

4-3 非阻塞IO
非阻塞IO(non-blocking IO)
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
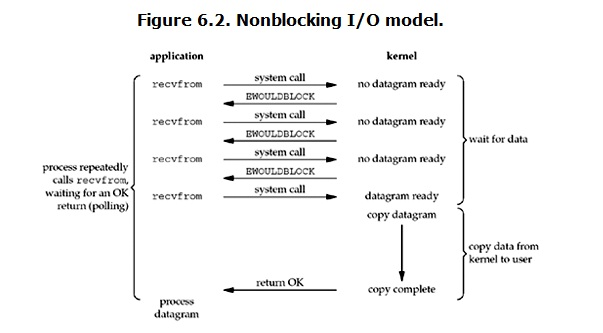
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,
此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,
循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,
进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
非阻塞IO示例
#服务端
from socket import *
server = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1',8099))
server.listen(5)
server.setblocking(False)
rlist=[]
wlist=[]
while True:
try:
conn, addr = server.accept()
rlist.append(conn)
print(rlist)
except BlockingIOError:
del_rlist=[]
for sock in rlist:
try:
data=sock.recv(1024)
if not data:
del_rlist.append(sock)
wlist.append((sock,data.upper()))
except BlockingIOError:
continue
except Exception:
sock.close()
del_rlist.append(sock)
del_wlist=[]
for item in wlist:
try:
sock = item[0]
data = item[1]
sock.send(data)
del_wlist.append(item)
except BlockingIOError:
pass
for item in del_wlist:
wlist.remove(item)
for sock in del_rlist:
rlist.remove(sock)
server.close()
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
但是非阻塞IO模型绝不被推荐。
我们不能否则其优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是也难掩其缺点:
1. 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
2. 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。
这会导致整体数据吞吐量的降低。
此外,在这个方案中recv()更多的是起到检测“操作是否完成”的作用,实际操作系统提供了更为高效的检测“操作是否完成“作用的接口,例如select()多路复用模式,可以一次检测多个连接是否活跃。

