

yolov3训练自己的数据
前沿
最近在用目标检测方面的项目,所选择的算法是yolov3(该算法的优点是:既有速度也有精度)。由于自己在实现该算法的时候遇到了不少坑,所以结合自己在该过程中遇到的问题以及对应解决思路整理一下,让需要的人可以少走些弯路,节约时间。
总体来说,可分为四步进行操作:1.标注数据(我的上一篇博客已有详细介绍) ;2.制作自己的数据集;3.下载并编译源码;4.修改参数文件;5.在操作环境下进行运行(我在LINUX环境进行的)
1.标注工具
使用的工具是LabelImg,由于YOLOV3的label标注的一行五个数分别代表类别:编号,BoundingBox 中心 X 坐标,中心 Y 坐标,宽,高。这些坐标都是 0~1 的相对坐标。由于该标注工具默认生成.xml文件属性,这时我们可以通过LabelImg修改生成文件属性。点击如下红框可直接生成yolov3算法需求的文件(.txt)
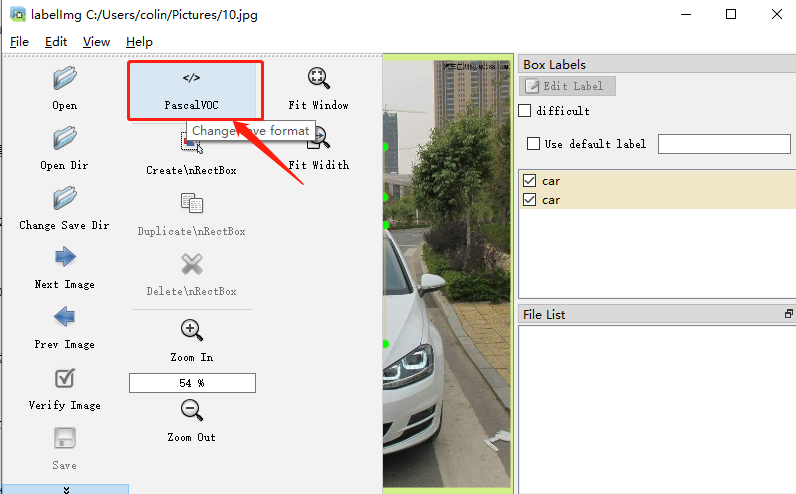
2.数据集编号
import os def rename(file_path): """ 遍历文件并且进行重命名 :param file_path:文件的路径(绝对) :return: """ filelist = os.listdir(file_path) total_num = len(filelist) i = 1 for item in filelist: # if item.endswith('.jpg'): if item.endswith('.txt'): src = os.path.join(os.path.abspath(file_path), item) str1 = str(i) # dst = os.path.join(os.path.abspath(file_path), str1.zfill(6) + '.jpg') # str1.zfill(x),x为一共几位数,用0补齐,如001000 dst = os.path.join(os.path.abspath(file_path), str1.zfill(6) + '.txt') # str1.zfill(x),x为一共几位数,用0补齐,如001000 try: os.rename(src, dst) print('converting %s to %s ...' % (src, dst)) i = i + 1 except: continue # file_path = 'D:\\ImageLabel\\TargetData\\output\\' # .jpg图片的存储路径 file_path = 'D:\\ImageLabel\\SaveTxt' # .txt图片的存储路径 rename(file_path)
执行上述代码,可生成对应文件重命名。为了规划自己的数据,减少出错的可能性,最好自己先给自己的图片编一个合理的序号,比如0001~0999。
3.数据标注
利用软件把自己的数据标注好。每一个图片名对应的有一个相应名字的.txt结果如下所示:


二.制作自己的数据集
在目录下新建VOC2007,并在VOC2007下新建labels,ImageSets和JPEGImages三个文件夹。在ImageSets下新建Main文件夹。文件目录如下所示:
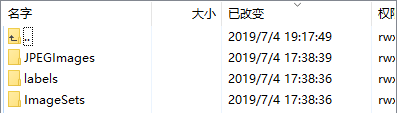
其中数据集图片(.jpg)拷贝到JPEGImages目录下,数据集(.txt)文件拷贝到labels目录下.在VOC2007下新建test.py文件夹,将下面代码拷贝进去运行
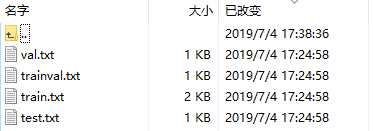
import os import random trainval_percent = 0.1 train_percent = 0.9 xmlfilepath = 'Annotations' txtsavepath = 'ImageSets\Main' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') fval = open('ImageSets/Main/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()
将生成四个文件:
三.下载并编译源码
1.下载代码
git clone https://github.com/pjreddie/darknet
2.编译代码
YOLOV3使用一个开源的神经网络框架Darknet53,使用C和CUDA,有CPU和GPU两种模式。默认使用的是CPU模式,需要切换GPU模型的话,vim修改Makefile文件。
cd darknet
如果使用GPU模式,则需要修改Makefile文件
vim Makefile
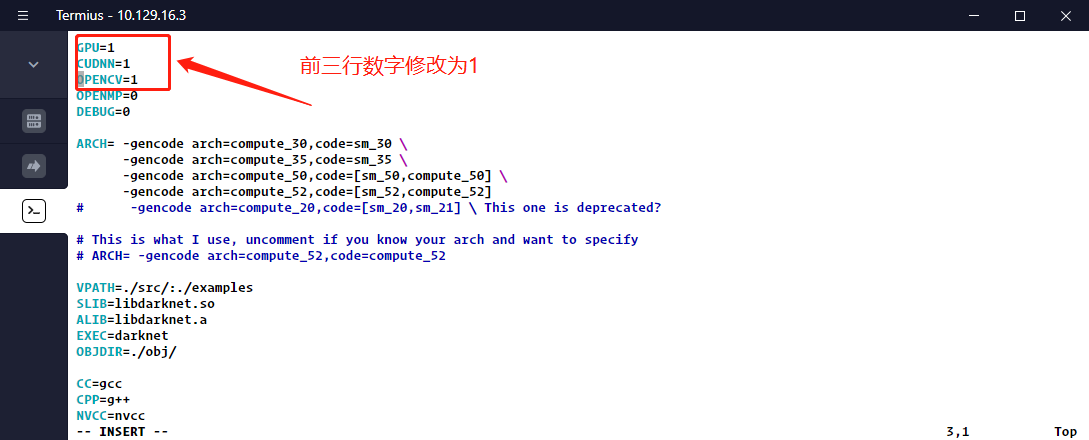
make # 进行编译
编译成功后,可以先下载预训练模型测试一下效果。
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
到这里,YOLOV3已经走通了,接下来只需要加入自己的数据就OK了。
3.加入训练集
在代码的darknet目录下新建VOCdevkit文件夹,然后把刚才制作的VOC2007文件夹拷贝到该文件夹下。
然后在VOC2007同级目录下添加gather_all_image.py,代码如下:
import os #paths=['coco2014','Stanford','vehicleplate'] paths=['VOC2007'] f=open('hour_hand.txt', 'w') for path in paths: p=os.path.abspath(path)+'/JPEGImages' filenames=os.listdir(p) for filename in filenames: im_path=p+'/'+filename print(im_path) f.write(im_path+'\n') f.close()
运行gather_all_image.py文件后会生成hour_hand.txt,内容如下:

四.修改参数文件
1.修改darknet/cfg/voc.data

2.修改darknet/data/voc.names和coco.names
打开对应的文件都是原本数据集里的类,改成自己的类就行

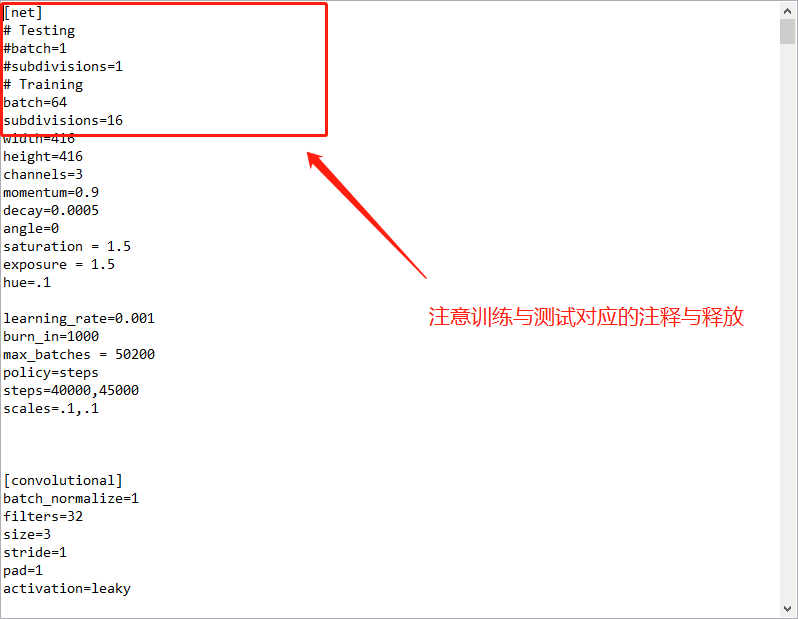
3.修改参数文件darknet/cfg/yolov3.cfg
参数文件开头的地方可以选训练的batchsize,要注意!
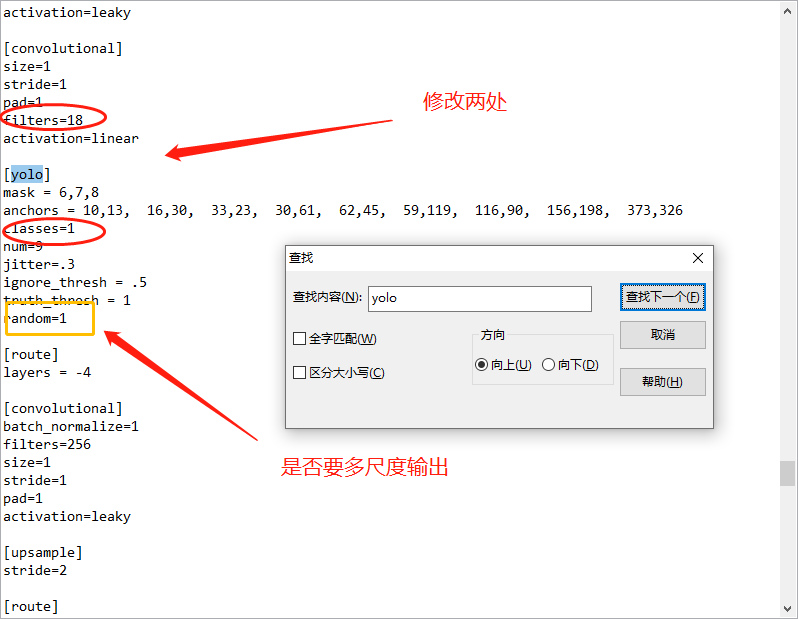
ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。 每个地方都必须要改2处, filters=3*(5+len(classes)); 其中:classes: len(classes) = 1,该测试是以hour hand单个类do为例:filters = 18 classes = 1
可修改:random = 1:原来是1,显存小改为0.
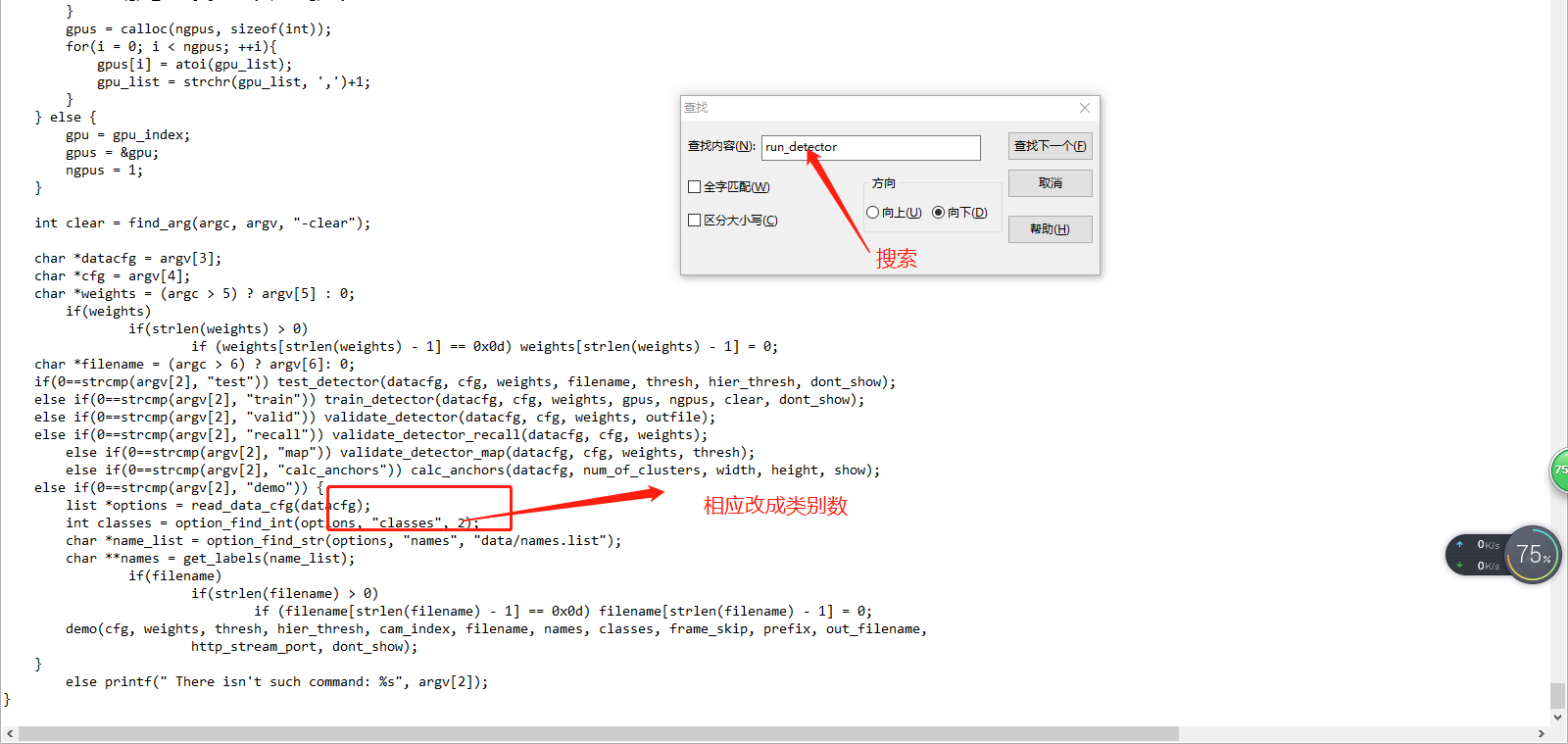
4.修改类别数
五.启动训练
1.下载darknet53的预训练模型
wget https://pjreddie.com/media/files/darknet53.conv.74
2.开始训练
./darknet detector train cfg/voc.data cfg/yolov3.cfg darknet53.conv.74
3.后续会总结YOLOv3训练过程中重要参数的理解和输出参数的含义

