以及短语搜索运算符 <-> (FOLLOWED BY)。FOLLOWED BY 运算符还有一个变体
括号可用于强制对这些运算符进行分组。在没有括号的情况下,!(NOT) 绑定最紧密,<-> (FOLLOWED BY) 紧接着,然后是 & (AND),与 |(或)结合得最不紧密。
例子:
SELECT 'fat & rat'::tsquery;

SELECT 'fat & (rat | cat)'::tsquery;

SELECT 'fat & rat & ! cat'::tsquery;

可选地,可以用一个或多个权重字母标记 tsquery 中的词位,这限制它们仅匹配具有这些权重之一的 tsvector 词位:
SELECT 'fat:ab & cat'::tsquery;

此外,可以用 * 标记 tsquery 中的词位以指定前缀匹配:
SELECT 'super:*'::tsquery;

此查询将匹配 tsvector 中以“super”开头的任何单词。
词位的引用规则与前面描述的 tsvector 中的词位相同;并且,与 tsvector 一样,必须在转换为 tsquery 类型之前对单词进行任何所需的规范化。to_tsquery 函数便于执行这样的规范化:
SELECT to_tsquery('Fat:ab & Cats');

请注意,to_tsquery 将以与其他单词相同的方式处理前缀,这意味着此比较返回 true:
SELECT to_tsvector( 'postgraduate' ) @@ to_tsquery( 'postgres:*' );

因为 postgres 被限制为 postgr:
SELECT to_tsvector( 'postgraduate' ), to_tsquery( 'postgres:*' );

六、UUID 类型
数据类型 uuid 存储由 RFC 4122、ISO/IEC 9834-8:2005 和相关标准定义的通用唯一标识符 (UUID)。(有些系统将此数据类型称为全局唯一标识符或 GUID。)此标识符是一个 128 位的数量,由选择的算法生成,以使其他人不太可能生成相同的标识符在已知的宇宙中使用相同的算法。因此,对于分布式系统,这些标识符提供了比仅在单个数据库中唯一的序列生成器更好的唯一性保证。
一个 UUID 被写成一系列小写十六进制数字,分几组,用连字符隔开,具体是一组 8 位数字,后跟三组 4 位数字,然后是一组 12 位数字,总共 32 位数字表示128 位。此标准形式的 UUID 示例如下:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
PostgreSQL 也接受以下替代形式的输入:使用大写数字,用大括号括起来的标准格式,省略部分或全部连字符,在任何四位数字组后添加连字符。例子是:
A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11
{a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11}
a0eebc999c0b4ef8bb6d6bb9bd380a11
a0ee-bc99-9c0b-4ef8-bb6d-6bb9-bd38-0a11
{a0eebc99-9c0b4ef8-bb6d6bb9-bd380a11}
七、XML 类型
xml 数据类型可用于存储 XML 数据。与将 XML 数据存储在文本字段中相比,它的优势在于它检查输入值的格式是否正确,并且有支持函数对其执行类型安全操作。使用此数据类型需要使用 configure --with-libxml 构建安装。
xml 类型可以存储由 XML 标准定义的格式良好的“文档”,以及通过引用 XQuery 和 XPath 数据模型的更宽松的“文档节点”来定义的“内容”片段。粗略地说,这意味着内容片段可以有多个顶级元素或字符节点。表达式 xmlvalue IS DOCUMENT 可用于评估特定 xml 值是完整文档还是仅是内容片段。
要从字符数据生成 xml 类型的值,请使用函数 xmlparse:
XMLPARSE ( { DOCUMENT | CONTENT } value)
例子:
select XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>');

select XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>');

虽然这是根据 SQL 标准将字符串转换为 XML 值的唯一方法,但 PostgreSQL 特定的语法:
select xml '<foo>bar</foo>';
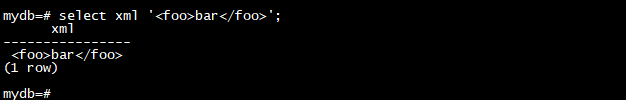
select '<foo>bar</foo>'::xml;

xml 类型不会根据文档类型声明 (DTD) 验证输入值,即使输入值指定了 DTD。目前还没有内置支持针对其他 XML 模式语言(例如 XML 模式)进行验证。
从 xml 生成字符串值的逆操作使用函数 xmlserialize:
XMLSERIALIZE ( { DOCUMENT | CONTENT } value AS type )
type 可以是字符、可变字符或文本(或其中之一的别名)。同样,根据 SQL 标准,这是在 xml 类型和字符类型之间进行转换的唯一方法,但 PostgreSQL 还允许您简单地转换值。
例子:
select xmlserialize(document '<foo>bar</foo>'::xml as varchar(30));

当字符串值在不通过 XMLPARSE 或 XMLSERIALIZE 的情况下分别转换为 xml 类型或从 xml 类型转换时,DOCUMENT 与 CONTENT 的选择由“XML 选项”会话配置参数确定,可以使用标准命令进行设置:
SET XML OPTION { DOCUMENT | CONTENT };
或更类似于 PostgreSQL 的语法:
SET xmloption TO { DOCUMENT | CONTENT };
默认值为 CONTENT,因此允许所有形式的 XML 数据。
在客户端、服务器和通过它们传递的 XML 数据中处理多个字符编码时必须小心。当使用文本模式向服务器传递查询并将查询结果传递给客户端时(这是普通模式),PostgreSQL 将客户端和服务器之间传递的所有字符数据转换为各自端的字符编码。这包括 XML 值的字符串表示形式,例如上面的示例。这通常意味着包含在 XML 数据中的编码声明可能会因为字符数据在客户端和服务器之间传输时被转换为其他编码而变得无效,因为嵌入的编码声明不会更改。为了应对这种行为,包含在输入到 xml 类型的字符串中的编码声明将被忽略,并且内容被假定为当前服务器编码。因此,为了正确处理,必须从客户端以当前客户端编码发送 XML 数据的字符串。客户端有责任在将文档发送到服务器之前将其转换为当前的客户端编码,或者适当地调整客户端编码。在输出时,xml 类型的值将没有编码声明,并且客户端应该假定所有数据都在当前客户端编码中。
使用二进制方式将查询参数传递给服务器,将查询结果返回给客户端时,没有进行编码转换,所以情况有所不同。在这种情况下,将观察 XML 数据中的编码声明,如果不存在,则假定数据为 UTF-8(根据 XML 标准的要求;注意 PostgreSQL 不支持 UTF-16).在输出时,数据将有一个指定客户端编码的编码声明,除非客户端编码是 UTF-8,在这种情况下它将被省略。
不用说,如果 XML 数据编码、客户端编码和服务器编码相同,那么使用 PostgreSQL 处理 XML 数据的错误率将更低,效率更高。由于 XML 数据在内部以 UTF-8 进行处理,因此如果服务器编码也是 UTF-8,则计算效率最高。
xml 数据类型的不寻常之处在于它不提供任何比较运算符。这是因为对于 XML 数据没有定义良好且普遍有用的比较算法。这样做的一个后果是您无法通过将 xml 列与搜索值进行比较来检索行。因此,XML 值通常应伴随一个单独的键字段,例如 ID。比较 XML 值的另一种解决方案是首先将它们转换为字符串,但请注意,字符串比较与有用的 XML 比较方法几乎没有关系。
由于 xml 数据类型没有比较运算符,因此无法直接在此类型的列上创建索引。如果需要在 XML 数据中进行快速搜索,可能的解决方法包括将表达式转换为字符串类型并为其编制索引,或者为 XPath 表达式编制索引。当然,实际查询必须调整为按索引表达式进行搜索。
PostgreSQL 中的文本搜索功能也可用于加速 XML 数据的全文档搜索。但是,PostgreSQL 发行版中还没有必要的预处理支持。
八、JSON 类型
JSON 数据类型用于存储 JSON(JavaScript 对象表示法)数据,如 RFC 7159 中所指定。此类数据也可以存储为文本,但 JSON 数据类型具有强制每个存储值根据 JSON 规则有效的优点.还有各种 JSON 特定的函数和运算符可用于存储在这些数据类型中的数据。
PostgreSQL 提供了两种存储 JSON 数据的类型:json 和 jsonb。为了对这些数据类型实现有效的查询机制,PostgreSQL 还提供了 jsonpath 数据类型。
json 和 jsonb 数据类型接受几乎相同的值集作为输入。主要的实际区别是效率之一。json 数据类型存储输入文本的精确副本,处理函数必须在每次执行时重新解析;而 jsonb 数据以分解的二进制格式存储,由于增加了转换开销,因此输入速度稍慢,但处理速度明显加快,因为不需要重新解析。jsonb 还支持索引,这是一个显着的优势。
因为 json 类型存储了输入文本的精确副本,所以它将保留标记之间的语义无关紧要的空白,以及 JSON 对象中键的顺序。此外,如果值中的 JSON 对象多次包含相同的键,则保留所有键/值对。(处理函数将最后一个值视为有效值。)相比之下,jsonb 不保留空格,不保留对象键的顺序,也不保留重复的对象键。如果在输入中指定了重复键,则仅保留最后一个值。
一般来说,大多数应用程序应该更喜欢将 JSON 数据存储为 jsonb,除非有非常特殊的需求,例如关于对象键排序的遗留假设。
RFC 7159 指定 JSON 字符串应以 UTF8 编码。因此,除非数据库编码是 UTF8,否则 JSON 类型不可能严格遵守 JSON 规范。尝试直接包含无法在数据库编码中表示的字符将失败;相反,可以在数据库编码中表示但不能在 UTF8 中表示的字符将被允许。
RFC 7159 允许 JSON 字符串包含由 \uXXXX 表示的 Unicode 转义序列。在 json 类型的输入函数中,无论数据库编码如何,都允许 Unicode 转义,并且仅检查语法正确性(即 \u 后面的四个十六进制数字)。但是, jsonb 的输入函数更严格:它不允许对无法在数据库编码中表示的字符进行 Unicode 转义。jsonb 类型也拒绝 \u0000 (因为它不能在 PostgreSQL 的文本类型中表示),并且它坚持使用 Unicode 代理对来指定 Unicode 基本多语言平面之外的字符是正确的。有效的 Unicode 转义被转换为等效的单个字符进行存储;这包括将代理对折叠成单个字符。
例子:
SELECT '5'::json;
SELECT '[1, 2, "foo", null]'::json;
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;
SELECT '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::json;
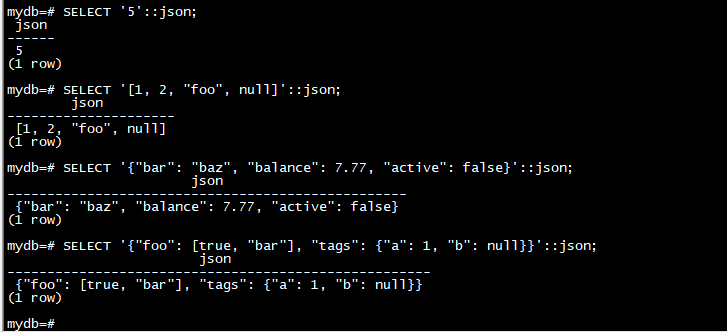
如前所述,当输入一个 JSON 值然后在没有任何额外处理的情况下打印时,json 输出与输入相同的文本,而 jsonb 不保留语义无关紧要的细节,例如空格。例如,请注意此处的差异:
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::json;
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::jsonb;
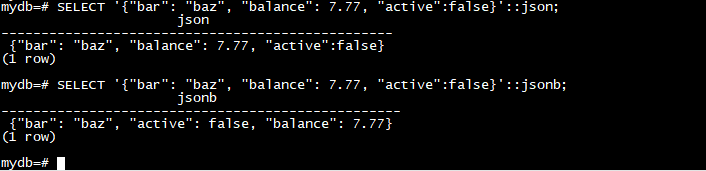
值得注意的一个语义无关紧要的细节是,在 jsonb 中,将根据底层数字类型的行为打印数字。实际上,这意味着使用 E 符号输入的数字将在没有它的情况下打印,例如:
SELECT '{"reading": 1.230e-5}'::json, '{"reading": 1.230e-5}'::jsonb;

然而, jsonb 将保留尾随小数零。
例子:
SELECT '"foo"'::jsonb @> '"foo"'::jsonb;
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
SELECT '[1, 2, 3]'::jsonb @> '[3, 1]'::jsonb;
SELECT '[1, 2, 3]'::jsonb @> '[1, 2, 2]'::jsonb;
SELECT '{"product": "PostgreSQL", "version": 9.4, "jsonb": true}'::jsonb @> '{"version": 9.4}'::jsonb;
SELECT '[1, 2, [1, 3]]'::jsonb @> '[1, 3]'::jsonb;
SELECT '[1, 2, [1, 3]]'::jsonb @> '[[1, 3]]'::jsonb;
SELECT '{"foo": {"bar": "baz"}}'::jsonb @> '{"bar": "baz"}'::jsonb;
SELECT '{"foo": {"bar": "baz"}}'::jsonb @> '{"foo": {}}'::jsonb;
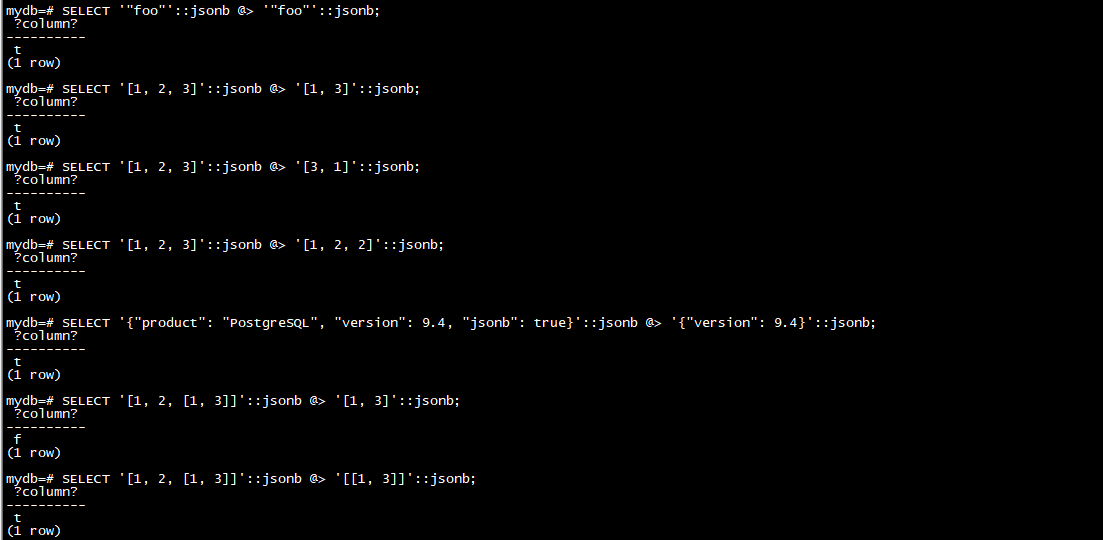

@> 表示左边的JSON值顶层是否包含右边JSON路径/值项
一般原则是包含对象必须与包含对象的结构和数据内容相匹配,可能是在从包含对象中丢弃一些不匹配的数组元素或对象键/值对之后。但请记住,在进行包含匹配时,数组元素的顺序并不重要,重复的数组元素只被有效地考虑一次。
作为结构必须匹配的一般原则的一个特殊例外,数组可能包含原始值:
SELECT '["foo", "bar"]'::jsonb @> '"bar"'::jsonb;
SELECT '"bar"'::jsonb @> '["bar"]'::jsonb;
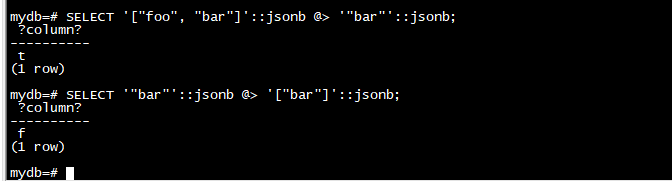
jsonb 还有一个存在操作符,它是包含主题的变体:它测试字符串(作为文本值给出)是否作为对象键或数组元素出现在 jsonb 值的顶层。这些示例返回 true,除非另有说明:
SELECT '["foo", "bar", "baz"]'::jsonb ? 'bar';
SELECT '{"foo": "bar"}'::jsonb ? 'foo';
SELECT '{"foo": "bar"}'::jsonb ? 'bar';
SELECT '{"foo": {"bar": "baz"}}'::jsonb ? 'bar';
SELECT '"foo"'::jsonb ? 'foo';
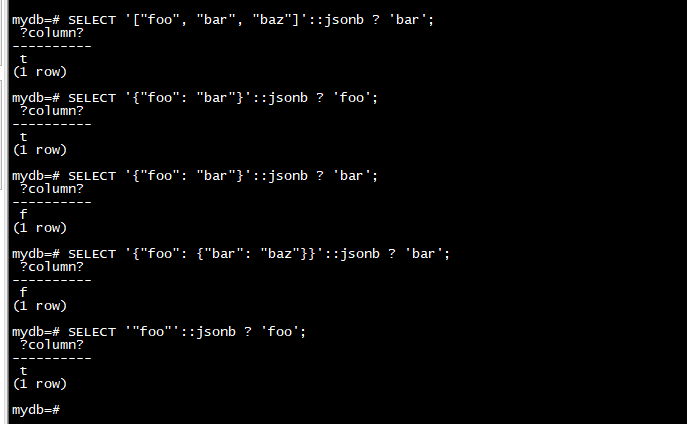
当涉及到许多键或元素时,JSON 对象比数组更适合测试包含或存在,因为与数组不同,它们在内部针对搜索进行了优化,并且不需要线性搜索。
GIN 索引可用于有效搜索大量 jsonb 文档(数据)中出现的键或键/值对。提供了两个 GIN “操作员类别”,提供了不同的性能和灵活性权衡。jsonb 的默认 GIN 运算符类支持使用键存在运算符 ?、?| 的查询和 ?&、包含运算符 @> 和 jsonpath 匹配运算符 @?和 @@。使用此运算符类创建索引的示例如下:
create table api(
id serial primary key,
jdoc jsonb
);
CREATE INDEX idxgin ON api USING GIN (jdoc);
非默认的 GIN 操作符类 jsonb_path_ops 不支持 key-exists 操作符,但它支持@>、@?和 @@。使用此运算符类创建索引的示例是:
CREATE INDEX idxginp ON api USING GIN (jdoc jsonb_path_ops);
考虑一个存储从第三方 Web 服务检索到的 JSON 文档的表的示例,该表具有文档化的模式定义。一个典型的文件是:
{
"guid": "9c36adc1-7fb5-4d5b-83b4-90356a46061a",
"name": "Angela Barton",
"is_active": true,
"company": "Magnafone",
"address": "178 Howard Place, Gulf, Washington, 702",
"registered": "2009-11-07T08:53:22 +08:00",
"latitude": 19.793713,
"longitude": 86.513373,
"tags": [
"enim",
"aliquip",
"qui"
]
}
insert into api(jdoc) values('{
"guid": "9c36adc1-7fb5-4d5b-83b4-90356a46061a",
"name": "Angela Barton",
"is_active": true,
"company": "Magnafone",
"address": "178 Howard Place, Gulf, Washington, 702",
"registered": "2009-11-07T08:53:22 +08:00",
"latitude": 19.793713,
"longitude": 86.513373,
"tags": [
"enim",
"aliquip",
"qui"
]
}'::jsonb);
我们将这些文档存储在名为 api 的表中,在名为 jdoc 的 jsonb 列中。如果在该列上创建了 GIN 索引,则可以使用该索引进行如下查询:
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @> '{"company": "Magnafone"}';

但是,索引不能用于如下查询,因为尽管运算符 ?是可索引的,它不直接应用于索引列 jdoc:
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc -> 'tags' ? 'qui';

尽管如此,通过适当使用表达式索引,上述查询可以使用索引。如果查询“tags”键中的特定项目很常见,那么定义这样的索引可能是值得的:
CREATE INDEX idxgintags ON api USING GIN ((jdoc -> 'tags'));
另一种查询方法是利用包含,例如:
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @> '{"tags": ["qui"]}';

jdoc 列上的简单 GIN 索引可以支持此查询。但请注意,这样的索引将存储 jdoc 列中每个键和值的副本,而上一个示例的表达式索引仅存储在 tags 键下找到的数据。虽然简单索引方法更加灵活(因为它支持关于任何键的查询),但目标表达式索引可能比简单索引更小且搜索速度更快。
GIN 索引也支持@?和 @@ 运算符,它们执行 jsonpath 匹配。例子是:
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @? '$.tags[*] ? (@ == "qui")';
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @@ '$.tags[*] == "qui"';
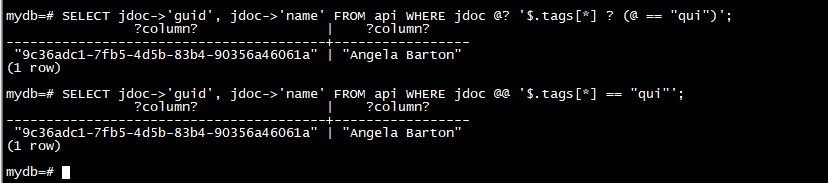
对于这些运算符,GIN 索引从 jsonpath 模式中提取 accessors_chain = constant 形式的子句,并根据这些子句中提到的键和值进行索引搜索。访问器链可能包括 .key、[] 和 [index] 访问器。jsonb_ops 运算符类也支持 . 和 .** 访问器,但 jsonb_path_ops 运算符类不支持。
虽然 jsonb_path_ops 运算符类只支持使用 @>、@? 的查询。和@@ 运算符,它比默认的运算符类 jsonb_ops 具有显着的性能优势。对于相同的数据,jsonb_path_ops 索引通常比 jsonb_ops 索引小得多,并且搜索的特异性更好,尤其是当查询包含在数据中频繁出现的键时。因此,搜索操作通常比使用默认操作符类执行得更好。
jsonb_ops 和 jsonb_path_ops GIN 索引的技术区别在于前者为数据中的每个键和值创建独立的索引项,而后者只为数据中的每个值创建索引项。基本上,每个 jsonb_path_ops 索引项都是值的哈希值和通向它的键;例如要索引 {"foo": {"bar": "baz"}},将创建一个索引项,将 foo、bar 和 baz 的所有三个合并到哈希值中。因此,查找此结构的包含查询将导致极其具体的索引搜索;但是根本没有办法找出 foo 是否作为键出现。另一方面,一个 jsonb_ops 索引会创建三个索引项,分别代表 foo、bar 和 baz;然后进行包含查询,它将查找包含所有这三个项目的行。虽然 GIN 索引可以相当有效地执行这种 AND 搜索,但它仍然不如等效的jsonb_path_ops 搜索那么具体和慢,尤其是当有大量行包含三个索引项中的任何一个时。
jsonb_path_ops 方法的一个缺点是它不会为不包含任何值的 JSON 结构生成索引条目,例如 {"a": {}}。如果请求搜索包含这种结构的文档,则需要进行全索引扫描,这非常慢。因此,jsonb_path_ops 不适合经常执行此类搜索的应用程序。
jsonb 还支持 btree 和 hash 索引。这些通常只有在检查完整 JSON 文档的相等性很重要时才有用。jsonb 数据的 btree 排序很少引起人们的兴趣,但为了完整性,它是:
Object > Array > Boolean > Number > String > Null
Object with n pairs > object with n - 1 pairs
Array with n elements > array with n - 1 elements
具有相同对数的对象按以下顺序进行比较:
key-1, value-1, key-2 ...
请注意,对象键是按其存储顺序进行比较的;特别是,由于较短的密钥存储在较长的密钥之前,这可能会导致结果可能不直观,例如:
{ "aa": 1, "c": 1} > {"b": 1, "d": 1}
同样,具有相同数量元素的数组按顺序进行比较:
element-1, element-2 ...
原始 JSON 值使用与底层 PostgreSQL 数据类型相同的比较规则进行比较。使用默认数据库排序规则比较字符串。
jsonb 下标
jsonb 数据类型支持数组样式的下标表达式来提取和修改元素。嵌套值可以通过链接下标表达式来指示,遵循与 jsonb_set 函数中的路径参数相同的规则。如果 jsonb 值是一个数组,数字下标从零开始,负整数从数组的最后一个元素开始倒数。不支持切片表达式。下标表达式的结果始终是 jsonb 数据类型。
UPDATE 语句可以在 SET 子句中使用下标来修改 jsonb 值。对于所有受影响的值,只要它们存在,下标路径必须是可遍历的。例如,路径 val['a']['b']['c'] 如果每个 val、val['a'] 和 val['a']['b'] 是一个对象。如果任何 val['a'] 或 val['a']['b'] 未定义,它将被创建为空对象并根据需要填充。但是,如果任何 val 本身或中间值之一被定义为非对象,例如字符串、数字或 jsonb null,则无法进行遍历,因此会引发错误并中止事务。
例子:
SELECT ('{"a": 1}'::jsonb)['a'];
SELECT ('{"a": {"b": {"c": 1}}}'::jsonb)['a']['b']['c'];
SELECT ('[1, "2", null]'::jsonb)[1];

update api set jdoc['is_active']='false';
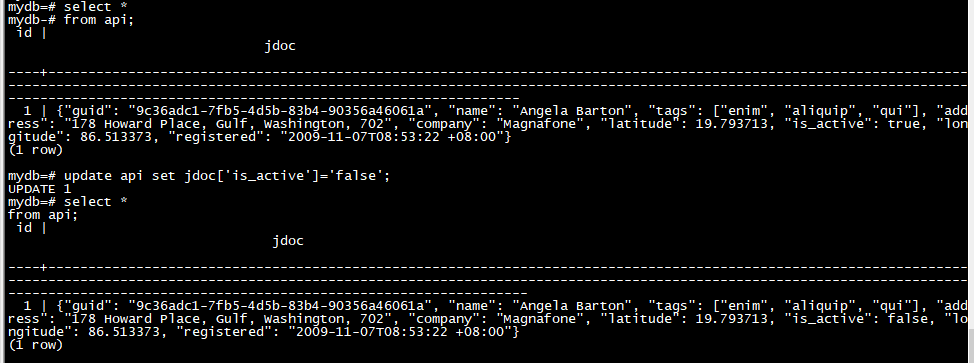
通过下标分配 jsonb 处理一些与 jsonb_set 不同的边缘情况。当源 jsonb 值为 NULL 时,通过下标分配将继续进行,就好像它是下标键所隐含的类型(对象或数组)的空 JSON 值:
update api set jdoc['a']='1' where id=2;


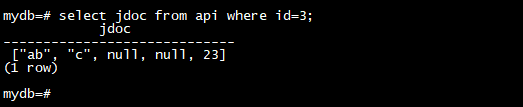
如果为包含太少元素的数组指定了索引,则将追加 NULL 元素,直到可以到达索引并且可以设置值。
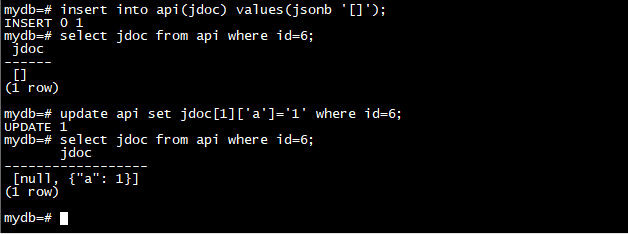
insert into api(jdoc) values(jsonb '["ab","c"]');
update api set jdoc[4]='23' where id=3;
select jdoc from api where id=3;
只要要遍历的最后一个现有元素是对象或数组,jsonb 值将接受分配给不存在的下标路径,正如相应的下标所暗示的那样(路径中最后一个下标指示的元素不会被遍历,并且可以是任何东西)。将创建嵌套数组和对象结构,在前一种情况下填充空值,由下标路径指定,直到可以放置分配的值。
insert into api(jdoc) values(jsonb '{}');
select jdoc from api where id=4;

update api set jdoc['a'][0]['b']='1' where id=4;
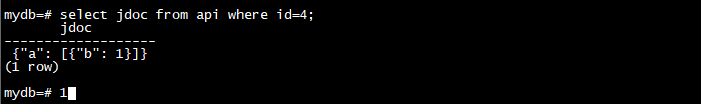
insert into api(jdoc) values(jsonb '[]');
update api set jdoc[1]['a']='1' where id=6;
jsonpath
jsonpath 类型实现了对 PostgreSQL 中 SQL/JSON 路径语言的支持,以有效地查询 JSON 数据。它提供解析的 SQL/JSON 路径表达式的二进制表示,该表达式指定路径引擎要从 JSON 数据中检索的项目,以便使用 SQL/JSON 查询函数进行进一步处理。
SQL/JSON 路径谓词和运算符的语义通常遵循 SQL。同时,为了提供一种处理 JSON 数据的自然方式,SQL/JSON 路径语法使用了一些 JavaScript 约定:
- 点 (.) 用于成员访问
- 方括号 ([]) 用于数组访问。
- SQL/JSON 数组是 0 相对的,与从 1 开始的常规 SQL 数组不同。
SQL/JSON 路径表达式通常在 SQL 查询中编写为 SQL 字符串文字,因此必须用单引号括起来,并且值中所需的任何单引号都必须加倍。某些形式的路径表达式需要在其中包含字符串文字。这些嵌入的字符串文字遵循 JavaScript/ECMAScript 约定:它们必须用双引号括起来,并且可以在其中使用反斜杠转义来表示其他难以键入的字符。特别是,在嵌入的字符串文字中写入双引号的方法是 ",而要写入反斜杠本身,您必须编写 \。其他特殊的反斜杠序列包括在 JSON 字符串中识别的那些:\b、\f、\n、\r、\t、\v 表示各种 ASCII 控制字符,\uNNNN 表示由 4 位十六进制代码点标识的 Unicode 字符。反斜杠语法还包括 JSON 不允许的两种情况:\xNN 表示仅用两个十六进制数字编写的字符代码,而 \u{N...} 是用 1 到 6 个十六进制数字编写的字符代码。
路径表达式由一系列路径元素组成,可以是以下任何一种:
- JSON 原始类型的路径文字:Unicode 文本、数字、true、false 或 null。
- jsonpath 变量
- 访问器运算符。
- jsonpath 运算符和方法。
- 括号,可用于提供过滤器表达式或定义路径评估的顺序。
jsonpath 变量:

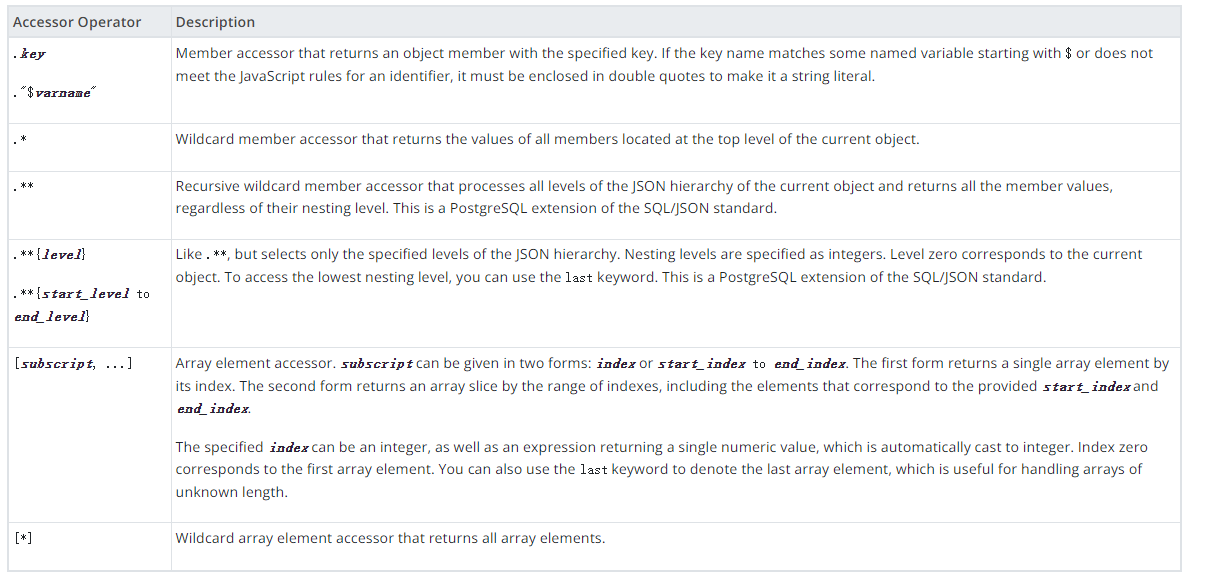
访问器运算符:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号