JS正则表达式
定义
正则表达式可以理解成匹配符合要求的字符串的表达式,由普通字符和特殊字符构成,用来查找替换文本
创建
字面量(直接量)
在一对反斜线中写正则表达式内容,如/js/
一般多使用字面量方式,但字面量把正则“写死了”,不能改变
构造函数
构造正则表达式的实例,如new RexExp('js')
内部传入的参数为字符串/字符串的变量
如果需要根据用户输入来改变正则表达式,则用构造函数的方法创建
字符分类
普通字符
字母、数字、下划线、汉字、没有特殊含义的符号(,;!@等)
实际上不是特殊字符的字符都是普通字符
特殊字符
\:将特殊字符转义成普通字符
模式修饰符
i:ignoreCase,匹配时忽视大小写
m:multiline,多行匹配
g:global,全局匹配
字面量创建正则时,模式修饰符写在一对反斜线后
1 var find = /js/i;
构造对象创建正则时,模式修饰符作为第二个参数,传递给RexExp对象
1 var find = new RegExp('js','i');
字符匹配方式
字符类
用[]括起来,会将待匹配字符从最开头到最后挨个找,看是否有字符类中的字符,如果有,返回这个字符,否则返回null
用^表示取反,即除了字符类中的字符,其余字符只要出现就返回这个字符
用-表示范围,即只要字符出现在字符类的范围里,就返回该字符
表示范围时,范围前的字符的ASCII码必须小于等于范围后面字符,且不可跨越大小写、数字范围,不同范围之间紧密相连即可

常用字符类
.:可取到除了换行符(\n)以外的所有字符
\w:包含大小写字符、数字以及下划线
\W:包含除了大小写字符、数字以及下划线之外的字符(即\w取反)
\d:包含0-9的数字
\D:包含除了0-9数字之外的字符(即\d取反)
\s:包含空格、制表符、unicode里的多个空格符
\S:除了空格、制表符、unicode里多个空格符之外的字符(即\s取反)
以上常用字符类无需写到[]里,但也都可以写到[]中,写入多个时,只能匹配其中一类(例如\d\s只能按目标字符串顺序,匹配数字或空格)
重复
用添加在{}内的数字并放在字符类后,用以控制匹配字符类的次数
其中的数字可以写两个,逗号分隔(注意逗号和数字之间不要有空格),前面的数表示下限,后面的表示上限
下限必须小于等于上限,下限不可省略,上限可省略

数量的简写
?:表示匹配0/1次
+:表示至少匹配1次
*:表示可匹配0次及以上

非贪婪匹配
正则表达式默认贪婪匹配,例如用+规定可以匹配一个以上的字符,正则会尽可能多地去匹配,而不是取下限匹配一次
在量词({}或简写符号)后加?,就会在条件允许下尽可能少去匹配
(用课里说到的一个案例,说明只是尽可能去不贪婪)
选择
用|,表示匹配时选择其中之一即可,匹配到其中一个就输出
实际匹配时,会按照字符串中的书写顺序,从左往右找,跟正则中的选项从左向右查找,如果匹配上其中一个,就输出

分组
用()把字符类括起来,用来对整个字符类进行数量的修饰等操作,同时匹配时也会返回分组中字符类的查找结果
当不需要返回分组中的内容时(不捕获分组中的内容),在分组的内容前加上?:即可

多个括号嵌套时,从左到右以左半括号的位置,分别为第一个、第二个、第三个分组
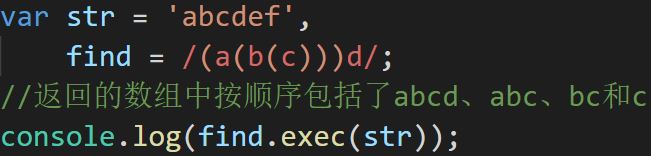
引用
对用()括起来的字符类,可以在正则表达式中用\序号的形式直接引用,其中序号表示该分组号(即是第几个分组)
引用时,该分组必须设置为捕获(即分组前不可有?:),否则返回null
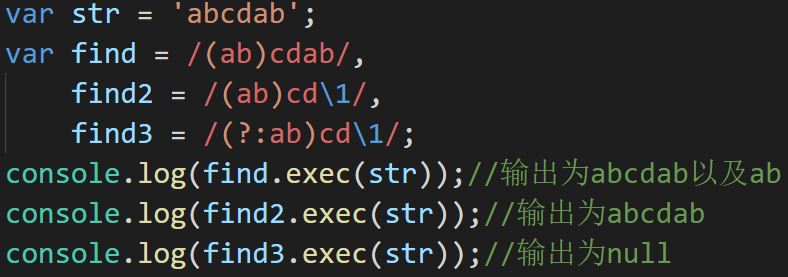
引用让后面匹配到和前面一样的内容(例如忽略大小写时保持前后匹配的大小写一致,匹配到同一个标签等)

位置匹配方式
首匹配
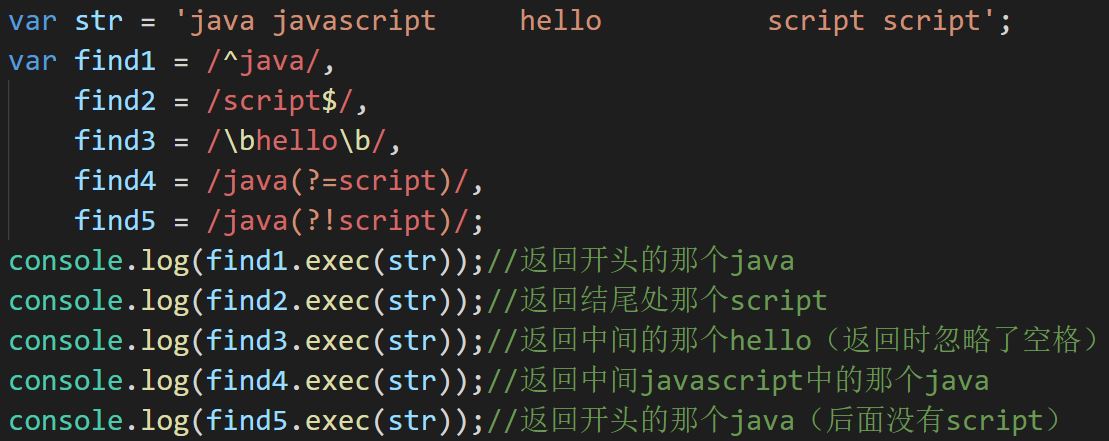
让要匹配的正则中的字符必须在原字符串中的开头
在正则表达式最开始加^(此处的^同字符类中的不同,字符类中表示取反)
尾匹配
让要匹配的正则中的字符必须在原字符串中的结尾
在正则表达式最后加$
单词边界匹配
用\b来实现(\b表示\w和\W之间的位置,即单词的开头和之前的部分的位置、单词的结尾和结尾后的部分之间的位置)
前瞻性匹配/负向前瞻性匹配
用来匹配字符串后为/不为指定字符串内容的字符串(例如匹配上java后为/不为script的)
前瞻性匹配需要在匹配的内容前加上?=,负向前瞻性则加上?!
应用
可以验证输入内容都是数字(例如用在QQ号、全是数字的密码等)


1 var find = /^\d+$/;//此处表示首尾之间全部是数字,且数字至少为1个
也可查找指定的class名称(即使class前后有多个空格)
1 function getByClassName(className,parentNode){ 2 //如果有getElementsByClassName方法,直接调用 3 if(!document.getElementByClassName){ 4 return document.getElementsByClassName(className); 5 } 6 else{ 7 //当没有传入parentNode时,自动赋值为document 8 parentNode = parentNode || document; 9 var nodeList = []; 10 //挑选出parentNode下的所有标签 11 var allNodes = parentNode.getElementsByTagName('*'); 12 //此处用正则表示匹配上classname前后有多个空格以及在首尾的情况 13 var pattern = new RegExp('(^|\\s+)'+className+'($|\\s+)'); 14 //用循环遍历,找出其中可以用正则匹配出的指定class名称的标签 15 //将这些标签装到nodeList数组中 16 for(var i=0;i<allNodes.length;i++){ 17 if(pattern.test(allNodes[i].className)){ 18 nodeList.push(allNodes[i]); 19 } 20 } 21 //完成装入,返回nodeList数组 22 return nodeList; 23 } 24 }
1 function getByClassName(className,parentNode){ 2 //如果有getElementsByClassName方法,直接调用 3 if(!document.getElementByClassName){ 4 return document.getElementsByClassName(className); 5 } 6 else{ 7 //当没有传入parentNode时,自动赋值为document 8 parentNode = parentNode || document; 9 var nodeList = []; 10 //挑选出parentNode下的所有标签 11 var allNodes = parentNode.getElementsByTagName('*'); 12 //此处用正则表示匹配上classname为一个单独单词的情况 13 var pattern = new RegExp('\\b'+className+'\\b'); 14 //用循环遍历,找出其中可以用正则匹配出的指定class名称的标签 15 //将这些标签装到nodeList数组中 16 for(var i=0;i<allNodes.length;i++){ 17 if(pattern.test(allNodes[i].className)){ 18 nodeList.push(allNodes[i]); 19 } 20 } 21 //完成装入,返回nodeList数组 22 return nodeList; 23 } 24 }
正则实例方法
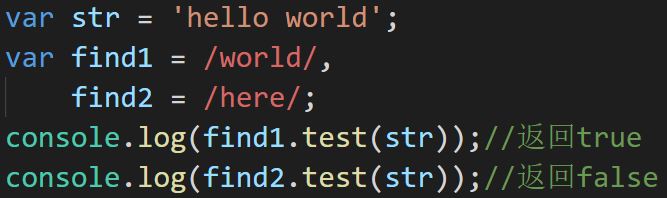
test
用来测试待检测的字符串中是否有可以匹配到正则表达式的字符串
如果有返回true,否则返回false
exec
可用来匹配字符串中符合正则表达式的字符串
如果匹配到,返回该字符串的数组(注意这个字符串本身是不带有引号的,也就是你让它匹配的文字内容),否则返回null
没写全局匹配时,只会匹配原字符串中第一个符合正则要求的字符串
添加分组时,返回符合正则表达式的内容以及分组内容,开启全局匹配不改变该结果
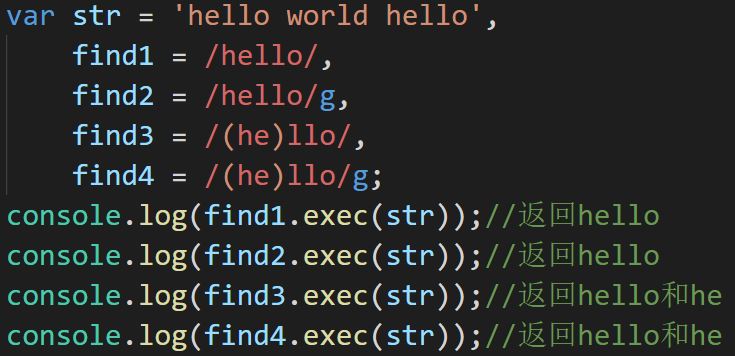
返回的数组中有以下属性:
第一个属性(0)为匹配上的字符串
index为该字符串第一个字母的起始位置
input为被匹配数组的全部内容
toString/toLocaleString
把正则表达式的内容转化成字面量形式字符串/有本地特色的字符串(JS中没效果)
valueOf
返回正则表达式本身

正则实例属性
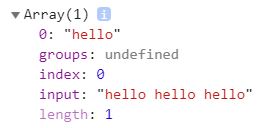
lastIndex
当没设置全局匹配时,该属性值始终为0
设置了全局匹配时,每执行一次exec/test来匹配,latIndex就会移向匹配到的字符串的下一个位置,当指向的位置后没有可以再次匹配的字符串时,下一次执行exec返回null,test执行返回false,然后lastIndex归零,从字符串的开头重新匹配一轮
可以理解成,每次正则查找的起点就是lastIndex
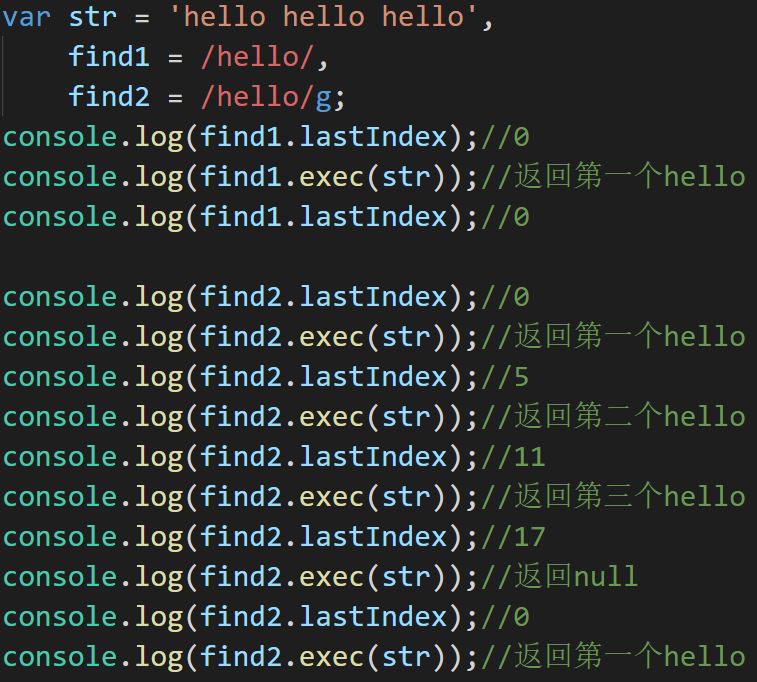
ignoreCase、global、multiline
判断正则表达式中是否有忽略大小写、全局匹配、多行匹配三个模式修饰符
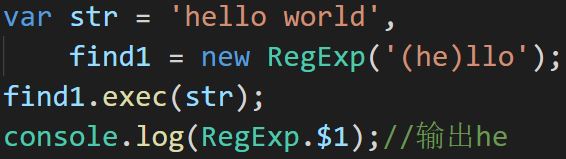
$1-9
返回正则中的分组(最多用9个分组),但必须先执行exec或test方法
source
返回字面量形式的正则表达式(类似于toString)
![]()
flags
返回正则表达式的模式匹配符
input($_)
返回正则查找的原字符串,但如果没有执行过exec或test方法,则返回undefined
lastmatch($&)(不常用)
返回最近一次匹配到的字符
left(right)Context($`或$')(不常用)
返回上次匹配左/右剩余的字符
lastParen(不常用)
返回上次通过分组捕获的子选项
String对象中和正则相关的方法
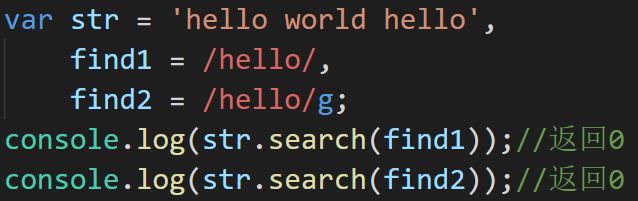
search
查找字符串中是否有匹配正则的字符串,有则返回字符串第一次出现时的位置,无则返回null
正则中无论是否有全局匹配都不会影响返回结果
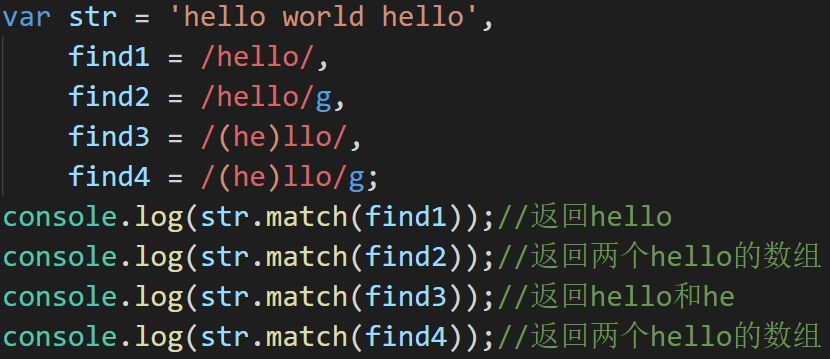
match
匹配字符串中符合正则表达式的字符串,并返回该字符串的一个数组,其中包括字符串内容、位置
如果正则设置全局匹配,则一次性返回所有符合正则表达式的字符串数组
如果其中添加了分组,返回符合要求的字符串以及分组的一个数组,但如果同时开启全局匹配则不会在数组中添加分组内容
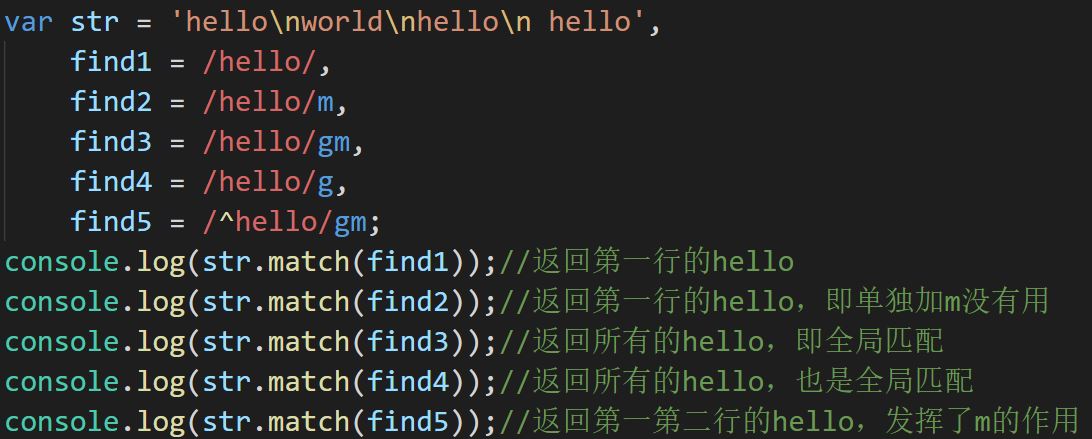
match中的正则添加了多行匹配,只有在同时添加全局匹配以及首位匹配时才起作用(例如匹配全局中每行行首的指定字符)
只添加多行匹配时同普通匹配一致,只添加多行匹配和全局匹配也和全局匹配模式一致
split
分隔字符串时,传入的参数可以是字符串(,等),也可以是正则表达式

replace
替换字符串时,参数可以传递字符串,也可为正则表达式
可以在过滤敏感词时使用(见下方案例)
1 var str = '我草草地去吃了一顿草草的饭'; 2 var find = /草/g;//设置全局匹配以屏蔽所有敏感词 3 console.log(str.replace(find,function($0){ 4 var result = ''; 5 for(var i=0;i<$0.length;i++){//获取其中敏感词的长度,添加不同数量的* 6 result += '*'; 7 } 8 return result; 9 }));
常用的正则表达式
在写正则时,需要先明确规则,然后按照规则逐条编写
建议可以把常用的正则用一个对象来包括起来,用属性名表示匹配啥,属性值表示正则
QQ号
全是数字,首位不可为0,最少5位数(目前最大11位数,可以为了未来考虑不设置上限)
1 //此处首位匹配,首位不是0,且都是数字,不少于5位 2 var findQQ = /^[1-9]\d{4,}$/;
昵称(以慕课网为例)
2-18位,中英文、数字及下划线
1 //为了匹配昵称,添加首尾匹配 2 var findname = /^[\u4e00-\u9fa5a-zA-Z0-9_{2,18}]$/; 3 //可以把英文、数字、下划线统一用\w表示 4 var findname2 = /^[\u4e00-\u9fa5\w]{2,18}$/;
密码(以慕课网为例)
6-16位,不可用空格(空白字符),区分大小写
1 //\s表示空白字符(包括空格、制表符、换行等),\S则取反 2 var findpassword = /^\S[6,16}$/; 3 // 也可用穷举 4 var findpassword2 = /^[\w~#!@$%\[\]]{6,16}$/;
去除字符串首尾的空白字符
正则也跟函数类似,不必追求用一个正则表示全部的功能,可以考虑用多个正则以增强可读性
这里也可以考虑用函数来封装正则表达式,实现去除空白的效果
1 //可以同时首尾替换,设置全局匹配 2 var deletespace = /^\s+|\s+$/g;
1 //也可用两个正则,一个用来匹配前面的空格,一个用来匹配后面的 2 var pattern1 = /^\s+/; 3 var pattern2 = /\s+$/; 4 console.log(str.replace(pattern1,'').replace(pattern2,''));
转驼峰
把连字符后的字母变成大写
1 //全局匹配所有连字符,然后找到其后面的字母,在函数中返回其大写形式 2 //考虑到要返回该字母,需要对字母进行一个分组 3 var pattern = /-([a-z])/gi; 4 console.log(str.replace(pattern,function(all,letter){ 5 return letter.toUpperCase(); 6 }));
匹配HTML标签
只是匹配HTML标签,包括开始和闭合标签,标签中的属性名和属性值
1 //先顺向思考,匹配标签名(可能有反斜杠),再匹配其中属性名和属性值 2 var tocamel = /<\/?[a-zA-Z]+(\s+[a-zA-Z]+=".*")*>/g;
1 //反向思考,一个标签中不可能有>,因此排除即可 2 var findHTML = /<[^>]+>/g;
email邮箱
@前可以是一个类似用户名的结构(字母数字下划线),也可包括.com,@后是一个至少有一个.的结构
对于这些复杂的结构,可以先分组,即搭建正则的框架,然后再去书写详细内容
1 //先搭建框架,然后最后看哪些分组不是必须的就去掉 2 var findemail = /(\w+\.)*(\w+)@(\w+\.)+([a-z])/i; 3 //拆除不必要的框架后如下 4 var findemail2 = /(?:\w+\.)*\w+@(?:\w+\.)+[a-z]/i;
1 //改变分组模式,可以理解成@前后都是一堆字母数字后加.组成的,@后的最后是字母结尾 2 var findemail3 = /^([a-z0-9]+)([_-.][a-z0-9]+)*@([a-z0-9]+)([_-.][a-z0-9]+)*\.([a-z]{2,4})$/i; 3 //拆去不需要的分组,并把不需要捕获的添加不捕获 4 var findemail4 = /^[a-z0-9]+(?:[_-.][a-z0-9]+)*@[a-z0-9]+(?:[_-.][a-z0-9]+)*\.[a-z]{2,4}$/i;
URL地址
由协议:\\(可省略)主机名(:端口号,一般省略)/路径几个部分组成
1 //先只考虑http和https这两个协议 2 var findurl1 = /^(https?:\/\/)?([^:\/]+)(:\d+)?(\/.*)?$/;
主机名实际上是多个以.分隔开的字符串组成的,其中可以有数字、字母、下划线、连字符等,但是不可以以连字符开头/结尾
1 //只针对主机名来写一个正则 2 var hostnamefind = /[a-z0-9]|[a-z0-9][-a-z0-9]*[a-z0-9]/i; 3 //让主机名匹配详细,最后的部分可用穷举 4 var hostnamefind2 = /^([a-z0-9]\.|[a-z0-9][-a-z0-9]*[a-z0-9]\.)*(com|edu|gov|net|org|[a-z]{2}+)$/; 5 //不穷举,可简单把最后的com等用若干个英文字母代替 6 var hostnamefind3 = /^([a-z0-9]\.|[a-z0-9][-a-z0-9]*[a-z0-9]\.)*([a-z]+)$/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号