
第二次作业
一、项目地址
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 400 | 1800 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 10 |
| · Design Spec | · 生成设计文档 | 110 | 160 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 50 | 260 |
| · Coding | · 具体编码 | 105 | 600 |
| · Code Review | · 代码复审 | 80 | 300 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 140 | 600 |
| Reporting | 报告 | 100 | 260 |
| · Test Repor | · 测试报告 | 50 | 100 |
| · Size Measurement | · 计算工作量 | 30 | 100 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| | 合计 | 610|2180
三、解题思路
(1)实现基本功能
- 统计文件字符的个数
先将文件扫描进来,接着判断是不是字符或者数字,是的话记为true,不是的话记为false。 - 统计文件的单词总数
按行读入文件,用正则找出单词,进行统计 - 统计文件的有效行数
tmp局部变量用来区分是不是一个空行,接着统计行数。 - 统计文件中各单词的出现次数,最终只输出频率最高的10个
先建立结构体存储单词以及单词出现的次数,然后用冒泡对其进行排序,再改变单词的先后顺序,最后按字典排序。 - 按照字典序输出到文件result.txt
先进行字典排序,再用ofstream输出到文档中
(2)接口封装
在实现基本功能的过程中已经构建了各种的类和函数,只要对其进行相应的封装就行了
四、设计实现过程
因为需要实现多种不同的功能以及接口的封装,所以实际上我构建了三个函数,一个结构体,三个函数是用来解决上面的基本功能的函数之所以比较少是因为在函数的内部已经用相应的比较暴力办法解决了一部分问题。我的办法比较偏向于暴力,所以流程图我并没有没有画。
改进程序性能
(1)文件的读取与读出
原先没看到要用cmd输入,所以就直接使用了
···
//const char mInputFileName = "1.txt";
···
后来发现错了就用了
···
int main(int argc, char argv[])
···
读出原先也没意识到,后来使用了
···
ofstream outfile;
outfile.open("result.txt");
int z ;
for (z = 0; z < num; z++)
{
outfile << w[z].word ;
}
outfile.close();
···
(2)统计单词数
原先是使用非常暴力的,就是直接遇到符号或者空格就加一个单词,后来发现误差太大,就换成了正则来统计单词
(3)单词的输出
字符串是不能直接复制,所以我构建了结构体,然后是使用了一个宏才可以
···
define _CRT_SECURE_NO_WARNINGS
···
五、性能分析图
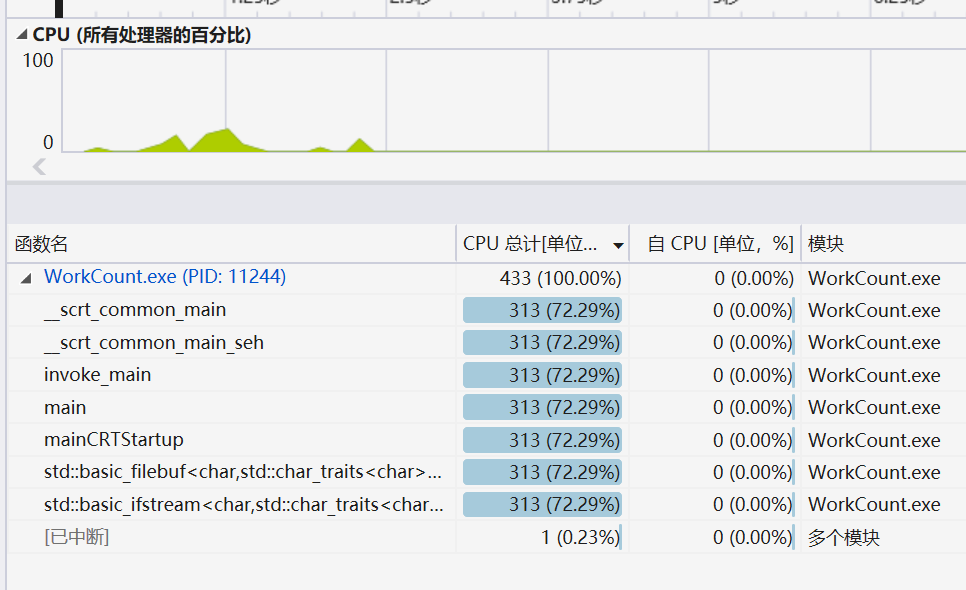
main函数的消耗最大
六、关键代码分析
···
void display_map(map<string, int> &wmap);
/**
*function:统计文本中每个单词出现的次数
/
int main(int argc, char argv[]) {
char filename[256];
//int cnt[3] = { 0 };
//const char *mInputFileName = "1.txt";
ifstream ifs(argv[1]);
string mStrTemp;
map<string, int> mCountMap;
//按行读入文件,用正则找出单词,进行统计
regex regWordPattern("[a-zA-Z]+");//单词的正则式:1)\w+:包含数字 2)[a-zA-Z]:只含字母
while (getline(ifs, mStrTemp))
{//逐行读入
const std::sregex_token_iterator end;
for (sregex_token_iterator wordIter(mStrTemp.begin(), mStrTemp.end(), regWordPattern); wordIter != end; wordIter++)
{//在一行文本中逐个找出单词
//cout<<*wordIter<<endl;//每个单词
mCountMap[*wordIter]++;//单词计数
}
}
//cout << "please input your filename:" << endl; //输入要统计的文本的绝对路径
//cin.getline(filename, 256);
fstream outfile(argv[1], ios::in);
count(outfile, cnt);
cout << "characters: " << cnt[0] << endl;
cout << "words:";
display_map(mCountMap);
//cout << "lines:" << cnt[2] << endl;
outfile.close();
system("pause");
return 0;
system("pause");
return 0;
return 1;
}
struct ww
{
char word[20];
int number;
}w[1000];
void display_map(map<string, int> &wmap)
{
map<string, int>::const_iterator map_it;
int i, j, num = 0;
int t = 0;
int tt = 0, ttt, x = 0;
char cc[20];
for (map_it = wmap.begin(); map_it != wmap.end(); map_it++)
{
num += map_it->second;
strcpy(w[t].word, (map_it->first).c_str());
w[t].number = map_it->second;
t++;
}
ttt = t - 2;
for (j = tt; j < ttt; j++)
{
for (i = 0; i < ttt - j; i++)
{
if (w[i].number < w[i + 1].number)
{
x = w[i].number; w[i].number = w[i + 1].number; w[i + 1].number = x;
strcpy(cc, w[i].word);
strcpy(w[i].word, w[i + 1].word);
strcpy(w[i + 1].word, cc);
}
}
}
cout << num << endl;
cout << "lines :" << cnt[2] << endl;
for (j = tt; j < 10; j++)
{
cout << w[j].word << ":" << w[j].number << endl;
}
ofstream outfile;
outfile.open("result.txt");
int z ;
for (z = 0; z < num; z++)
{
outfile << w[z].word ;
}
outfile.close();
}
···
以上为主函数以及基本功能的代码
个人体会
本次的实验感觉很麻烦,不过也有学会到许多的东西,例如如何读取文档,如何输出到文档上面,
如何使用各种的函数,以及各种头文件的作用,顺带着温习以前的知识。不过最重要的是学会了
如何分析问题,解决问题,这对于我来说其实要比知道怎么去打代码要重要一些。

