

爬虫入门----爬取B站视频的弹幕和评论
声明:全过程没有任何违法操作
弹幕部分
本部分有两个方法介绍
直接在视频页加载的文件中爬取
首先打开《ELOG》S11世界赛特别篇:欢迎回家,然后F12打开资源管理器,在网络->Fetch/XHR中寻找文件(不要问我为什么,因为一般情况下数据文件可能会在这一栏出现),然后一个一个文件点,会发现这样一类文件的预览是一堆乱码
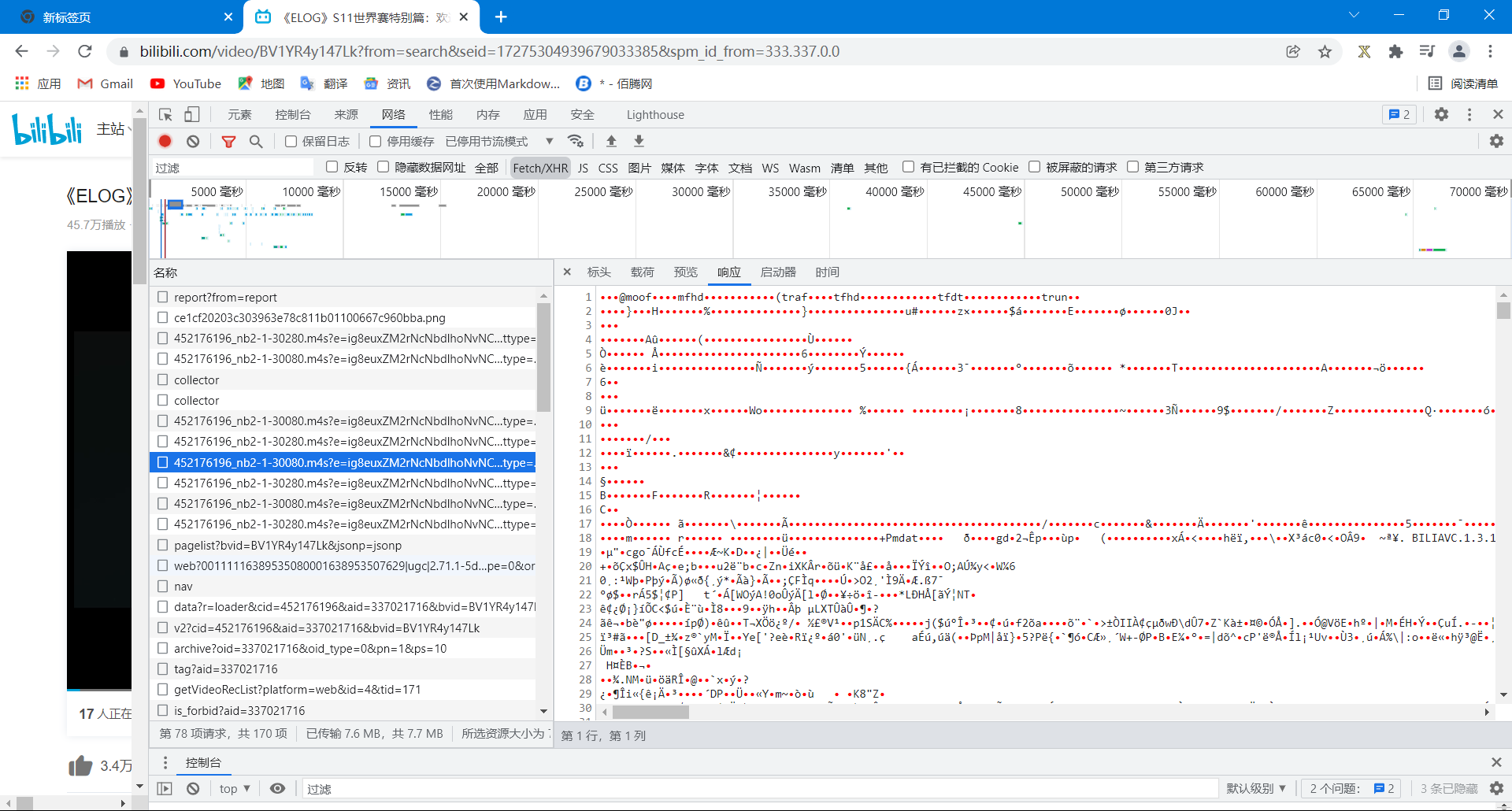
点开一看要么是不允许访问或者一个小视频框一直处于加载,所以判定这一类文件不是我们要寻找的。
然后我们再继续寻找,会发现一个seg.so开头的文件
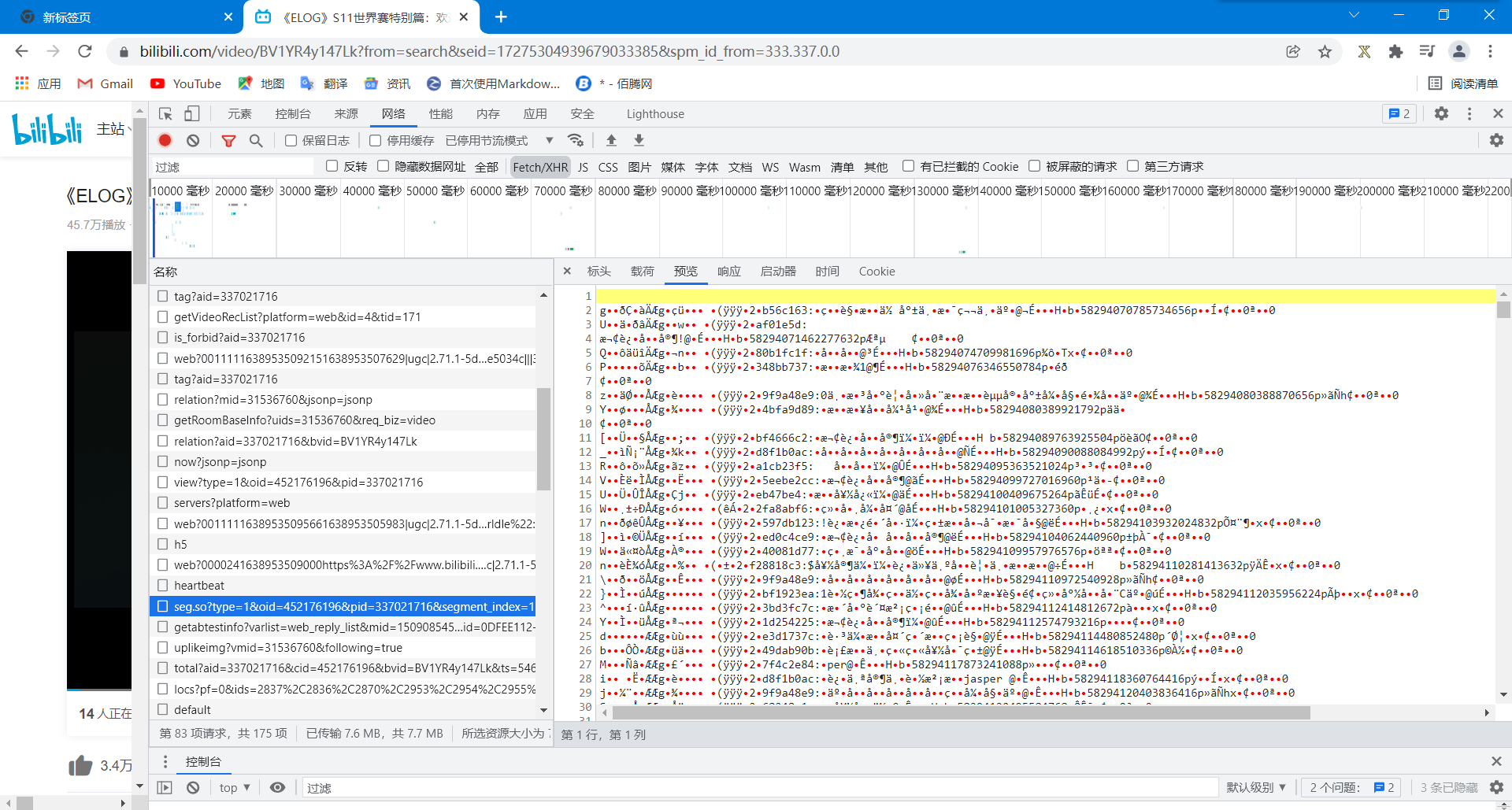
然后这又是一堆乱码,但是这次这个不一样了,因为你会发现后面的数字长度都差不多(可能是巧合),而且格式都差不多,多半这就是我们要寻找的文件,我们放在python中看看
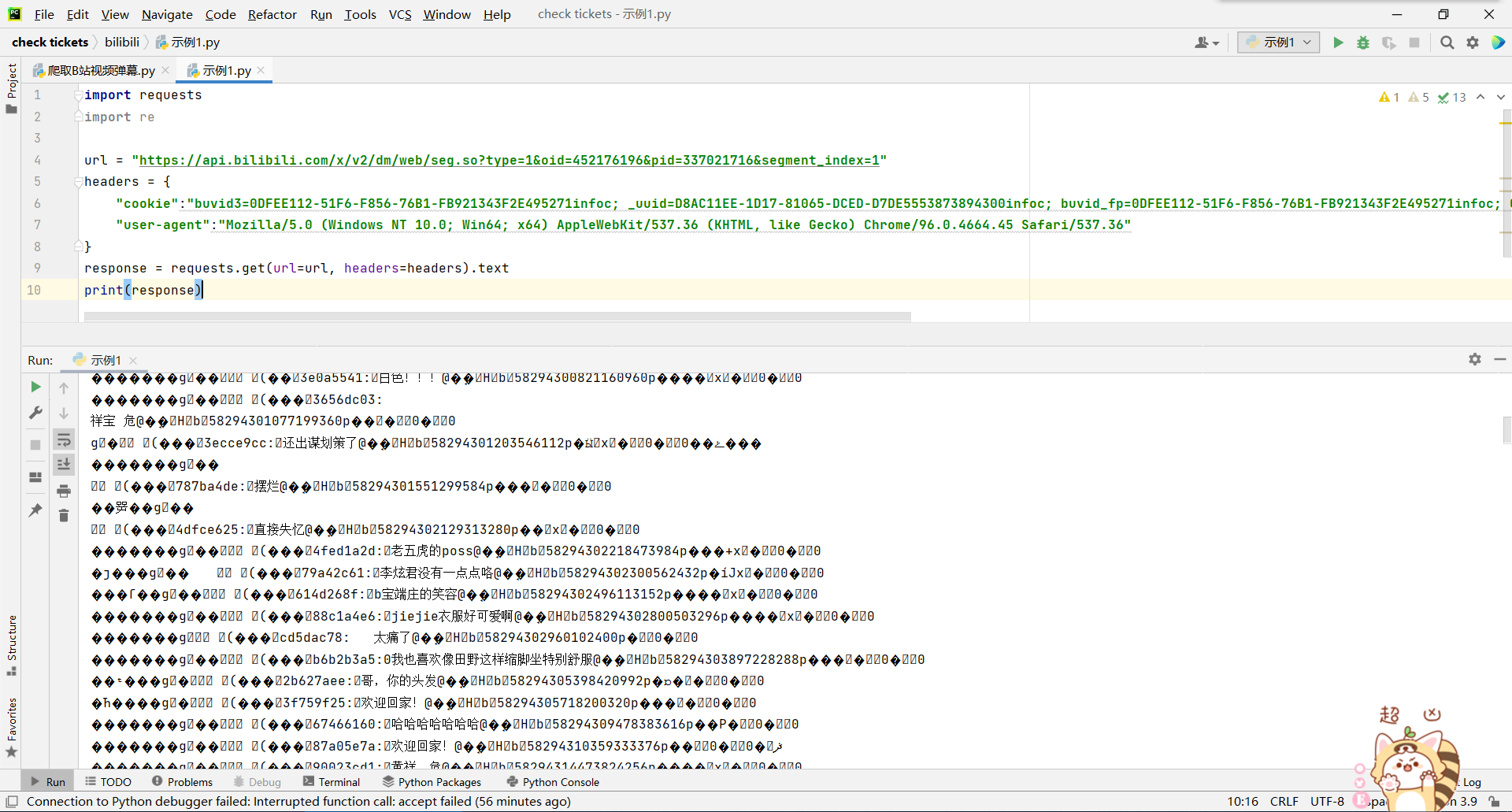
好家伙,果然是,但是中间除了弹幕中文内容,还有一堆看不懂的乱码,而且点开这个文件会闪退,说明不能用一般的方式处理,所以我们可以使用正则表达式提取其中的弹幕部分。
一下是代码设计(文件为:爬取B站视频弹幕.py)
import requests
import re
url = "https://api.bilibili.com/x/v2/dm/web/seg.so?type=1&oid=452176196&pid=337021716&segment_index=1"
#需要加申请头,注意字符串中出现有一些特殊符号需要保留需要加转义符号\
#cookie是用户信息
#user-agent是服务器申请
headers = {
"cookie":"buvid3=0DFEE112-51F6-F856-76B1-FB921343F2E495271infoc; _uuid=D8AC11EE-1D17-81065-DCED-D7DE5553873894300infoc; buvid_fp=0DFEE112-51F6-F856-76B1-FB921343F2E495271infoc; CURRENT_FNVAL=2000; blackside_state=1; rpdid=|(k|~umkuRR)0J'uYJ))lkm~m; PVID=1; b_lsid=D4C984EF_17D947274C1; sid=aox54cdj",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
response = requests.get(url=url, headers=headers).text
#利用正则表达式提取弹幕(Ctrl+F寻找匹配字段),.*?是通配符,可以匹配任意字符,从:开始到@前的内容都是需要的,()精确匹配
# #正则表达式提取的是一个列表
content_list = re.findall(':(.*?)@', response)
f = open('《ELOG》S11世界赛特别篇:欢迎回家视频弹幕', mode='w', encoding="utf-8") #模式a表示追加写入,而w只表示可写入,二者区别极大
for index in content_list:
content = index[1: ]
f.write(content)
f.write("\n")
f.close()
print("弹幕写入完成")
我们运行一下看看效果
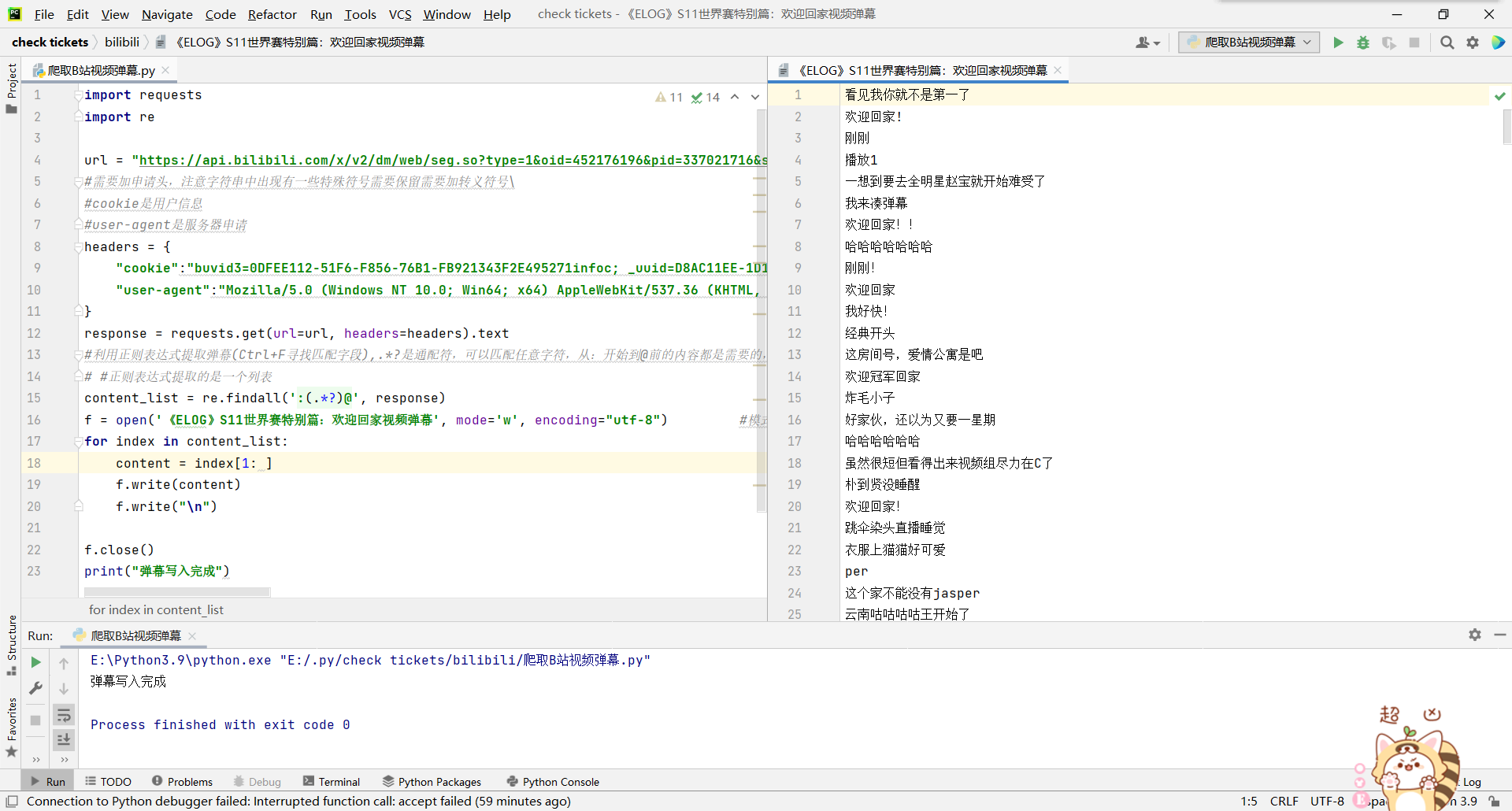
这就是在视频页加载的文件中直接爬到弹幕了
通过B站的api端口爬取弹幕并整理
为什么需要整理,请接着往下学习
在网址bilibili前加一个i,进入视频的api网址,如Flappy Bird-我把Flappy Bird改编成了分手模拟器
接下来可以进入弹幕地址,打开如下图
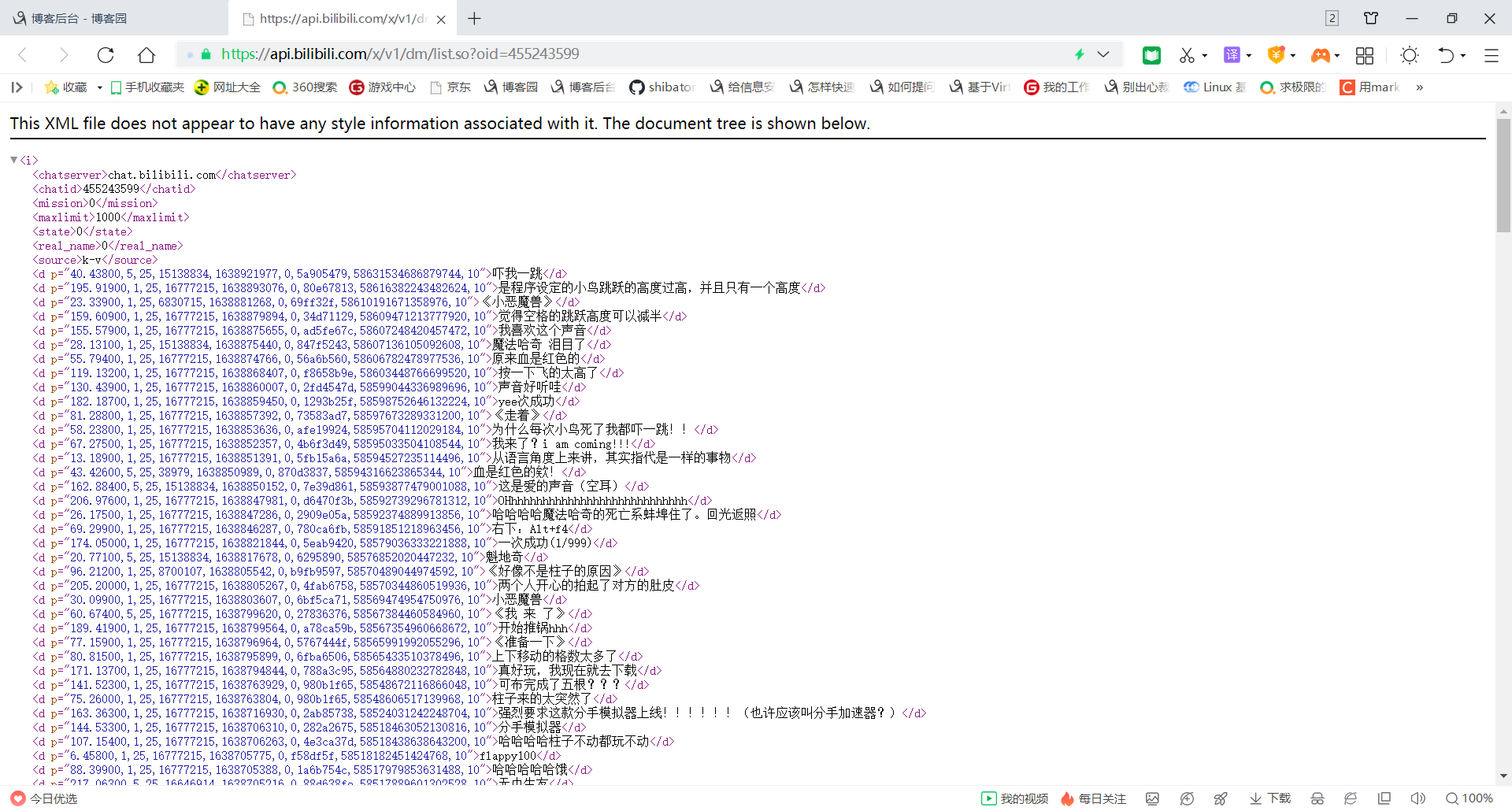
这就是弹幕内容了,然后我们可以先下载下来
# 下载文件(注意,要看清这个文件是什么格式,如果保存用.txt格式或是其他格式就会出现乱码)
def downloadfiles(url,count):
f = requests.get(url)
filename = str(count)+".so"
with open(filename,"wb") as code:
code.write(f.content)
print('文件下载成功!')
print('-----------')
当然,我们下载的.so文件是可以使用utf-8格式打开的,打开后里面的弹幕内容仍然是中文的,就不会出现乱码,如何正确的处理文件里的内容才是重要的。代码设计如下。
def calculatenum():
global endnum
f = open('E://.py/list.so', "r", encoding='utf-8')
lines = f.readlines()
for item in lines:
d = re.findall('>(.*?)<', item)
emptycontain = []
i = 0
for index in d:
emptycontain.append('{}'.format(i + 1) + index)
i += 1
print('列表中元素总数为:{}'.format(i))
print('------------------')
endnum = i - 2
def convert():
global endnum
ff = open('./弹幕文件.txt', "w", encoding='utf-8')
f = open('./弹幕源文件.so', "r", encoding='utf-8')
lines = f.readlines()
content = []
calculatenum()
for item in lines:
d = re.findall('>(.*?)<', item)
i = 16
while i <= endnum:
ff.write(d[i])
ff.write('\n')
content.append(d[i])
i += 2
else:
break
print('弹幕整理完成!')
解释一下这里为什么有一个calculatenum函数,这个函数是用来计算d列表中元素个数,因为正则表达式返回的内容类型为list类型,所以这一步必不可少,这也是重要的一个设计思路。
完整的代码如下
import re
import requests
def downloadfiles(url,count):
f = requests.get(url)
filename = str(count)+".so"
with open(filename,"wb") as code:
code.write(f.content)
print('文件下载成功!')
print('-----------')
def calculatenum():
global endnum
f = open('E://.py/list.so', "r", encoding='utf-8')
lines = f.readlines()
for item in lines:
d = re.findall('>(.*?)<', item)
emptycontain = []
i = 0
for index in d:
emptycontain.append('{}'.format(i + 1) + index)
i += 1
print('列表中元素总数为:{}'.format(i))
print('------------------')
endnum = i - 2
def convert():
global endnum
ff = open('./弹幕文件.txt', "w", encoding='utf-8')
f = open('./弹幕源文件.so', "r", encoding='utf-8')
lines = f.readlines()
content = []
calculatenum()
for item in lines:
d = re.findall('>(.*?)<', item)
i = 16
while i <= endnum:
ff.write(d[i])
ff.write('\n')
content.append(d[i])
i += 2
else:
break
print('弹幕整理完成!')
if __name__ == '__main__':
downloadfiles('https://api.bilibili.com/x/v1/dm/list.so?oid=455243599', '弹幕源文件')
convert()
我们运行一下看看
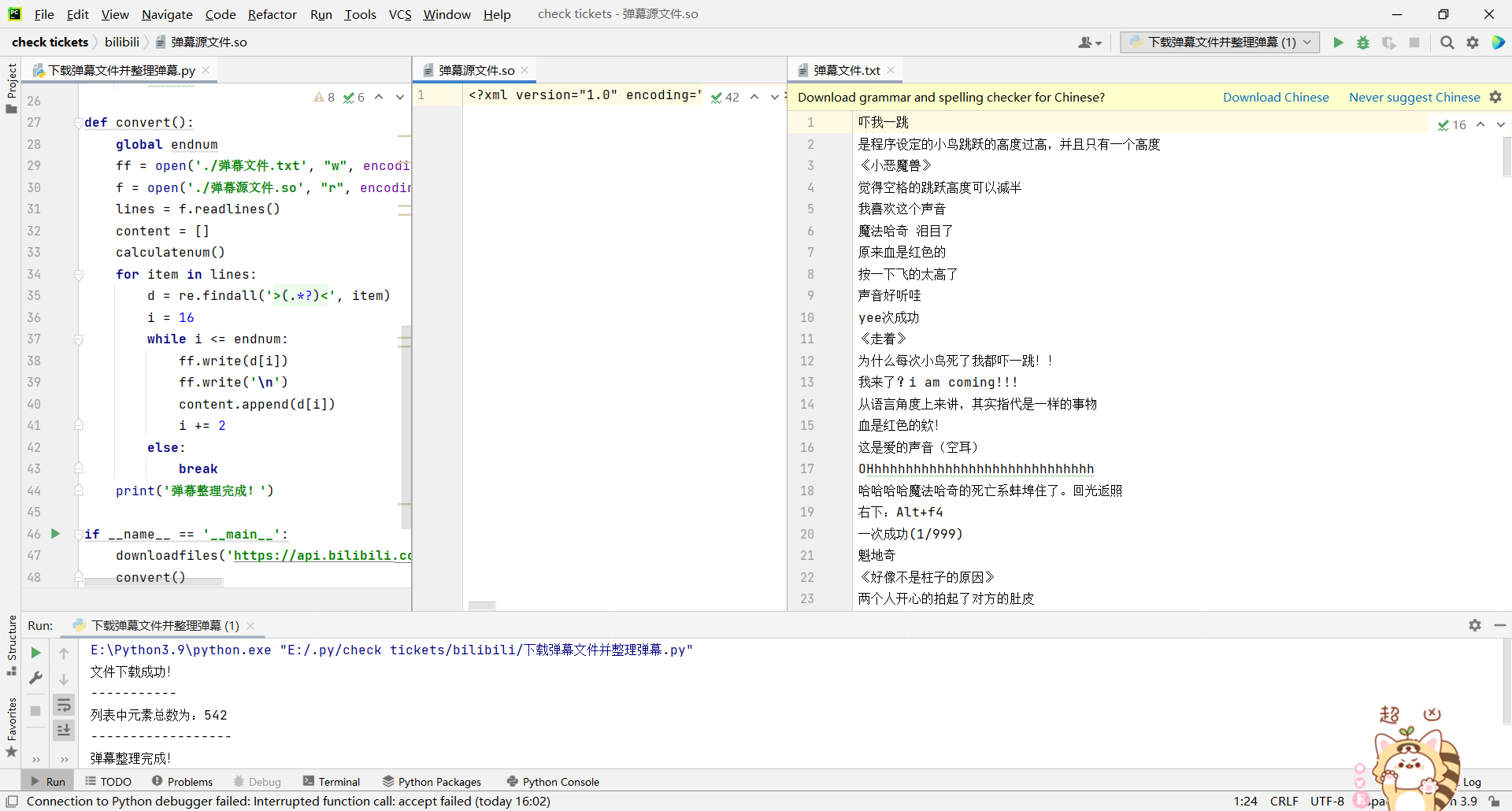
这样就从api端口中爬取到弹幕了
评论部分
评论部分就是一个比较难的,虽然以前有大佬爬过,但是他们的方法在现在就没有太大作用了,但是对我也有参考价值,废话不多说,看我如何处理。
当然,视频还是我把Flappy Bird改编成了分手模拟器,首先F12找文件,在网络->Fetch/XHR找啊找啊找,我发现一个问题,怎么找也没有对应的评论文件,说明存储评论的文件并不在这一栏,我们点开全部。这里我发现一个随评论刷新的一类文件(因为现在的B站评论不是以页显示的了,意思也就是说B站的评论是刷新的,动态的,说明一定有随评论刷新而增加的文件),也就是以main?开头的文件
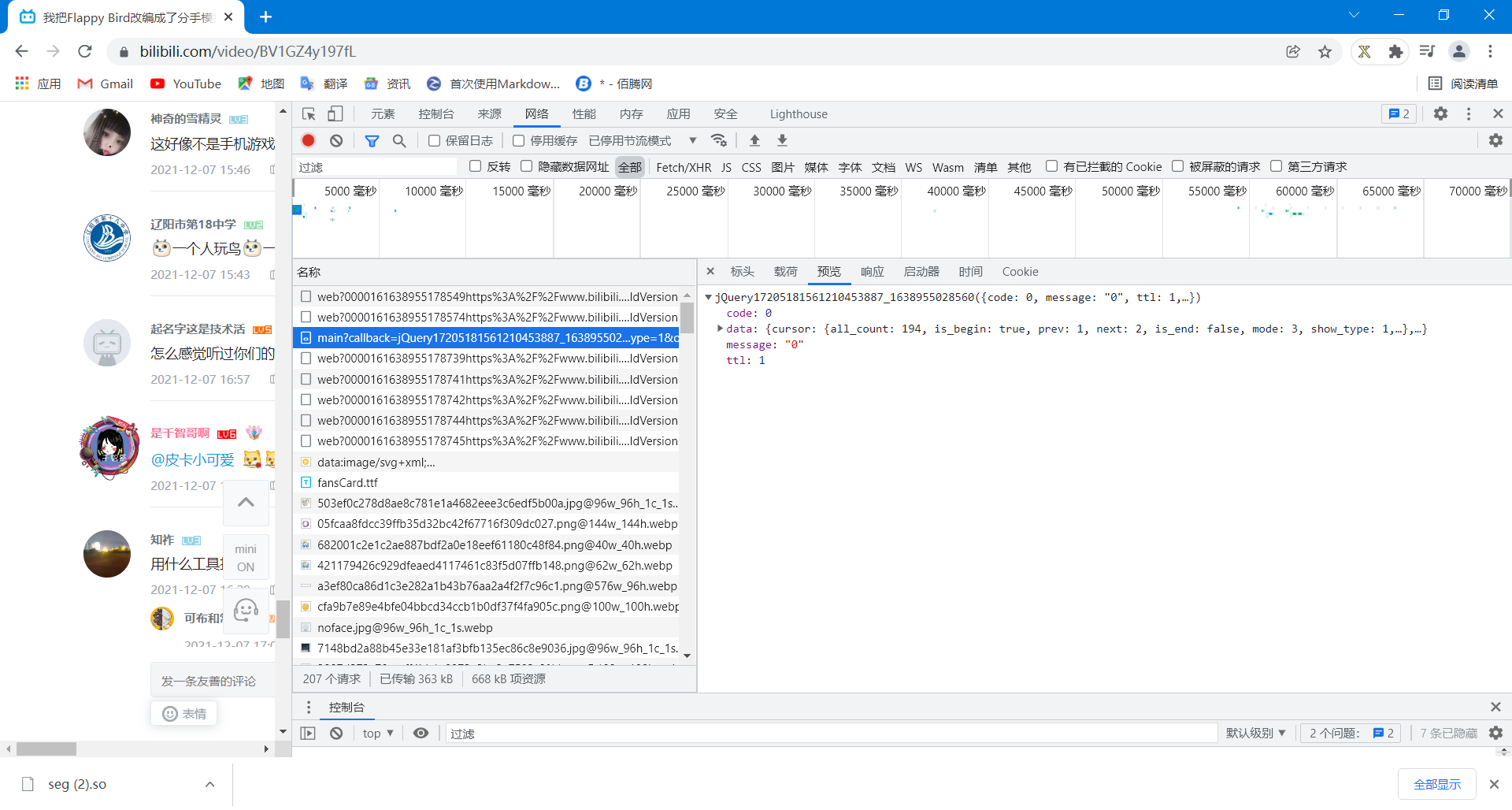
好巧不巧,我一打开数据,一路展开,找到了对应内容,说明评论就是装在这类文件里面的
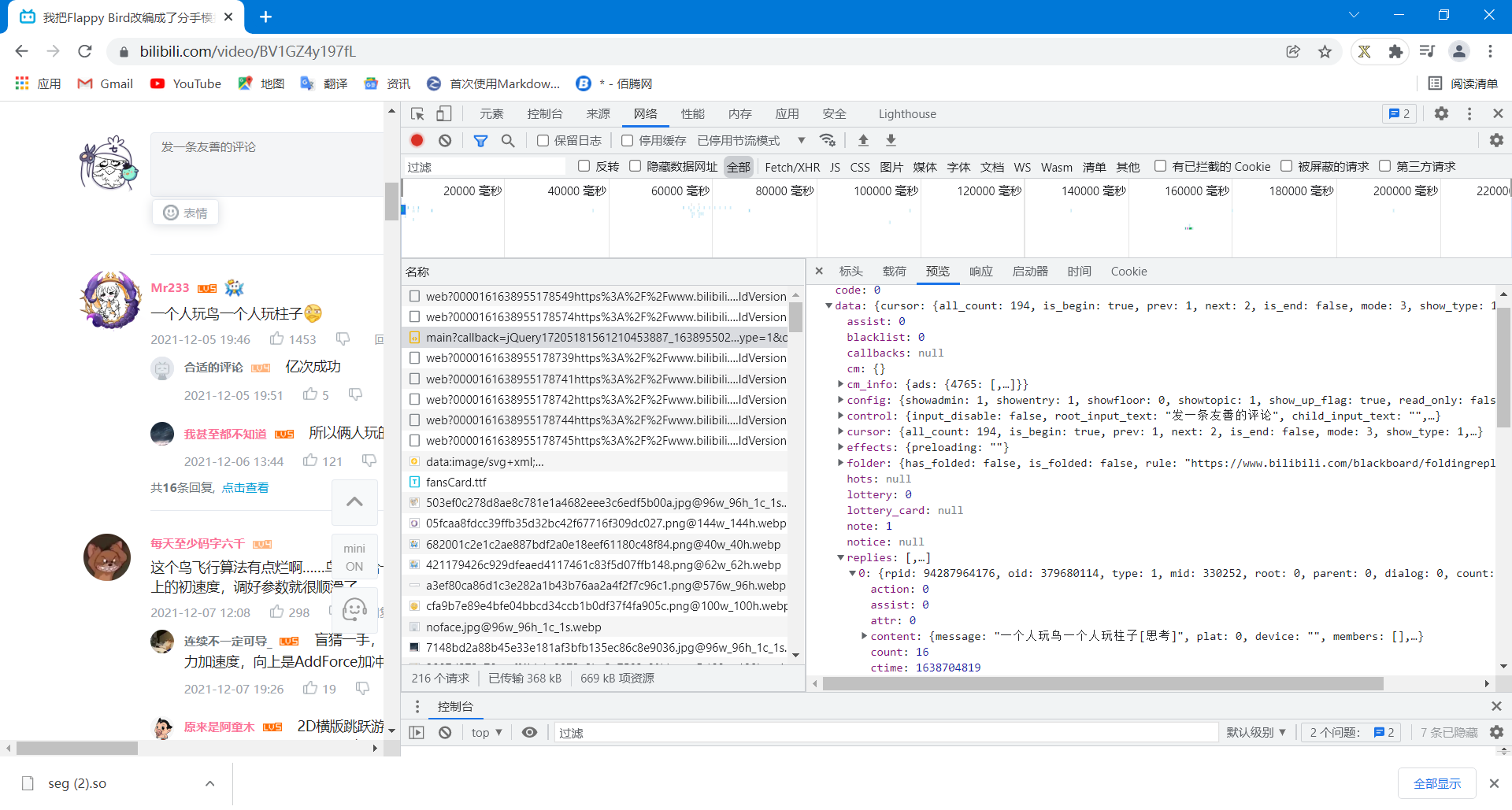
那么我们就需要设计程序爬取到里面的内容。
但是这个文件是用get方式就能得到的json文件(还记得我在爬取佰腾网中说过的吧,json文件返回的内容是python中的字典类型),因此一个get申请获取就ok了,至于如何去处理文件内的数据,就看自己的想法,这里我只想要爬取评论者和评论内容,所以设计就比较简单了。设计代码如下
import requests
f = open('我把Flappy Bird改编成了分手模拟器评论.txt', "w", encoding='utf-8')
f.write("我把Flappy Bird改编成了分手模拟器视频评论" + "\n")
f.write("\n")
def get():
url = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=379680114&mode=3&plat=1"
#需要加申请头,注意字符串中出现有一些特殊符号需要保留需要加转义符号\
#cookie是用户信息
#user-agent是服务器申请
headers = {
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'buvid3=0DFEE112-51F6-F856-76B1-FB921343F2E495271infoc; _uuid=D8AC11EE-1D17-81065-DCED-D7DE5553873894300infoc; buvid_fp=0DFEE112-51F6-F856-76B1-FB921343F2E495271infoc; CURRENT_FNVAL=2000; blackside_state=1; rpdid=|(k|~umkuRR)0J\'uYJ))lkm~m; sid=aox54cdj; fingerprint=5260c3f503ebc356d558c28d1a3972d9; buvid_fp_plain=3E450DFB-AFB9-62E8-E610-D184933E113454738infoc; DedeUserID=1509085458; DedeUserID__ckMd5=83f2d34217a80d8e; SESSDATA=4385026c,1654425909,7fca3*c1; bili_jct=74d249db78dc581cca66406e0f4a54a3; CURRENT_QUALITY=80; b_lsid=2C67E6D5_17D956A459F; PVID=3',
'referer': 'https://www.bilibili.com/video/BV1h3411b76L?spm_id_from=333.999.0.0',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
response = requests.get(url=url, headers=headers).json()
result = response['data']['replies']
try:
for item in result:
user = item['member']['uname']
comment = item['content']['message']
f.write(user)
f.write(":")
f.write(comment)
f.write("\n")
try:
for index in item['replies']:
f.write(" "+index['member']['uname'])
f.write(":")
f.write(index['content']['message'])
f.write("\n")
except(TypeError):
f.write("\n")
i = 1
while response['data']['cursor']['is_end'] == False:
i += 1
url1 = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=" + str(i) + "&type=1&oid=379680114&mode=3&plat=1"
response1 = requests.get(url=url1, headers=headers).json()
result1 = response1['data']['replies']
for item2 in result1:
user = item2['member']['uname']
comment = item2['content']['message']
f.write(user)
f.write(":")
f.write(comment)
f.write("\n")
try:
for index1 in item2['replies']:
f.write(" " + index1['member']['uname'])
f.write(":")
f.write(index1['content']['message'])
f.write("\n")
except(TypeError):
f.write("\n")
else:
print('程序停止')
except(TypeError):
print("程序停止")
get()
我们运行一下看看效果
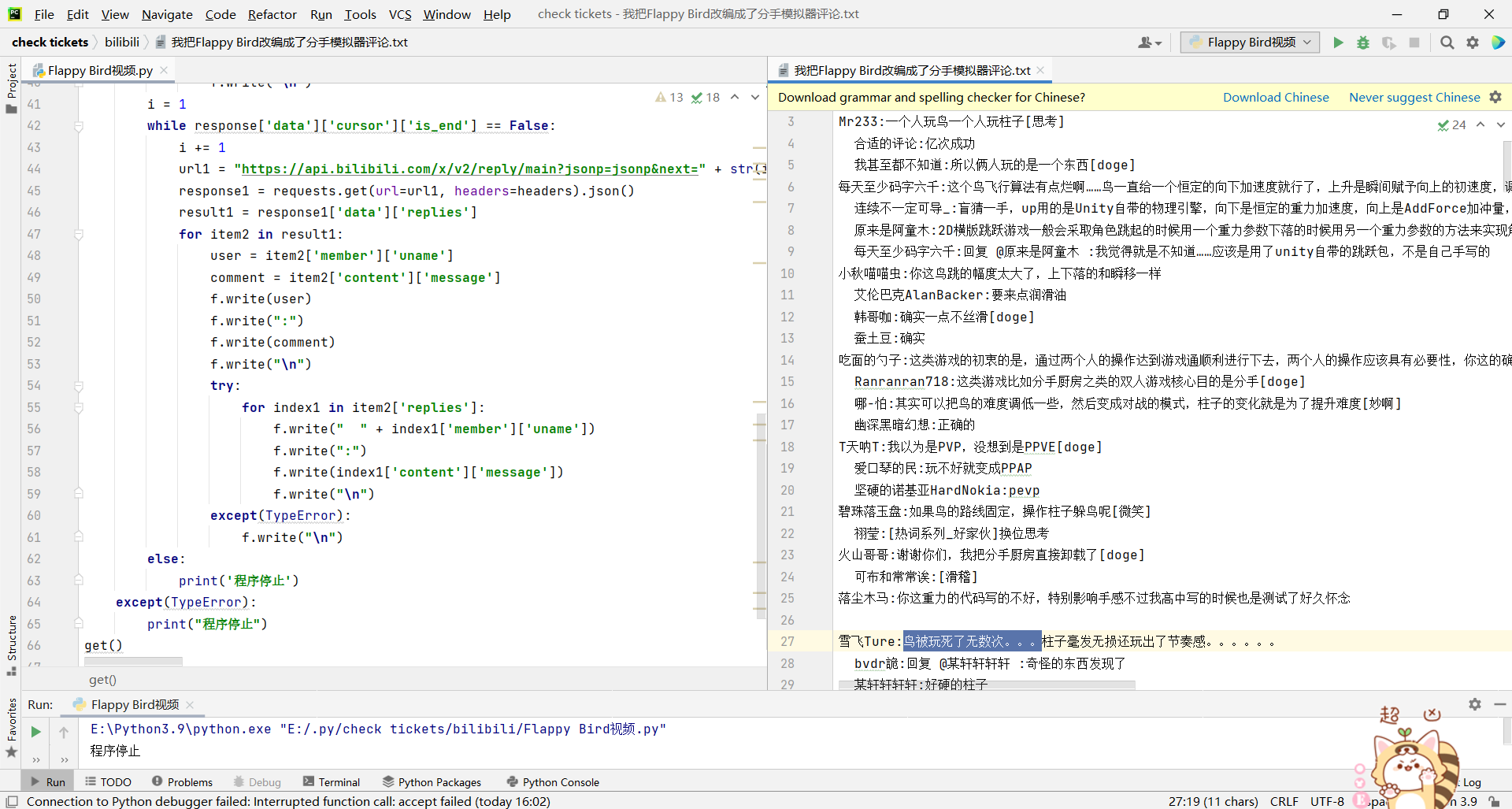
这就爬取到了B站视频的评论了(但是这里有个小缺陷,一个评论者一般会有5,6个回复者,这种方式也只能爬到最多3个评论者,原因我也不清楚)
总结
通过爬取B站的弹幕和视频,我们在这个过程用到了正则表达式,但是从这个过程中收获最大的还是程序设计的逻辑以及如何更好地处理问题。其实上面的代码通过一定的修改可以批量爬取弹幕和评论,这里读者们可以自己尝试设计一个批量爬取弹幕和视频的程序(一个小提示:获取某个up主的主页,通过爬取这个up主主页中视频(oid)号,然后进行批量生产url就可以达到批量爬取的目的)
