

Python--基本的对象类型(字符串_不可变的数据类型)
1.1.4字符串
Python中的字符串也是一种对象类型,用str表示,通常用单引号或者双引号包裹起来(多行字符串通常用三重引号表示),可以用type()查看对象类型。
--"abc"
--"""qwer"""
--'asd'
--'''zxc'''(注意多行注释也是3重单引号)
1.1.4.1字符串的连接和复制
--用 + 来连接两个字符串(注意:用 + 连接的两个对象必须是同一类型)
--用*来复制一个字符串(注意:不能将字符串复制小数次)

1.1.4.2转义字符和原始字符串
--当字符串中有特殊符号时,需要用到转义字符;
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
--原始字符串是指字符串里面的每个字符都是原始含义,由r开头引起的字符串就是原始字符串。

1.1.4.3切片和索引
--切片和索引适用于序列(列表、元组、字典、集合)
--索引:用下标来表示字符串中个每个元素(python中下标从0开始),用index()函数来查找字符串中元素的索引

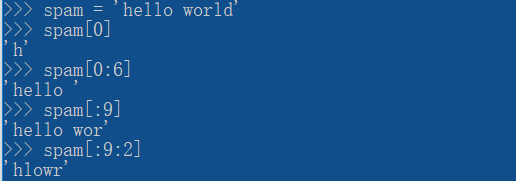
--切片:通过下标来获取整体或者部分的字符串(注意切片的读取顺序),切片得到的字符串并不改变原字符串(根本原因是字符串为不可变对象)
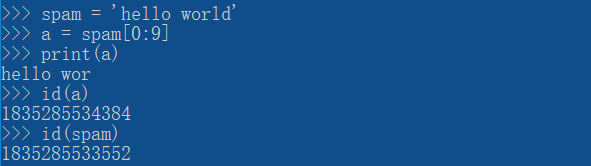
注意:序列的切片完整表示为 seq[start:end:step],start是开始的索引,如果为空就表示从第一个元素开始;end是结束的索引,如果为空就表示到末尾;step是步长,如果为空就表示步长为1。
1.1.4.4字符串的基本操作
字符串也是一种序列,序列都有以下操作。
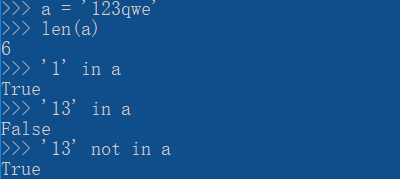
--len() 求序列的长度,返回值默认为int
--+ 连接两个序列
--* 重复序列元素
--in 判断元素是否在序列中(not in ),注意判断的元素必须为连续元素
--max 返回最大值,顺序为ASCII中的顺序
--min 返回最小值
--ord()得到一个字符所对应的的ASCII的数字编码
--chr()得到数字对应的字符编码

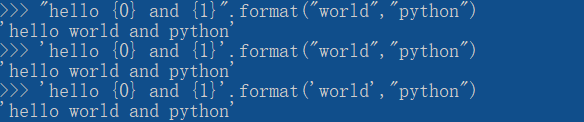
1.1.4.5字符串的格式化输出
--作用:使得输出内容具有连续性和可读性。可以使用format()方法来对字符串进行格式化输出,可以用dir(str)查看字符串的其他方法;help(str.format)可以查看具体用法。
dir()函数:不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表

1.1.4.5字符串的常用方法
--基本方法如下:


#字符串的常用方法 交互式模式下可以用dir(str)查看 print(dir(str)) # 1:首字母大写 # test = "qwerdf" # a = test.capitalize() #将字符串的首字母变为大写 # print(a) #2:元素变小写 # test = "qWErfΓ" # a = test.casefold() #对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用casefold()方法 # b = test.lower() #lower()方法只对ASCII编码,就是‘A-Z’有效, # print(a,b) #3:字符串填充以及对齐 # test = "qwerdf" # a = test.center(10,"啊") #设置宽度以及填充符并将字符串居中 # b = test.ljust(15,"@") #左对齐字符串并用填充符填充 # c = test.rjust(20,"%") #右对齐字符串并用填充符填充 # d = test.zfill(25) #右对齐字符串并用0作为填充符填充 # print(a) # print(b) # print(c) # print(d) #4:在字符串中寻找子字符串出现的次数 # test = "qwerdfqwerzxcv" # a = test.count("er",2,15) #传入的两个参数分别为字符串中的始末下标 # print(a) #5:判断字符串及其子字符串的开头和结尾是否为特定字符 # test = "qwerdf" # a = test.startswith("qw",0,8) #判断字符串的开始字符 # b = test.endswith("df",1,3) #判断字符串的结束字符 # print(a,b) #6:将字符串中的制表符\t转为空格,可以用来格式化输出 # test = "username\tpassword\temail\nqingyu\t12345678\tqingyu@qq.com" # a = test.expandtabs(20) #按照传入的值进行断句,将\t和之前的字符串加起来等于20 # print(a) #7:查找元素 # test = "qwerdf" # a = test.find("q",1,5) #获取元素的下标,若元素不存在字符串中返回值为-1,反之为其索引 # a1 = test.rfind("f") # b = test.index("q",0,5) #获取元素的下标,若元素不存在字符串中则报错,反之为其索引 # b1 = test.rindex("q") # print(a,b) #8:格式化字符串 # a = "my name is {0},i am{1} old" # b = "my name is {name},i am{age} old" #可以以变量名来格式化 # c = {"name": "qingyu", "age": 20} #针对字典类型的使用format_map()方法 # print(a.format("qingyu","20")) # print(b.format(name = "qingyu",age = "20")) # print("my name is {name},i am{age} old".format_map(c)) #9:判断字符串组成 # a = "qwerdf123" # b = "汉字qwe" # c = " " # d = "123" # e = "三四五123" # f = "①123" # print(a.isalnum()) #字符串中是否只由含字母(汉字)和数字组成,一个汉字占3个字节,占一个字符 # print(b.isalpha()) #字符串中是否只由含字母(汉字)组成 # print(c.isspace()) #字符串中是否只由空格组成 # print(d.isdecimal()) #字符串中是否只由十进制数字组成 # print(e.isnumeric()) #字符串中是否只由数字字符组成 # print(f.isdigit()) #字符串中是否只由数字组成 #10:字符串中是否存在不可显示的字符,\t制表符,\n换行符 # test = "oiuas\tdfkj" # a = test.isprintable() # print(a) #11:判断字符串是否是标题格式,将字符串转换为标题格式 # test = "i am a student" # a = test.istitle() #判断字符串是否是标题格式 # print(a) # b = test.title() #将字符串转换为标题格式 # print(b) # c = b.istitle() # print(c) #12:判断字符串是否全部是大小写,将字符串转换为大小写 # test = "qingyu" # a = test.islower() #断字符串是否全部是小写 # b = test.lower() #将字符串转换为小写 # print(a,b) # c = test.isupper() #断字符串是否全部是大写 # d = test.upper() #将字符串转换为大写 # print(c,d) #13:将字符串中的每一个元素按照指定分隔符进行拼接 # test = "qwerdf" # a = "*".join(test) # print(a,type(a)) #14:使用字符串中的元素来分割字符串,返回字符串中单词的列表 # test1 = "qwer1234asdf1234adxf1adff35134" # a = test1.split("w") #默认分割完全(会拿掉分割的元素) # b = test1.split("1",3) #3表示分割次数,即就是分割成3+1个元素的列表,默认分割顺序为由左到右 # print(a,b) # c = test1.rsplit("1") #分割顺序为从右到左 # print(c) # test2 = "qwrrd\n213211\n213214" # d = test2.splitlines() #默认不显示保留换行符 # e = test2.splitlines(True) #按照换行符来分割,参数为True则显示保留换行符 # f = test2.splitlines(False) # print(d,e,f) #15: # test = "qwer1234asdf1234adxf1adff35134" # a = test.partition("f") #按照指定字符分割,若能分割则分割为3部分(保留分割元素) # b = test.rpartition("f") #从末尾开始分割 # print(a,b) #16:移除字符串中的特定字符串(空格也是字符串) # test = " qwerdf " # a = test.strip() #1:移除空白,\t,\n # print(a) # print(test) # test1 = "qwerdf" # b = test1.strip("qwdf") #2:删除字符串开头和结尾指定qwdf的字符 # c = test1.lstrip("qwdf") #2:从左到右移除特定字符,优先最多匹配(删除开头) # d = test1.rstrip("exrdf") #2:从右到左移除特定字符,优先最多匹配(删除结尾) # print(b) # print(c,d) #17:按照对应关系替换相应字符串 # test1 = "qwerdf" # test2 = "123456" # m = str.maketrans(test1,test2) #创建对应关系 # test = "reassytvxqf7qeqeqteihoqweqwesaaqerdft" # a = test.translate(m) #按照对应关系进行替换 # print(a) #18:大小写转换 # test1 = "QWERdf" # test2 = "qwerDF" # print(test1.swapcase()) # print(test2.swapcase()) #19:查看字符串是否是标识符 符合数字,字母,下划线就是标识符 # import keyword # print(keyword.kwlist) # test = "a123" # print(test.isidentifier()) #20:替换字符串 # test = "123qwe456w3qrwt344314" # a1 = test.replace("3","999") #默认参数为-1,即就是替换字符串中所有满足要求的元素 # print(a1) # a2 = test.replace("3","999",2) #将默认参数设置为指定值,可以替换指定次数 # print(a2) 字符串的基本方法
--字符串一旦创建,不可修改;一旦修改或者拼接,都会重新生成新字符串
--字符串常用方法如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- #1:元素变小写 # test = "qWErfΓ" # a = test.casefold() #对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用casefold()方法 # b = test.lower() #lower()方法只对ASCII编码,就是‘A-Z’有效, # print(a,b) #2:字符串填充以及对齐 # test = "qwerdf" # a = test.center(10,"啊") #设置宽度以及填充符并将字符串居中 # b = test.ljust(15,"@") #左对齐字符串并用填充符填充 # c = test.rjust(20,"%") #右对齐字符串并用填充符填充 # d = test.zfill(25) #右对齐字符串并用0作为填充符填充 # print(a) # print(b) # print(c) # print(d) #3:查找元素 # test = "qwerdf" # a = test.find("q",1,5) #获取元素的下标,若元素不存在字符串中返回值为-1,反之为其索引 # a1 = test.rfind("f") # b = test.index("q",0,5) #获取元素的下标,若元素不存在字符串中则报错,反之为其索引 # b1 = test.rindex("q") # print(a,b) #4:格式化字符串 # a = "my name is {0},i am{1} old" # b = "my name is {name},i am{age} old" #可以以变量名来格式化 # c = {"name": "qingyu", "age": 20} #针对字典类型的使用format_map()方法 # print(a.format("qingyu","20")) # print(b.format(name = "qingyu",age = "20")) # print("my name is {name},i am{age} old".format_map(c)) #5:判断字符串是否全部是大小写,将字符串转换为大小写 # test = "qingyu" # a = test.islower() #断字符串是否全部是小写 # b = test.lower() #将字符串转换为小写 # print(a,b) # c = test.isupper() #断字符串是否全部是大写 # d = test.upper() #将字符串转换为大写 # print(c,d) #6:将字符串中的每一个元素按照指定分隔符进行拼接 # test = "qwerdf" # a = "*".join(test) # print(a,type(a)) #7:使用字符串中的元素来分割字符串,返回字符串中单词的列表 # test1 = "qwer1234asdf1234adxf1adff35134" # a = test1.split("w") #默认分割完全(会拿掉分割的元素) # b = test1.split("1",3) #3表示分割次数,即就是分割成3+1个元素的列表,默认分割顺序为由左到右 # print(a,b) # c = test1.rsplit("1") #分割顺序为从右到左 # print(c) # test2 = "qwrrd\n213211\n213214" # d = test2.splitlines() #默认不显示保留换行符 # e = test2.splitlines(True) #按照换行符来分割,参数为True则显示保留换行符 # f = test2.splitlines(False) # print(d,e,f) #8:移除字符串中的特定字符串(空格也是字符串) # test = " qwerdf " # a = test.strip() #1:移除空白,\t,\n # print(a) # print(test) # test1 = "qwerdf" # b = test1.strip("qwdf") #2:删除字符串开头和结尾指定qwdf的字符 # c = test1.lstrip("qwdf") #2:从左到右移除特定字符,优先最多匹配(删除开头) # d = test1.rstrip("exrdf") #2:从右到左移除特定字符,优先最多匹配(删除结尾) # print(b) # print(c,d) #9:按照对应关系替换相应字符串 # test1 = "qwerdf" # test2 = "123456" # m = str.maketrans(test1,test2) #创建对应关系 # test = "reassytvxqf7qeqeqteihoqweqwesaaqerdft" # a = test.translate(m) #按照对应关系进行替换 # print(a) #10:替换字符串 # test = "123qwe456w3qrwt344314" # a1 = test.replace("3","999") #默认参数为-1,即就是替换字符串中所有满足要求的元素 # print(a1) # a2 = test.replace("3","999",2) #将默认参数设置为指定值,可以替换指定次数 # print(a2)
--注意事项如下:
#注意事项1:序列的的遍历可以用for循环实现 # test = "我爱你中国" # for a in test: # print(a) #注意事项2:range()用法是生成连续或者不连续但有规律的整数序列,按照开始,结束,步长来生成整数序列 # a = range(1,100,5) # print(a) #python3中只有在for中时才会创建序列,Python2中会直接创建 # for i in a: # print(i) #小练习:根据用户输入的值,输出每一个字符以及当前字符所在的索引位置 # user_word = input("请输入:") #input()返回值是str类型,len()返回值是int类型 # for i in range(len(user_word)): # print(user_word[i],i)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号