

redis数据类型
转自https://zhuanlan.zhihu.com/p/439930729?utm_campaign=shareopn&utm_medium=social&utm_oi=1211324772086501376&utm_psn=1541882646728187904&utm_source=wechat_session
redis数据类型
1.string:字符串,可存储数字,xml,json,png文件等。
2.list:列表,可在左边或右边增加元素,元素有序可重复。
3.hash:哈希,存储kay,value键值对
4.set:无序唯一
5.zset:有序唯一,可用于排行榜
redis数据类型对应的数据结构
| 数据类型 | redis3.2之前 | redis3.2之后 |
|---|---|---|
| string | SDS | SDS |
| ---- | ---- | ---- |
| list | 双向链表,压缩列表 | quicklist |
| ---- | ---- | ---- |
| hash | 压缩列表,哈希表 | listpack,哈希表 |
| ---- | ---- | ---- |
| set | 哈希表,整数集合 | 哈希表,整数集合 |
| ---- | ---- | ---- |
| zset | 压缩列表,跳表 | listpack,跳表 |
一、SDS(简单动态字符串)
C语言字符串的缺点:
1.获取字符串长度为O(N)
2.字符串以"\0"结尾,不能包含"\0",不能保存二进制数据
3.字符串操作函数不高效且不安全
下图就是 Redis 5.0 的 SDS 的数据结构:
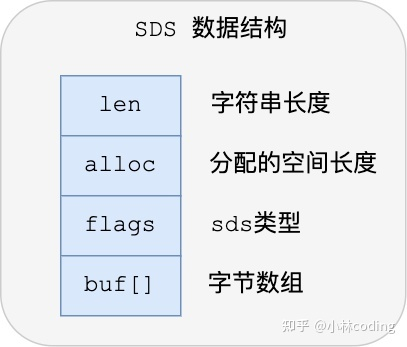
结构中的每个成员变量分别介绍下:
len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
优点:
1.O(1)获取字符串长度
2.二进制安全,用len保存字符串长度,可以包含"\0"
3.不会发生缓冲区溢出,当已分配空间不够存储时,会自动进行空间扩充;空间扩充原则是大小小于1M时翻倍扩容,大于 1MB 按 1MB 扩容,新增原来的大小,大于1M时新增1M。
4.节省内存空间
SDS 结构中有个 flags 成员变量,表示的是 SDS 类型。
Redos 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。
Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了__attribute__ ((packed)),它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。
二、双向链表
三、压缩列表(ziplist)
被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间
Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
压缩列表结构设计
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。

压缩列表在表头有三个字段:
zlbytes,记录整个压缩列表占用对内存字节数;
zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
zllen,记录压缩列表包含的节点数量;
zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
另外,压缩列表节点(entry)的构成如下:
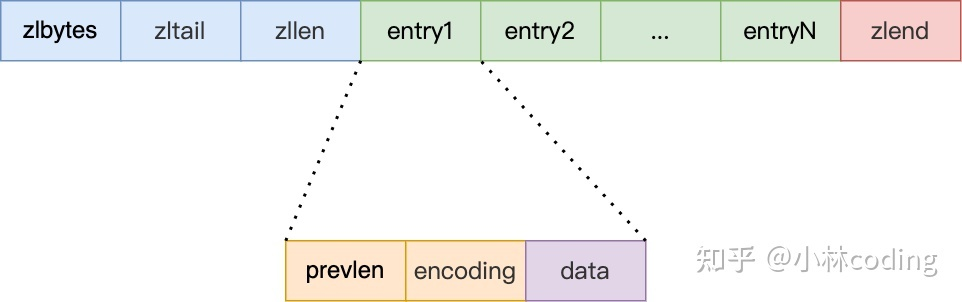
压缩列表节点包含三部分内容:
prevlen,记录了「前一个节点」的长度;
encoding,记录了当前节点实际数据的类型以及长度;
data,记录了当前节点的实际数据;
当我们往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
分别说下,prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关:
如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码。
如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码。
缺点:会发生连锁更新问题
连锁更新:压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
四、哈希表
保存键值对数据,使用链表解决哈希冲突。
渐进式哈希:
哈希表有两个哈希数组,
渐进式哈希过程:
- 给「哈希表 2」 分配空间;
- 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上;
- 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间嗲呢,会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
触发条件:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
五、整数集合
整数集合本质上是一块连续内存空间,它的结构定义如下:
点击查看代码
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
可以看到,保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
整数集合的升级操作
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
不支持降级操作,一旦对数组进行了升级,就会一直保持升级后的状态。
六、跳表
Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
点击查看代码
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
七、quicklist
quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
八、listpack
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix